 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork-Aware Bilinear Tokenization for Brain Functional Connectivity Representation Learning
May 13, 2026Masked autoencoders (MAEs) have recently shown promise for self-supervised representation learning of resting-state brain functional connectivity (FC). However, a fundamental question remains unresolved: how should FC matrices be tokenized to align with the intrinsic modular organization of large-scale brain networks? Existing approaches typically adopt region-centric or graph-based schemes that treat FC as structurally homogeneous elements and overlook the large-scale network brain organization. We introduce NERVE (Network-Aware Representations of Brain Functional Connectivity via Bilinear Tokenization), a self-supervised learning framework that redefines FC tokenization by partitioning FC matrices into patches of intra- and inter-network connectivity blocks. Unlike image-based MAE, where fixed-size patches share a common tokenizer, FC patches defined by network pairs are heterogeneous in size and correspond to distinct functional roles. To resolve this problem, NERVE embeds FC patches through a novel structured bilinear factorization. This formulation preserves network identity and reduces parameter complexity from quadratic to linear scaling in the number of networks. We evaluate NERVE across three large-scale developmental cohorts (ABCD, PNC, and CCNP) for behavior and psychopathology prediction. Compared to structurally agnostic MAE variants and graph-based self-supervised baselines, the proposed network-aware formulation yields more stable and transferable representations, particularly in cross-cohort evaluation. Ablation studies confirm that the proposed bilinear network embedding and anatomically grounded parcellation are critical for performance. These findings highlight the importance of incorporating domain-specific structural priors into self-supervised learning for functional connectomics.
Generative Modeling of Neurodegenerative Brain Anatomy with 4D Longitudinal Diffusion Model
Apr 24, 2026Understanding and predicting the progression of neurodegenerative diseases remains a major challenge in medical AI, with significant implications for early diagnosis, disease monitoring, and treatment planning. However, most available longitudinal neuroimaging datasets are temporally sparse with a few follow-up scans per subject. This scarcity of temporal data limits our ability to model and accurately capture the continuous anatomical changes related to disease progression in individual subjects. To address this problem, we propose a novel 4D (3DxT) diffusion-based generative framework that effectively models and synthesizes longitudinal brain anatomy over time, conditioned on available clinical variables such as health status, age, sex, and other relevant factors. Moreover, while most current approaches focus on manipulating image intensity or texture, our method explicitly learns the data distribution of topology-preserving spatiotemporal deformations to effectively capture the geometric changes of brain structures over time. This design enables the realistic generation of future anatomical states and the reconstruction of anatomically consistent disease trajectories, providing a more faithful representation of longitudinal brain changes. We validate our model through both synthetic sequence generation and downstream longitudinal disease classification, as well as brain segmentation. Experiments on two large-scale longitudinal neuroimage datasets demonstrate that our method outperforms state-of-the-art baselines in generating anatomically accurate, temporally consistent, and clinically meaningful brain trajectories. Our code is available on Github.
Anatomically Guided Latent Diffusion for Brain MRI Progression Modeling
Jan 21, 2026Accurately modeling longitudinal brain MRI progression is crucial for understanding neurodegenerative diseases and predicting individualized structural changes. Existing state-of-the-art approaches, such as Brain Latent Progression (BrLP), often use multi-stage training pipelines with auxiliary conditioning modules but suffer from architectural complexity, suboptimal use of conditional clinical covariates, and limited guarantees of anatomical consistency. We propose Anatomically Guided Latent Diffusion Model (AG-LDM), a segmentation-guided framework that enforces anatomically consistent progression while substantially simplifying the training pipeline. AG-LDM conditions latent diffusion by directly fusing baseline anatomy, noisy follow-up states, and clinical covariates at the input level, a strategy that avoids auxiliary control networks by learning a unified, end-to-end model that represents both anatomy and progression. A lightweight 3D tissue segmentation model (WarpSeg) provides explicit anatomical supervision during both autoencoder fine-tuning and diffusion model training, ensuring consistent brain tissue boundaries and morphometric fidelity. Experiments on 31,713 ADNI longitudinal pairs and zero-shot evaluation on OASIS-3 demonstrate that AG-LDM matches or surpasses more complex diffusion models, achieving state-of-the-art image quality and 15-20\% reduction in volumetric errors in generated images. AG-LDM also exhibits markedly stronger utilization of temporal and clinical covariates (up to 31.5x higher sensitivity than BrLP) and generates biologically plausible counterfactual trajectories, accurately capturing hallmarks of Alzheimer's progression such as limbic atrophy and ventricular expansion. These results highlight AG-LDM as an efficient, anatomically grounded framework for reliable brain MRI progression modeling.
Anatomical Similarity as a New Metric to Evaluate Brain Generative Models
Apr 30, 2025Generative models enhance neuroimaging through data augmentation, quality improvement, and rare condition studies. Despite advances in realistic synthetic MRIs, evaluations focus on texture and perception, lacking sensitivity to crucial anatomical fidelity. This study proposes a new metric, called WASABI (Wasserstein-Based Anatomical Brain Index), to assess the anatomical realism of synthetic brain MRIs. WASABI leverages \textit{SynthSeg}, a deep learning-based brain parcellation tool, to derive volumetric measures of brain regions in each MRI and uses the multivariate Wasserstein distance to compare distributions between real and synthetic anatomies. Based on controlled experiments on two real datasets and synthetic MRIs from five generative models, WASABI demonstrates higher sensitivity in quantifying anatomical discrepancies compared to traditional image-level metrics, even when synthetic images achieve near-perfect visual quality. Our findings advocate for shifting the evaluation paradigm beyond visual inspection and conventional metrics, emphasizing anatomical fidelity as a crucial benchmark for clinically meaningful brain MRI synthesis. Our code is available at https://github.com/BahramJafrasteh/wasabi-mri.
Mask-Guided Attention U-Net for Enhanced Neonatal Brain Extraction and Image Preprocessing
Jun 25, 2024



In this study, we introduce MGA-Net, a novel mask-guided attention neural network, which extends the U-net model for precision neonatal brain imaging. MGA-Net is designed to extract the brain from other structures and reconstruct high-quality brain images. The network employs a common encoder and two decoders: one for brain mask extraction and the other for brain region reconstruction. A key feature of MGA-Net is its high-level mask-guided attention module, which leverages features from the brain mask decoder to enhance image reconstruction. To enable the same encoder and decoder to process both MRI and ultrasound (US) images, MGA-Net integrates sinusoidal positional encoding. This encoding assigns distinct positional values to MRI and US images, allowing the model to effectively learn from both modalities. Consequently, features learned from a single modality can aid in learning a modality with less available data, such as US. We extensively validated the proposed MGA-Net on diverse datasets from varied clinical settings and neonatal age groups. The metrics used for assessment included the DICE similarity coefficient, recall, and accuracy for image segmentation; structural similarity for image reconstruction; and root mean squared error for total brain volume estimation from 3D ultrasound images. Our results demonstrate that MGA-Net significantly outperforms traditional methods, offering superior performance in brain extraction and segmentation while achieving high precision in image reconstruction and volumetric analysis. Thus, MGA-Net represents a robust and effective preprocessing tool for MRI and 3D ultrasound images, marking a significant advance in neuroimaging that enhances both research and clinical diagnostics in the neonatal period and beyond.
MELAGE: A purely python based Neuroimaging software (Neonatal)
Sep 12, 2023



MELAGE, a pioneering Python-based neuroimaging software, emerges as a versatile tool for the visualization, processing, and analysis of medical images. Initially conceived to address the unique challenges of processing 3D ultrasound and MRI brain images during the neonatal period, MELAGE exhibits remarkable adaptability, extending its utility to the domain of adult human brain imaging. At its core, MELAGE features a semi-automatic brain extraction tool empowered by a deep learning module, ensuring precise and efficient brain structure extraction from MRI and 3D Ultrasound data. Moreover, MELAGE offers a comprehensive suite of features, encompassing dynamic 3D visualization, accurate measurements, and interactive image segmentation. This transformative software holds immense promise for researchers and clinicians, offering streamlined image analysis, seamless integration with deep learning algorithms, and broad applicability in the realm of medical imaging.
Gaussian Processes for Missing Value Imputation
Apr 10, 2022
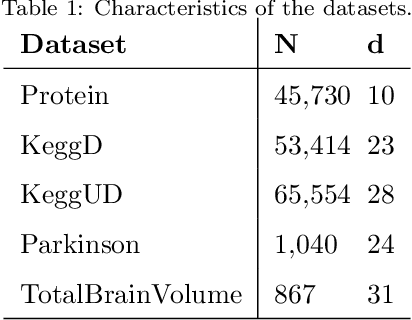
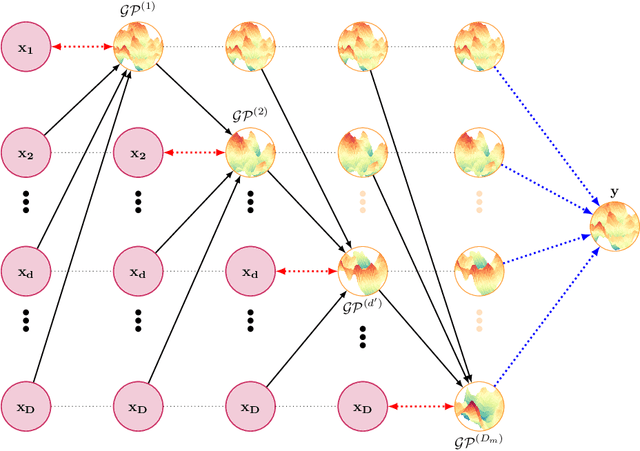
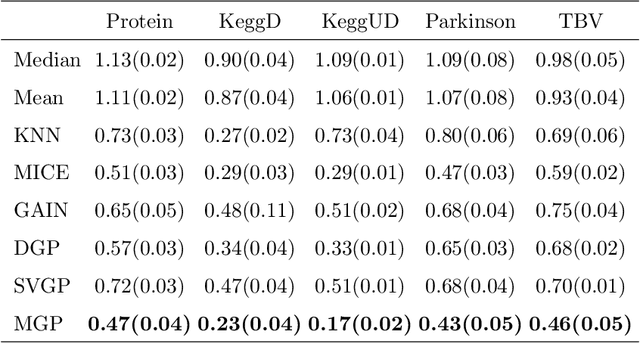
Missing values are common in many real-life datasets. However, most of the current machine learning methods can not handle missing values. This means that they should be imputed beforehand. Gaussian Processes (GPs) are non-parametric models with accurate uncertainty estimates that combined with sparse approximations and stochastic variational inference scale to large data sets. Sparse GPs can be used to compute a predictive distribution for missing data. Here, we present a hierarchical composition of sparse GPs that is used to predict missing values at each dimension using all the variables from the other dimensions. We call the approach missing GP (MGP). MGP can be trained simultaneously to impute all observed missing values. Specifically, it outputs a predictive distribution for each missing value that is then used in the imputation of other missing values. We evaluate MGP in one private clinical data set and four UCI datasets with a different percentage of missing values. We compare the performance of MGP with other state-of-the-art methods for imputing missing values, including variants based on sparse GPs and deep GPs. The results obtained show a significantly better performance of MGP.
Input Dependent Sparse Gaussian Processes
Jul 15, 2021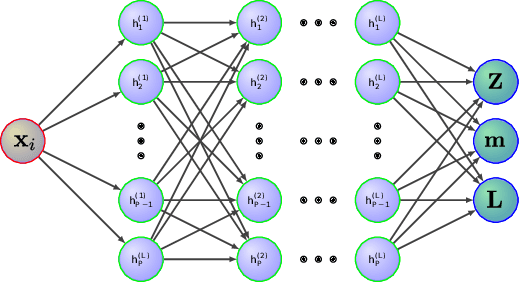


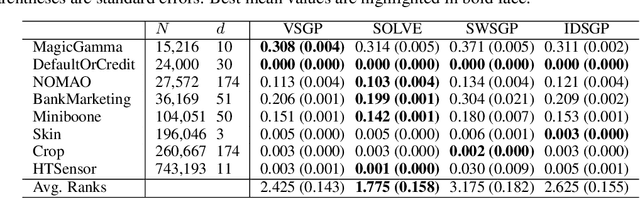
Gaussian Processes (GPs) are Bayesian models that provide uncertainty estimates associated to the predictions made. They are also very flexible due to their non-parametric nature. Nevertheless, GPs suffer from poor scalability as the number of training instances N increases. More precisely, they have a cubic cost with respect to $N$. To overcome this problem, sparse GP approximations are often used, where a set of $M \ll N$ inducing points is introduced during training. The location of the inducing points is learned by considering them as parameters of an approximate posterior distribution $q$. Sparse GPs, combined with variational inference for inferring $q$, reduce the training cost of GPs to $\mathcal{O}(M^3)$. Critically, the inducing points determine the flexibility of the model and they are often located in regions of the input space where the latent function changes. A limitation is, however, that for some learning tasks a large number of inducing points may be required to obtain a good prediction performance. To address this limitation, we propose here to amortize the computation of the inducing points locations, as well as the parameters of the variational posterior approximation q. For this, we use a neural network that receives the observed data as an input and outputs the inducing points locations and the parameters of $q$. We evaluate our method in several experiments, showing that it performs similar or better than other state-of-the-art sparse variational GP approaches. However, with our method the number of inducing points is reduced drastically due to their dependency on the input data. This makes our method scale to larger datasets and have faster training and prediction times.