 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021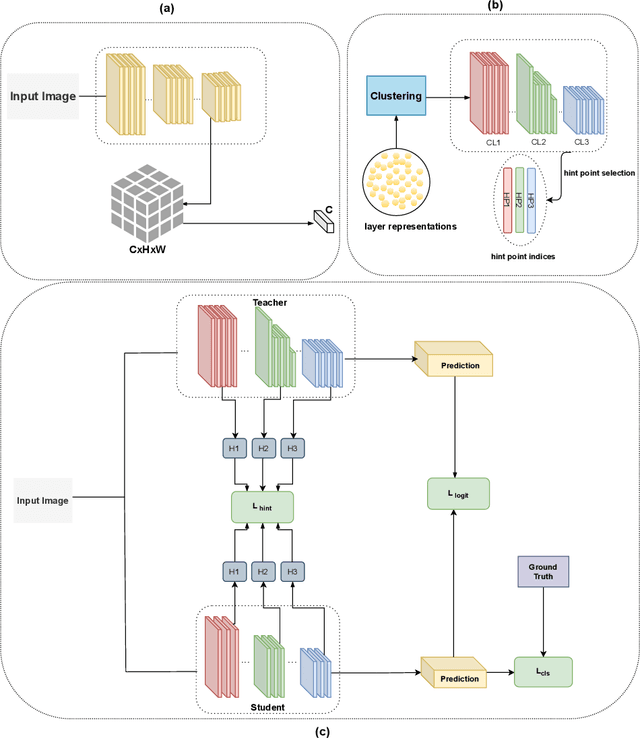
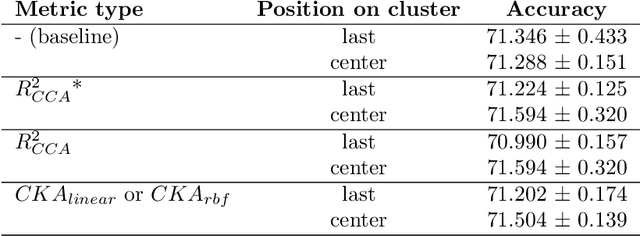
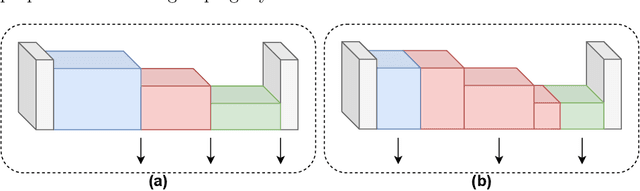
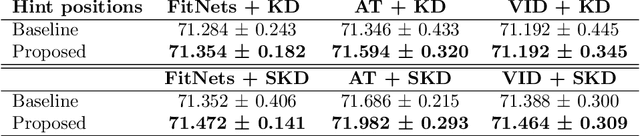
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
Exploring Factors for Improving Low Resolution Face Recognition
Jul 25, 2019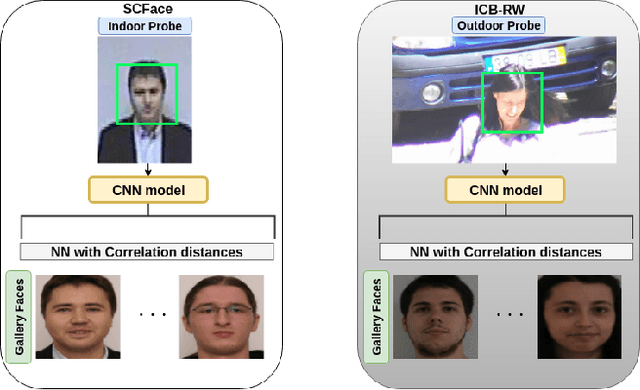
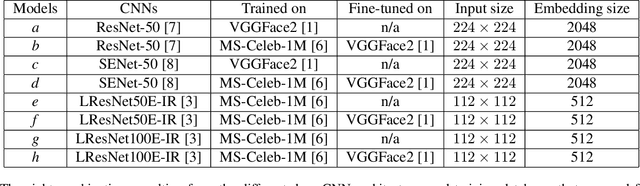

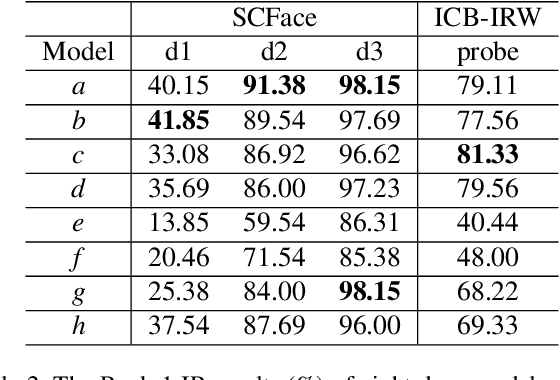
State-of-the-art deep face recognition approaches report near perfect performance on popular benchmarks, e.g., Labeled Faces in the Wild. However, their performance deteriorates significantly when they are applied on low quality images, such as those acquired by surveillance cameras. A further challenge for low resolution face recognition for surveillance applications is the matching of recorded low resolution probe face images with high resolution reference images, which could be the case in watchlist scenarios. In this paper, we have addressed these problems and investigated the factors that would contribute to the identification performance of the state-of-the-art deep face recognition models when they are applied to low resolution face recognition under mismatched conditions. We have observed that the following factors affect performance in a positive way: appearance variety and resolution distribution of the training dataset, resolution matching between the gallery and probe images, and the amount of information included in the probe images. By leveraging this information, we have utilized deep face models trained on MS-Celeb-1M and fine-tuned on VGGFace2 dataset and achieved state-of-the-art accuracies on the SCFace and ICB-RW benchmarks, even without using any training data from the datasets of these benchmarks.