 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks at Any Scale
Nov 14, 2025This article reviews modern optimization methods for training neural networks with an emphasis on efficiency and scale. We present state-of-the-art optimization algorithms under a unified algorithmic template that highlights the importance of adapting to the structures in the problem. We then cover how to make these algorithms agnostic to the scale of the problem. Our exposition is intended as an introduction for both practitioners and researchers who wish to be involved in these exciting new developments.
Training Deep Learning Models with Norm-Constrained LMOs
Feb 11, 2025In this work, we study optimization methods that leverage the linear minimization oracle (LMO) over a norm-ball. We propose a new stochastic family of algorithms that uses the LMO to adapt to the geometry of the problem and, perhaps surprisingly, show that they can be applied to unconstrained problems. The resulting update rule unifies several existing optimization methods under a single framework. Furthermore, we propose an explicit choice of norm for deep architectures, which, as a side benefit, leads to the transferability of hyperparameters across model sizes. Experimentally, we demonstrate significant speedups on nanoGPT training without any reliance on Adam. The proposed method is memory-efficient, requiring only one set of model weights and one set of gradients, which can be stored in half-precision.
A Stochastic Bregman Primal-Dual Splitting Algorithm for Composite Optimization
Dec 22, 2021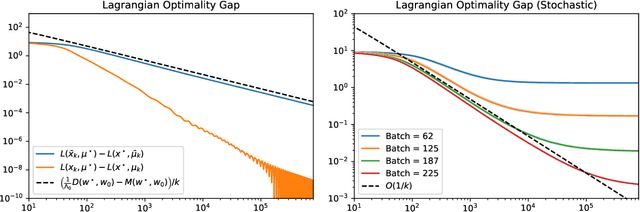
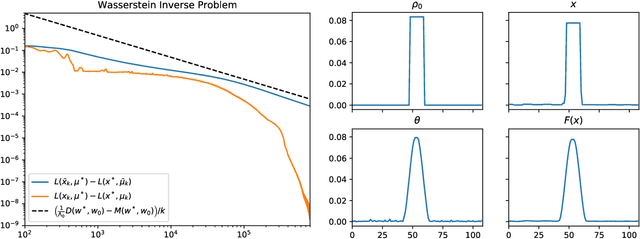
We study a stochastic first order primal-dual method for solving convex-concave saddle point problems over real reflexive Banach spaces using Bregman divergences and relative smoothness assumptions, in which we allow for stochastic error in the computation of gradient terms within the algorithm. We show ergodic convergence in expectation of the Lagrangian optimality gap with a rate of O(1/k) and that every almost sure weak cluster point of the ergodic sequence is a saddle point in expectation under mild assumptions. Under slightly stricter assumptions, we show almost sure weak convergence of the pointwise iterates to a saddle point. Under a relative strong convexity assumption on the objective functions and a total convexity assumption on the entropies of the Bregman divergences, we establish almost sure strong convergence of the pointwise iterates to a saddle point. Our framework is general and does not need strong convexity of the entropies inducing the Bregman divergences in the algorithm. Numerical applications are considered including entropically regularized Wasserstein barycenter problems and regularized inverse problems on the simplex.
Nonsmooth Implicit Differentiation for Machine Learning and Optimization
Jun 08, 2021
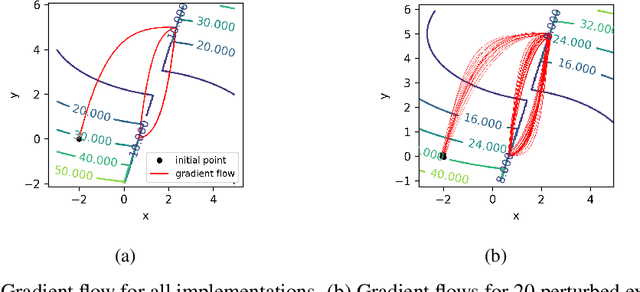
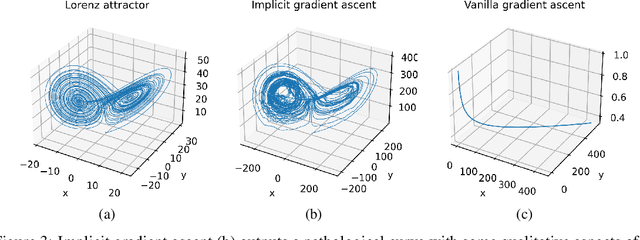

In view of training increasingly complex learning architectures, we establish a nonsmooth implicit function theorem with an operational calculus. Our result applies to most practical problems (i.e., definable problems) provided that a nonsmooth form of the classical invertibility condition is fulfilled. This approach allows for formal subdifferentiation: for instance, replacing derivatives by Clarke Jacobians in the usual differentiation formulas is fully justified for a wide class of nonsmooth problems. Moreover this calculus is entirely compatible with algorithmic differentiation (e.g., backpropagation). We provide several applications such as training deep equilibrium networks, training neural nets with conic optimization layers, or hyperparameter-tuning for nonsmooth Lasso-type models. To show the sharpness of our assumptions, we present numerical experiments showcasing the extremely pathological gradient dynamics one can encounter when applying implicit algorithmic differentiation without any hypothesis.
Inexact and Stochastic Generalized Conditional Gradient with Augmented Lagrangian and Proximal Step
May 11, 2020

In this paper we propose and analyze inexact and stochastic versions of the CGALP algorithm developed in the authors' previous paper, which we denote ICGALP, that allows for errors in the computation of several important quantities. In particular this allows one to compute some gradients, proximal terms, and/or linear minimization oracles in an inexact fashion that facilitates the practical application of the algorithm to computationally intensive settings, e.g. in high (or possibly infinite) dimensional Hilbert spaces commonly found in machine learning problems. The algorithm is able to solve composite minimization problems involving the sum of three convex proper lower-semicontinuous functions subject to an affine constraint of the form $Ax=b$ for some bounded linear operator $A$. Only one of the functions in the objective is assumed to be differentiable, the other two are assumed to have an accessible prox operator and a linear minimization oracle. As main results, we show convergence of the Lagrangian to an optimum and asymptotic feasibility of the affine constraint as well as weak convergence of the dual variable to a solution of the dual problem, all in an almost sure sense. Almost sure convergence rates, both pointwise and ergodic, are given for the Lagrangian values and the feasibility gap. Numerical experiments verifying the predicted rates of convergence are shown as well.