 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Searching in Scene Image and Video Frame in Multi-Script Scenario using Dynamic Shape Coding
Jul 30, 2018
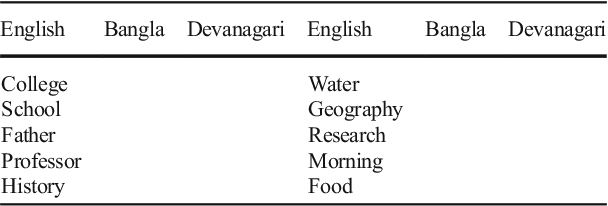
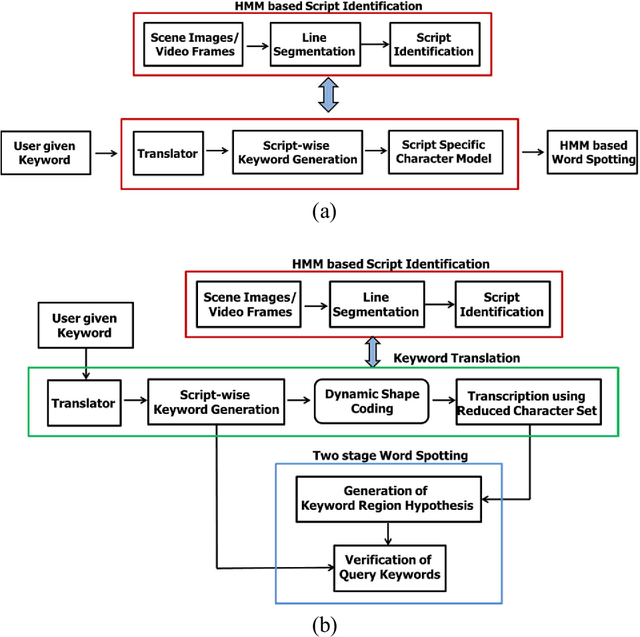
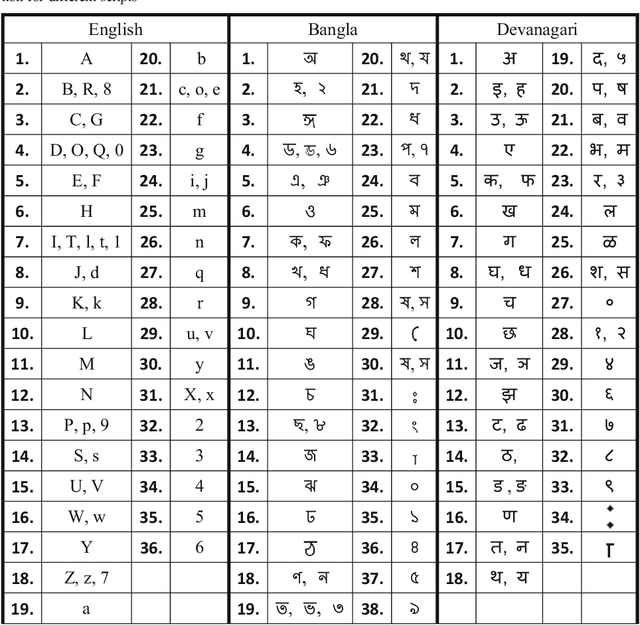
Retrieval of text information from natural scene images and video frames is a challenging task due to its inherent problems like complex character shapes, low resolution, background noise, etc. Available OCR systems often fail to retrieve such information in scene/video frames. Keyword spotting, an alternative way to retrieve information, performs efficient text searching in such scenarios. However, current word spotting techniques in scene/video images are script-specific and they are mainly developed for Latin script. This paper presents a novel word spotting framework using dynamic shape coding for text retrieval in natural scene image and video frames. The framework is designed to search query keyword from multiple scripts with the help of on-the-fly script-wise keyword generation for the corresponding script. We have used a two-stage word spotting approach using Hidden Markov Model (HMM) to detect the translated keyword in a given text line by identifying the script of the line. A novel unsupervised dynamic shape coding based scheme has been used to group similar shape characters to avoid confusion and to improve text alignment. Next, the hypotheses locations are verified to improve retrieval performance. To evaluate the proposed system for searching keyword from natural scene image and video frames, we have considered two popular Indic scripts such as Bangla (Bengali) and Devanagari along with English. Inspired by the zone-wise recognition approach in Indic scripts[1], zone-wise text information has been used to improve the traditional word spotting performance in Indic scripts. For our experiment, a dataset consisting of images of different scenes and video frames of English, Bangla and Devanagari scripts were considered. The results obtained showed the effectiveness of our proposed word spotting approach.
Local Neighborhood Intensity Pattern: A new texture feature descriptor for image retrieval
Jul 02, 2018
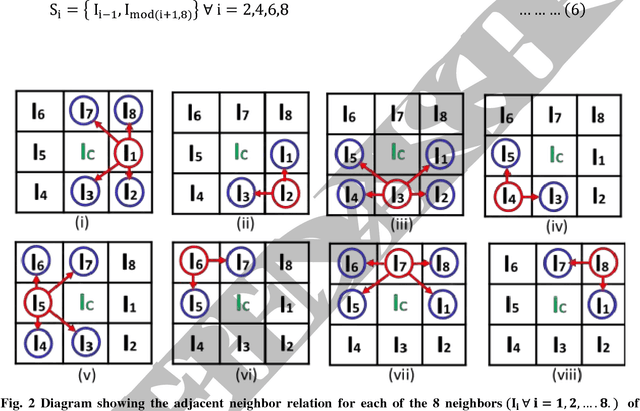
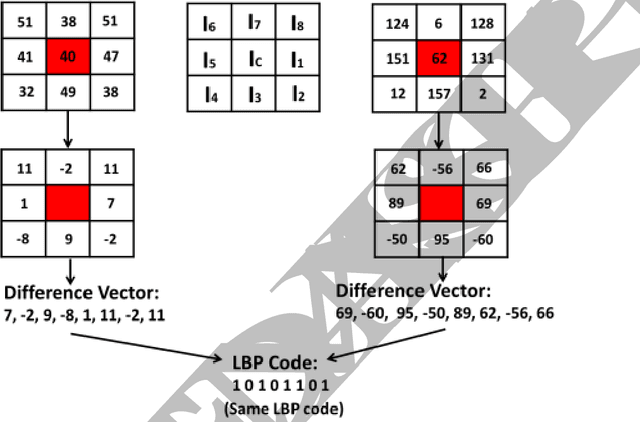
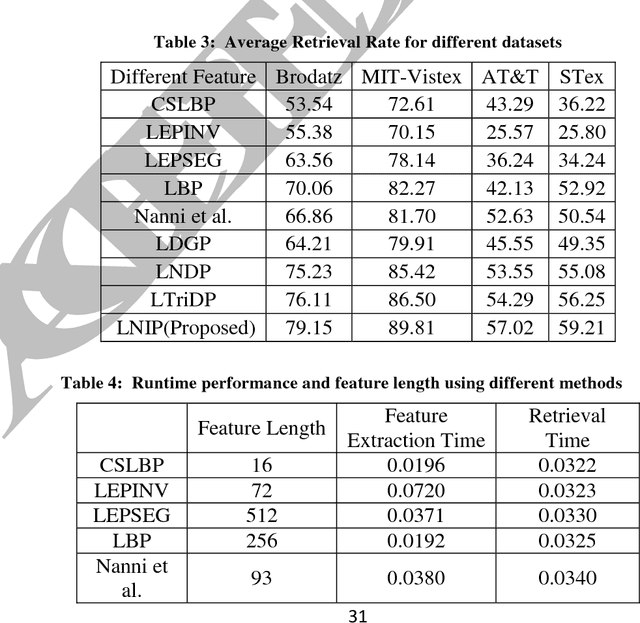
In this paper, a new texture descriptor based on the local neighborhood intensity difference is proposed for content based image retrieval (CBIR). For computation of texture features like Local Binary Pattern (LBP), the center pixel in a 3*3 window of an image is compared with all the remaining neighbors, one pixel at a time to generate a binary bit pattern. It ignores the effect of the adjacent neighbors of a particular pixel for its binary encoding and also for texture description. The proposed method is based on the concept that neighbors of a particular pixel hold a significant amount of texture information that can be considered for efficient texture representation for CBIR. Taking this into account, we develop a new texture descriptor, named as Local Neighborhood Intensity Pattern (LNIP) which considers the relative intensity difference between a particular pixel and the center pixel by considering its adjacent neighbors and generate a sign and a magnitude pattern. Since sign and magnitude patterns hold complementary information to each other, these two patterns are concatenated into a single feature descriptor to generate a more concrete and useful feature descriptor. The proposed descriptor has been tested for image retrieval on four databases, including three texture image databases - Brodatz texture image database, MIT VisTex database and Salzburg texture database and one face database AT&T face database. The precision and recall values observed on these databases are compared with some state-of-art local patterns. The proposed method showed a significant improvement over many other existing methods.
Indic Handwritten Script Identification using Offline-Online Multimodal Deep Network
Feb 23, 2018
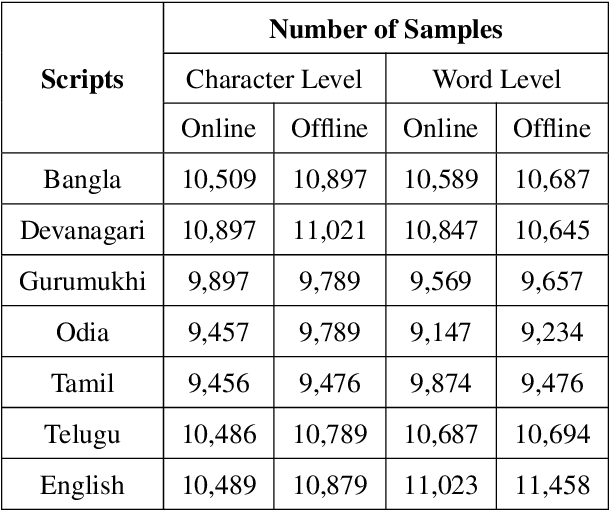
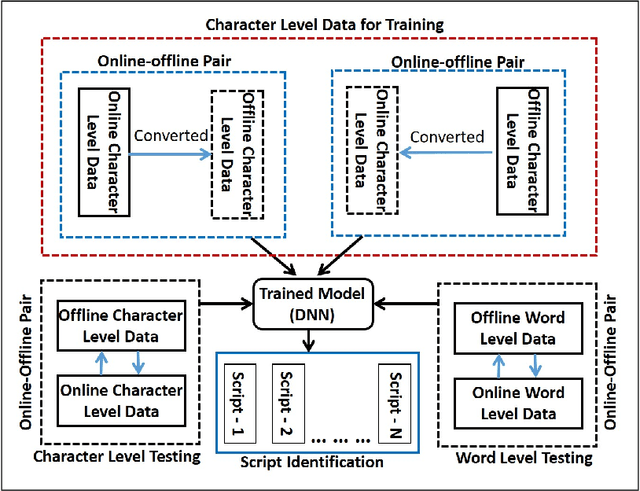
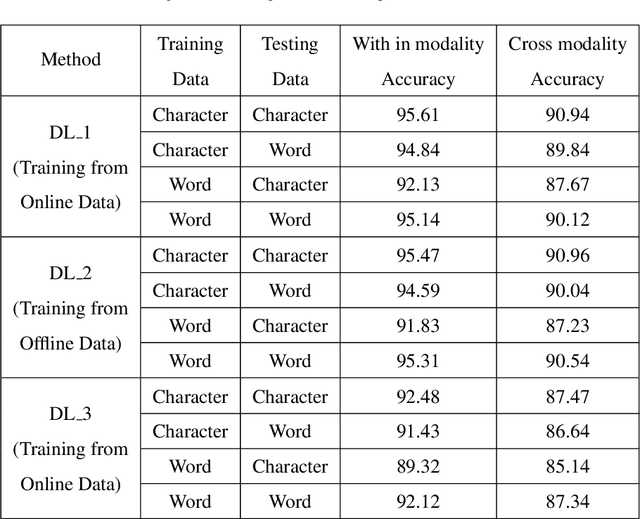
In this paper, we propose a novel approach of word-level Indic script identification using only character-level data in training stage. The advantages of using character level data for training have been outlined in section I. Our method uses a multimodal deep network which takes both offline and online modality of the data as input in order to explore the information from both the modalities jointly for script identification task. We take handwritten data in either modality as input and the opposite modality is generated through intermodality conversion. Thereafter, we feed this offline-online modality pair to our network. Hence, along with the advantage of utilizing information from both the modalities, it can work as a single framework for both offline and online script identification simultaneously which alleviates the need for designing two separate script identification modules for individual modality. One more major contribution is that we propose a novel conditional multimodal fusion scheme to combine the information from offline and online modality which takes into account the real origin of the data being fed to our network and thus it combines adaptively. An exhaustive experiment has been done on a data set consisting of English and six Indic scripts. Our proposed framework clearly outperforms different frameworks based on traditional classifiers along with handcrafted features and deep learning based methods with a clear margin. Extensive experiments show that using only character level training data can achieve state-of-art performance similar to that obtained with traditional training using word level data in our framework.
A Novel Feature Descriptor for Image Retrieval by Combining Modified Color Histogram and Diagonally Symmetric Co-occurrence Texture Pattern
Jan 03, 2018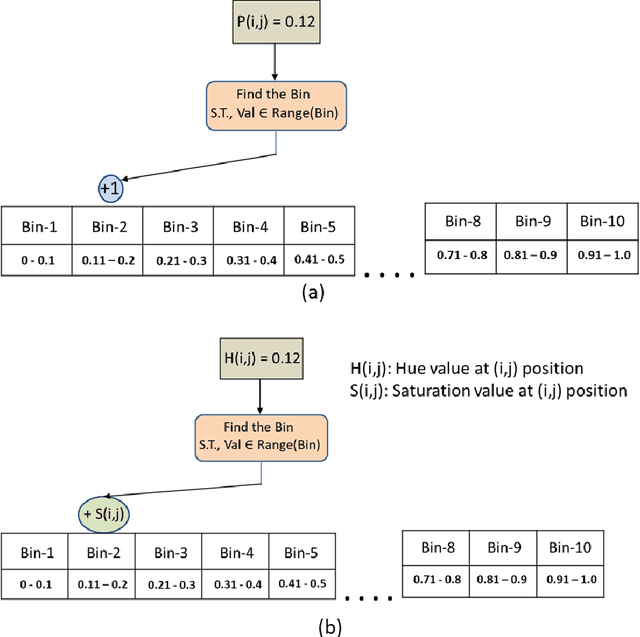

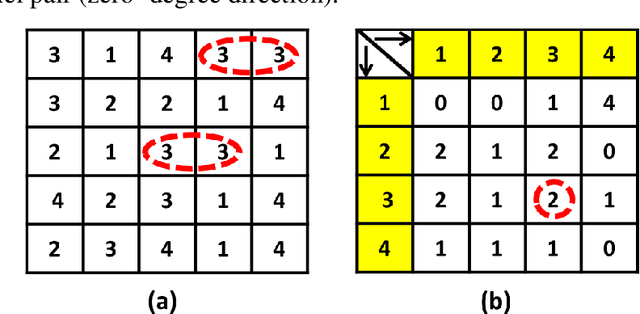
In this paper, we have proposed a novel feature descriptors combining color and texture information collectively. In our proposed color descriptor component, the inter-channel relationship between Hue (H) and Saturation (S) channels in the HSV color space has been explored which was not done earlier. We have quantized the H channel into a number of bins and performed the voting with saturation values and vice versa by following a principle similar to that of the HOG descriptor, where orientation of the gradient is quantized into a certain number of bins and voting is done with gradient magnitude. This helps us to study the nature of variation of saturation with variation in Hue and nature of variation of Hue with the variation in saturation. The texture component of our descriptor considers the co-occurrence relationship between the pixels symmetric about both the diagonals of a 3x3 window. Our work is inspired from the work done by Dubey et al.[1]. These two components, viz. color and texture information individually perform better than existing texture and color descriptors. Moreover, when concatenated the proposed descriptors provide significant improvement over existing descriptors for content base color image retrieval. The proposed descriptor has been tested for image retrieval on five databases, including texture image databases - MIT VisTex database and Salzburg texture database and natural scene databases Corel 1K, Corel 5K and Corel 10K. The precision and recall values experimented on these databases are compared with some state-of-art local patterns. The proposed method provided satisfactory results from the experiments.
Fractional Local Neighborhood Intensity Pattern for Image Retrieval using Genetic Algorithm
Dec 30, 2017
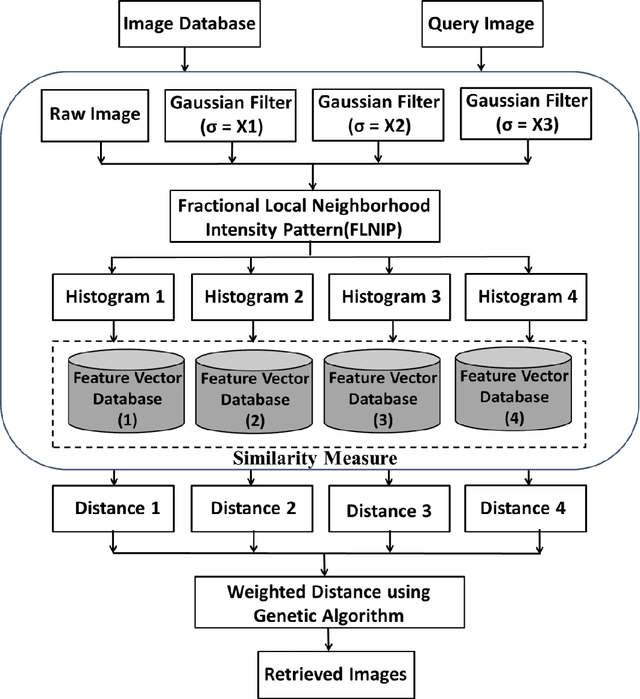
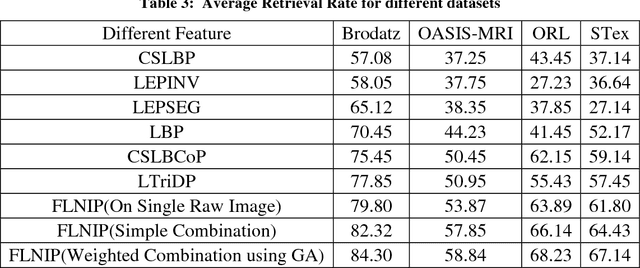
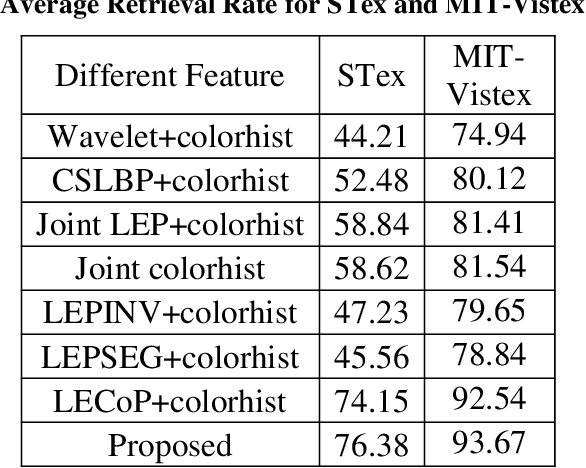
In this paper, a new texture descriptor named "Fractional Local Neighborhood Intensity Pattern" (FLNIP) has been proposed for content based image retrieval (CBIR). It is an extension of the Local Neighborhood Intensity Pattern (LNIP)[1]. FLNIP calculates the relative intensity difference between a particular pixel and the center pixel of a 3x3 window by considering the relationship with adjacent neighbors. In this work, the fractional change in the local neighborhood involving the adjacent neighbors has been calculated first with respect to one of the eight neighbors of the center pixel of a 3x3 window. Next, the fractional change has been calculated with respect to the center itself. The two values of fractional change are next compared to generate a binary bit pattern. Both sign and magnitude information are encoded in a single descriptor as it deals with the relative change in magnitude in the adjacent neighborhood i.e., the comparison of the fractional change. The descriptor is applied on four multi-resolution images- one being the raw image and the other three being filtered gaussian images obtained by applying gaussian filters of different standard deviations on the raw image to signify the importance of exploring texture information at different resolutions in an image. The four sets of distances obtained between the query and the target image are then combined with a genetic algorithm based approach to improve the retrieval performance by minimizing the distance between similar class images. The performance of the method has been tested for image retrieval on four popular databases. The precision and recall values observed on these databases have been compared with recent state-of-art local patterns. The proposed method has shown a significant improvement over many other existing methods.
Recognizing Gender from Human Facial Regions using Genetic Algorithm
Dec 05, 2017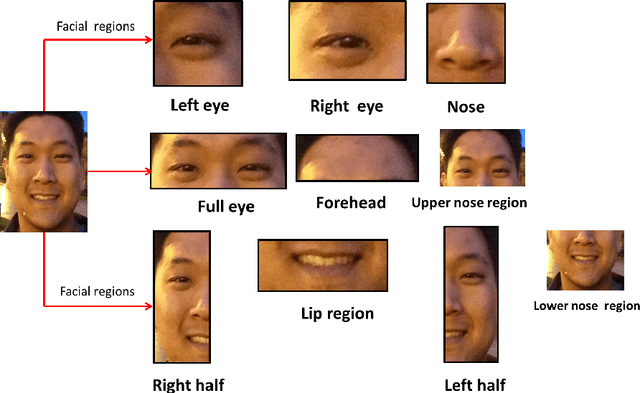
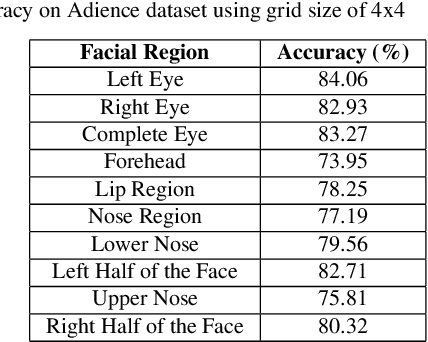

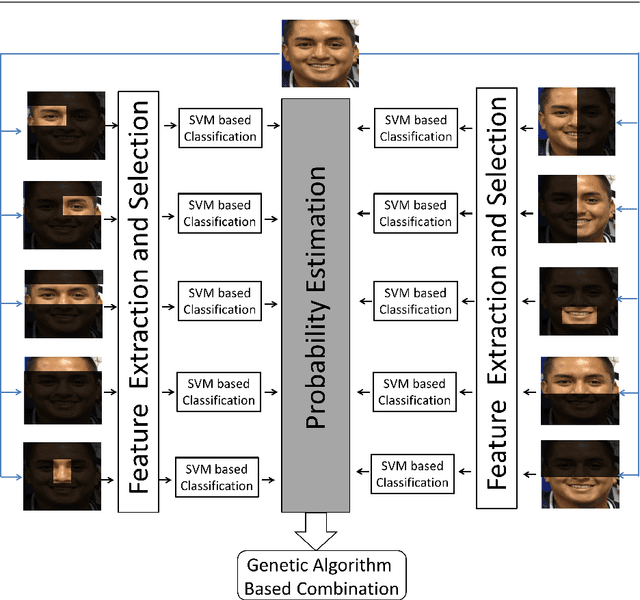
Recently, recognition of gender from facial images has gained a lot of importance. There exist a handful of research work that focus on feature extraction to obtain gender specific information from facial images. However, analyzing different facial regions and their fusion help in deciding the gender of a person from facial images. In this paper, we propose a new approach to identify gender from frontal facial images that is robust to background, illumination, intensity, and facial expression. In our framework, first the frontal face image is divided into a number of distinct regions based on facial landmark points that are obtained by the Chehra model proposed by Asthana et al. The model provides 49 facial landmark points covering different regions of the face, e.g. forehead, left eye, right eye, lips. Next, a face image is segmented into facial regions using landmark points and features are extracted from each region. The Compass LBP feature, a variant of LBP feature, has been used in our framework to obtain discriminative gender-specific information. Following this, a Support Vector Machine based classifier has been used to compute the probability scores from each facial region. Finally, the classification scores obtained from individual regions are combined with a genetic algorithm based learning to improve the overall classification accuracy. The experiments have been performed on popular face image datasets such as Adience, cFERET (color FERET), LFW and two sketch datasets, namely CUFS and CUFSF. Through experiments, we have observed that, the proposed method outperforms existing approaches.