 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-Bayesian Soft Actor-Critic Learning
Jan 30, 2023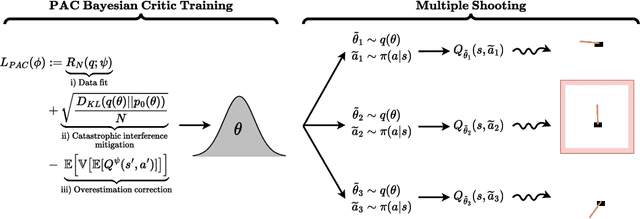

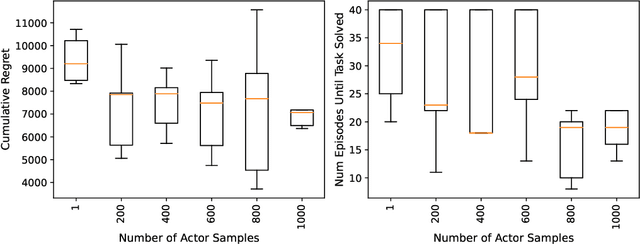

Actor-critic algorithms address the dual goals of reinforcement learning, policy evaluation and improvement, via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that the online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably to the state of the art on multiple classical control and locomotion tasks in both sample efficiency and asymptotic performance.