 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiDP: Hierarchical DNN Partitioning for Distributed Inference on Heterogeneous Edge Platforms
Nov 25, 2024



Edge inference techniques partition and distribute Deep Neural Network (DNN) inference tasks among multiple edge nodes for low latency inference, without considering the core-level heterogeneity of edge nodes. Further, default DNN inference frameworks also do not fully utilize the resources of heterogeneous edge nodes, resulting in higher inference latency. In this work, we propose a hierarchical DNN partitioning strategy (HiDP) for distributed inference on heterogeneous edge nodes. Our strategy hierarchically partitions DNN workloads at both global and local levels by considering the core-level heterogeneity of edge nodes. We evaluated our proposed HiDP strategy against relevant distributed inference techniques over widely used DNN models on commercial edge devices. On average our strategy achieved 38% lower latency, 46% lower energy, and 56% higher throughput in comparison with other relevant approaches.
Characterizing Accuracy Trade-offs of EEG Applications on Embedded HMPs
Feb 15, 2024Electroencephalography (EEG) recordings are analyzed using battery-powered wearable devices to monitor brain activities and neurological disorders. These applications require long and continuous processing to generate feasible results. However, wearable devices are constrained with limited energy and computation resources, owing to their small sizes for practical use cases. Embedded heterogeneous multi-core platforms (HMPs) can provide better performance within limited energy budgets for EEG applications. Error resilience of the EEG application pipeline can be exploited further to maximize the performance and energy gains with HMPs. However, disciplined tuning of approximation on embedded HMPs requires a thorough exploration of the accuracy-performance-power trade-off space. In this work, we characterize the error resilience of three EEG applications, including Epileptic Seizure Detection, Sleep Stage Classification, and Stress Detection on the real-world embedded HMP test-bed of the Odroid XU3 platform. We present a combinatorial evaluation of power-performance-accuracy trade-offs of EEG applications at different approximation, power, and performance levels to provide insights into the disciplined tuning of approximation in EEG applications on embedded platforms.
Adaptive Workload Distribution for Accuracy-aware DNN Inference on Collaborative Edge Platforms
Oct 16, 2023DNN inference can be accelerated by distributing the workload among a cluster of collaborative edge nodes. Heterogeneity among edge devices and accuracy-performance trade-offs of DNN models present a complex exploration space while catering to the inference performance requirements. In this work, we propose adaptive workload distribution for DNN inference, jointly considering node-level heterogeneity of edge devices, and application-specific accuracy and performance requirements. Our proposed approach combinatorially optimizes heterogeneity-aware workload partitioning and dynamic accuracy configuration of DNN models to ensure performance and accuracy guarantees. We tested our approach on an edge cluster of Odroid XU4, Raspberry Pi4, and Jetson Nano boards and achieved an average gain of 41.52% in performance and 5.2% in output accuracy as compared to state-of-the-art workload distribution strategies.
Resilience of Deep Learning applications: a systematic survey of analysis and hardening techniques
Sep 27, 2023Machine Learning (ML) is currently being exploited in numerous applications being one of the most effective Artificial Intelligence (AI) technologies, used in diverse fields, such as vision, autonomous systems, and alike. The trend motivated a significant amount of contributions to the analysis and design of ML applications against faults affecting the underlying hardware. The authors investigate the existing body of knowledge on Deep Learning (among ML techniques) resilience against hardware faults systematically through a thoughtful review in which the strengths and weaknesses of this literature stream are presented clearly and then future avenues of research are set out. The review is based on 163 scientific articles published between January 2019 and March 2023. The authors adopt a classifying framework to interpret and highlight research similarities and peculiarities, based on several parameters, starting from the main scope of the work, the adopted fault and error models, to their reproducibility. This framework allows for a comparison of the different solutions and the identification of possible synergies. Furthermore, suggestions concerning the future direction of research are proposed in the form of open challenges to be addressed.
Fast and Accurate Error Simulation for CNNs against Soft Errors
Jun 04, 2022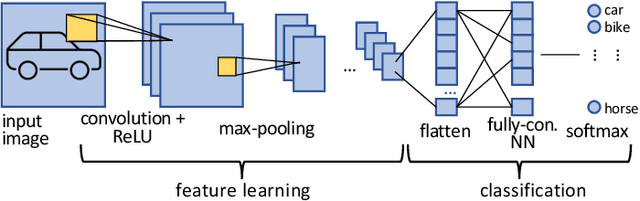
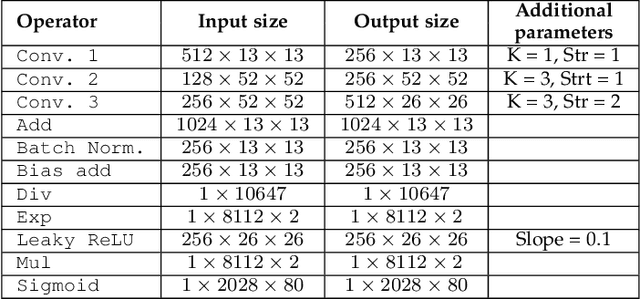
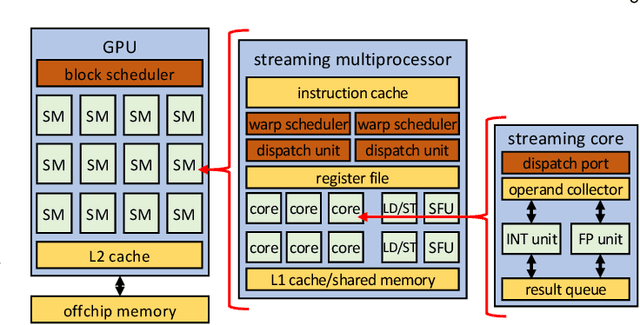
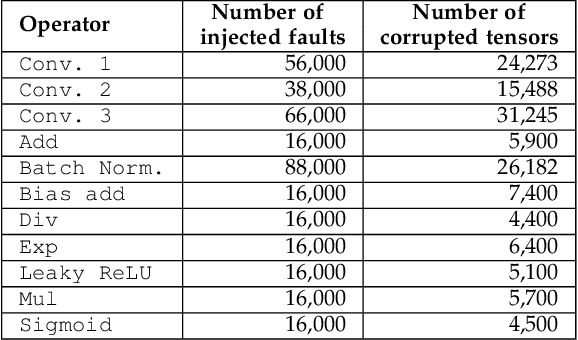
The great quest for adopting AI-based computation for safety-/mission-critical applications motivates the interest towards methods for assessing the robustness of the application w.r.t. not only its training/tuning but also errors due to faults, in particular soft errors, affecting the underlying hardware. Two strategies exist: architecture-level fault injection and application-level functional error simulation. We present a framework for the reliability analysis of Convolutional Neural Networks (CNNs) via an error simulation engine that exploits a set of validated error models extracted from a detailed fault injection campaign. These error models are defined based on the corruption patterns of the output of the CNN operators induced by faults and bridge the gap between fault injection and error simulation, exploiting the advantages of both approaches. We compared our methodology against SASSIFI for the accuracy of functional error simulation w.r.t. fault injection, and against TensorFI in terms of speedup for the error simulation strategy. Experimental results show that our methodology achieves about 99\% accuracy of the fault effects w.r.t. SASSIFI, and a speedup ranging from 44x up to 63x w.r.t. TensorFI, that only implements a limited set of error models.
Energy-Efficient Mobile Robot Control via Run-time Monitoring of Environmental Complexity and Computing Workload
Sep 08, 2021

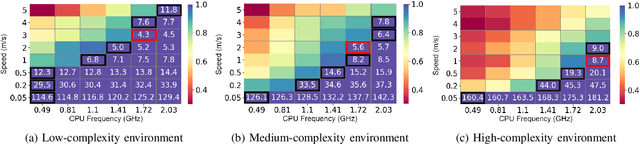
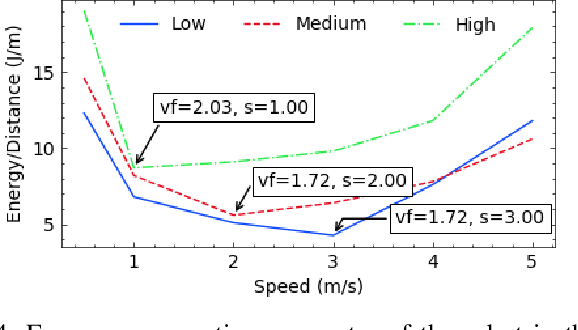
We propose an energy-efficient controller to minimize the energy consumption of a mobile robot by dynamically manipulating the mechanical and computational actuators of the robot. The mobile robot performs real-time vision-based applications based on an event-based camera. The actuators of the controller are CPU voltage/frequency for the computation part and motor voltage for the mechanical part. We show that independently considering speed control of the robot and voltage/frequency control of the CPU does not necessarily result in an energy-efficient solution. In fact, to obtain the highest efficiency, the computation and mechanical parts should be controlled together in synergy. We propose a fast hill-climbing optimization algorithm to allow the controller to find the best CPU/motor configuration at run-time and whenever the mobile robot is facing a new environment during its travel. Experimental results on a robot with Brushless DC Motors, Jetson TX2 board as the computing unit, and a DAVIS-346 event-based camera show that the proposed control algorithm can save battery energy by an average of 50.5%, 41%, and 30%, in low-complexity, medium-complexity, and high-complexity environments, over baselines.
Asynchronous Corner Tracking Algorithm based on Lifetime of Events for DAVIS Cameras
Oct 29, 2020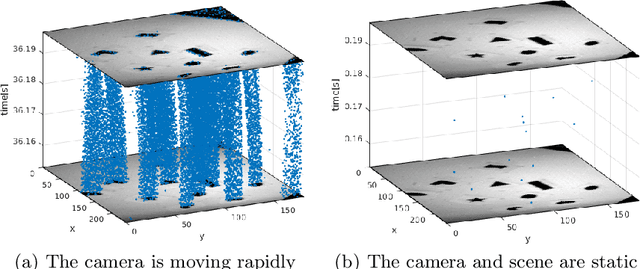
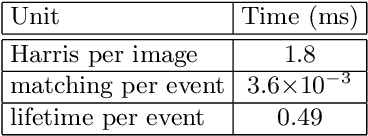
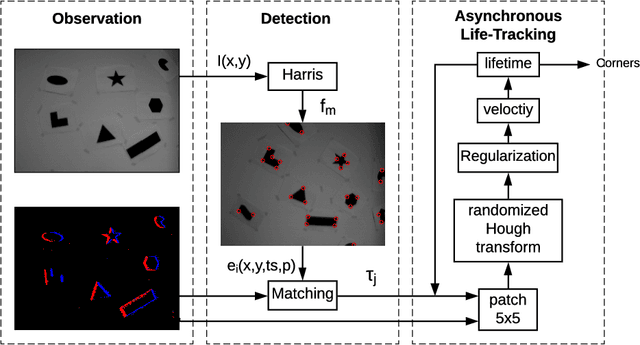

Event cameras, i.e., the Dynamic and Active-pixel Vision Sensor (DAVIS) ones, capture the intensity changes in the scene and generates a stream of events in an asynchronous fashion. The output rate of such cameras can reach up to 10 million events per second in high dynamic environments. DAVIS cameras use novel vision sensors that mimic human eyes. Their attractive attributes, such as high output rate, High Dynamic Range (HDR), and high pixel bandwidth, make them an ideal solution for applications that require high-frequency tracking. Moreover, applications that operate in challenging lighting scenarios can exploit the high HDR of event cameras, i.e., 140 dB compared to 60 dB of traditional cameras. In this paper, a novel asynchronous corner tracking method is proposed that uses both events and intensity images captured by a DAVIS camera. The Harris algorithm is used to extract features, i.e., frame-corners from keyframes, i.e., intensity images. Afterward, a matching algorithm is used to extract event-corners from the stream of events. Events are solely used to perform asynchronous tracking until the next keyframe is captured. Neighboring events, within a window size of 5x5 pixels around the event-corner, are used to calculate the velocity and direction of extracted event-corners by fitting the 2D planar using a randomized Hough transform algorithm. Experimental evaluation showed that our approach is able to update the location of the extracted corners up to 100 times during the blind time of traditional cameras, i.e., between two consecutive intensity images.
Dynamic Resource-aware Corner Detection for Bio-inspired Vision Sensors
Oct 29, 2020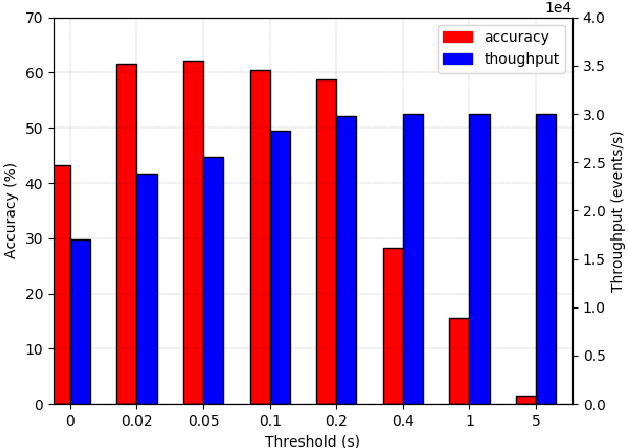

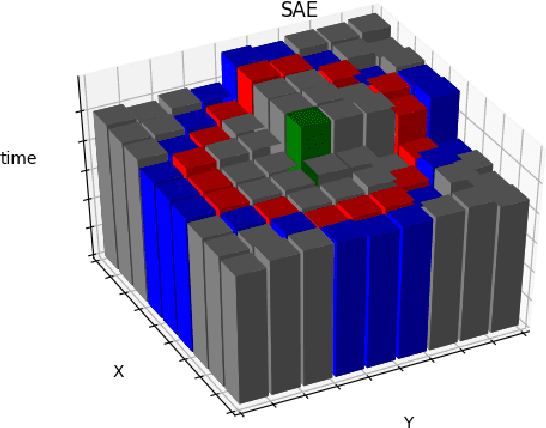

Event-based cameras are vision devices that transmit only brightness changes with low latency and ultra-low power consumption. Such characteristics make event-based cameras attractive in the field of localization and object tracking in resource-constrained systems. Since the number of generated events in such cameras is huge, the selection and filtering of the incoming events are beneficial from both increasing the accuracy of the features and reducing the computational load. In this paper, we present an algorithm to detect asynchronous corners from a stream of events in real-time on embedded systems. The algorithm is called the Three Layer Filtering-Harris or TLF-Harris algorithm. The algorithm is based on an events' filtering strategy whose purpose is 1) to increase the accuracy by deliberately eliminating some incoming events, i.e., noise, and 2) to improve the real-time performance of the system, i.e., preserving a constant throughput in terms of input events per second, by discarding unnecessary events with a limited accuracy loss. An approximation of the Harris algorithm, in turn, is used to exploit its high-quality detection capability with a low-complexity implementation to enable seamless real-time performance on embedded computing platforms. The proposed algorithm is capable of selecting the best corner candidate among neighbors and achieves an average execution time savings of 59 % compared with the conventional Harris score. Moreover, our approach outperforms the competing methods, such as eFAST, eHarris, and FA-Harris, in terms of real-time performance, and surpasses Arc* in terms of accuracy.