 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Actor-Critics with Tight Risk Certificates
May 26, 2025After a period of research, deep actor-critic algorithms have reached a level where they influence our everyday lives. They serve as the driving force behind the continual improvement of large language models through user-collected feedback. However, their deployment in physical systems is not yet widely adopted, mainly because no validation scheme that quantifies their risk of malfunction. We demonstrate that it is possible to develop tight risk certificates for deep actor-critic algorithms that predict generalization performance from validation-time observations. Our key insight centers on the effectiveness of minimal evaluation data. Surprisingly, a small feasible of evaluation roll-outs collected from a pretrained policy suffices to produce accurate risk certificates when combined with a simple adaptation of PAC-Bayes theory. Specifically, we adopt a recently introduced recursive PAC-Bayes approach, which splits validation data into portions and recursively builds PAC-Bayes bounds on the excess loss of each portion's predictor, using the predictor from the previous portion as a data-informed prior. Our empirical results across multiple locomotion tasks and policy expertise levels demonstrate risk certificates that are tight enough to be considered for practical use.
Exploring Pessimism and Optimism Dynamics in Deep Reinforcement Learning
Jun 06, 2024Off-policy actor-critic algorithms have shown promise in deep reinforcement learning for continuous control tasks. Their success largely stems from leveraging pessimistic state-action value function updates, which effectively address function approximation errors and improve performance. However, such pessimism can lead to under-exploration, constraining the agent's ability to explore/refine its policies. Conversely, optimism can counteract under-exploration, but it also carries the risk of excessive risk-taking and poor convergence if not properly balanced. Based on these insights, we introduce Utility Soft Actor-Critic (USAC), a novel framework within the actor-critic paradigm that enables independent control over the degree of pessimism/optimism for both the actor and the critic via interpretable parameters. USAC adapts its exploration strategy based on the uncertainty of critics through a utility function that allows us to balance between pessimism and optimism separately. By going beyond binary choices of optimism and pessimism, USAC represents a significant step towards achieving balance within off-policy actor-critic algorithms. Our experiments across various continuous control problems show that the degree of pessimism or optimism depends on the nature of the task. Furthermore, we demonstrate that USAC can outperform state-of-the-art algorithms for appropriately configured pessimism/optimism parameters.
Probabilistic Actor-Critic: Learning to Explore with PAC-Bayes Uncertainty
Feb 05, 2024



We introduce Probabilistic Actor-Critic (PAC), a novel reinforcement learning algorithm with improved continuous control performance thanks to its ability to mitigate the exploration-exploitation trade-off. PAC achieves this by seamlessly integrating stochastic policies and critics, creating a dynamic synergy between the estimation of critic uncertainty and actor training. The key contribution of our PAC algorithm is that it explicitly models and infers epistemic uncertainty in the critic through Probably Approximately Correct-Bayesian (PAC-Bayes) analysis. This incorporation of critic uncertainty enables PAC to adapt its exploration strategy as it learns, guiding the actor's decision-making process. PAC compares favorably against fixed or pre-scheduled exploration schemes of the prior art. The synergy between stochastic policies and critics, guided by PAC-Bayes analysis, represents a fundamental step towards a more adaptive and effective exploration strategy in deep reinforcement learning. We report empirical evaluations demonstrating PAC's enhanced stability and improved performance over the state of the art in diverse continuous control problems.
PAC-Bayesian Soft Actor-Critic Learning
Jan 30, 2023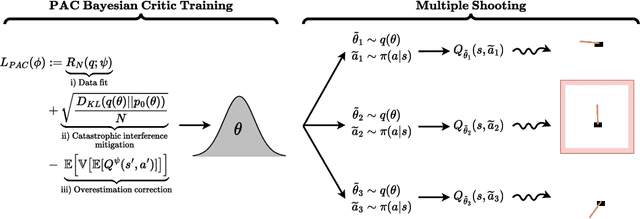

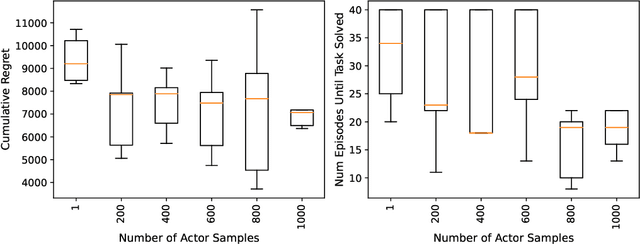

Actor-critic algorithms address the dual goals of reinforcement learning, policy evaluation and improvement, via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that the online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably to the state of the art on multiple classical control and locomotion tasks in both sample efficiency and asymptotic performance.