 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMislabel Detection of Finnish Publication Ranks
Dec 19, 2019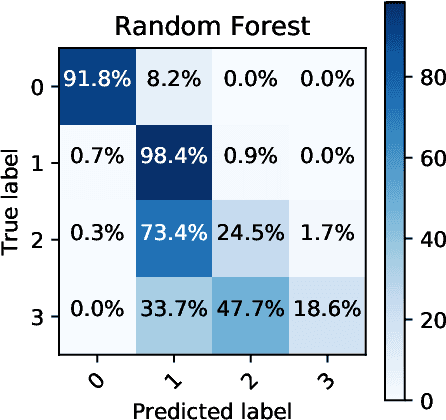
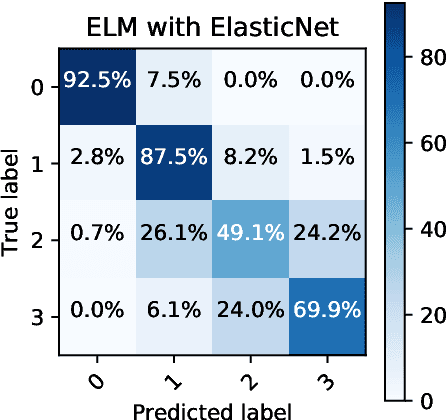
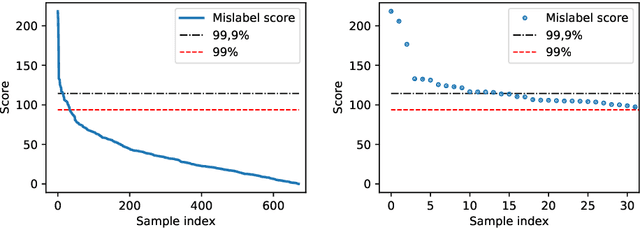
The paper proposes to analyze a data set of Finnish ranks of academic publication channels with Extreme Learning Machine (ELM). The purpose is to introduce and test recently proposed ELM-based mislabel detection approach with a rich set of features characterizing a publication channel. We will compare the architecture, accuracy, and, especially, the set of detected mislabels of the ELM-based approach to the corresponding reference results on the reference paper.
Per-sample Prediction Intervals for Extreme Learning Machines
Dec 19, 2019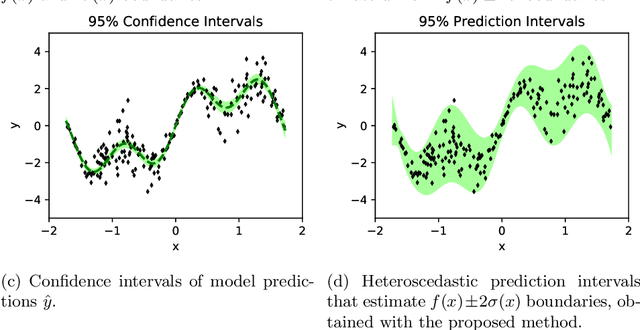

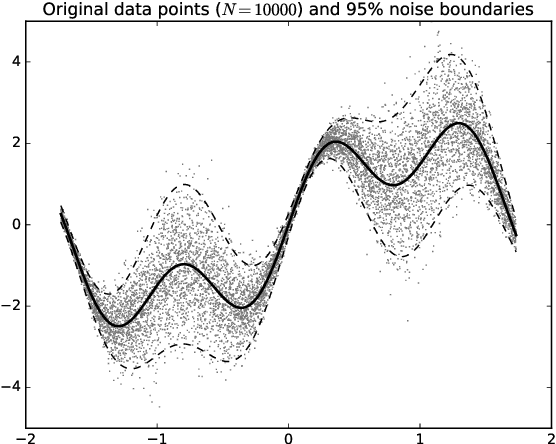

Prediction intervals in supervised Machine Learning bound the region where the true outputs of new samples may fall. They are necessary in the task of separating reliable predictions of a trained model from near random guesses, minimizing the rate of False Positives, and other problem-specific tasks in applied Machine Learning. Many real problems have heteroscedastic stochastic outputs, which explains the need of input-dependent prediction intervals. This paper proposes to estimate the input-dependent prediction intervals by a separate Extreme Learning Machine model, using variance of its predictions as a correction term accounting for the model uncertainty. The variance is estimated from the model's linear output layer with a weighted Jackknife method. The methodology is very fast, robust to heteroscedastic outputs, and handles both extremely large datasets and insufficient amount of training data.
Extreme Learning Tree
Dec 19, 2019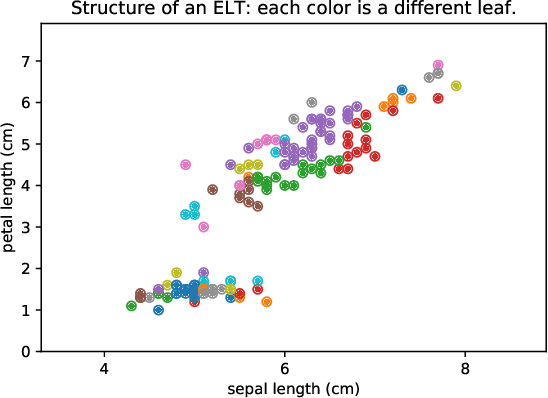
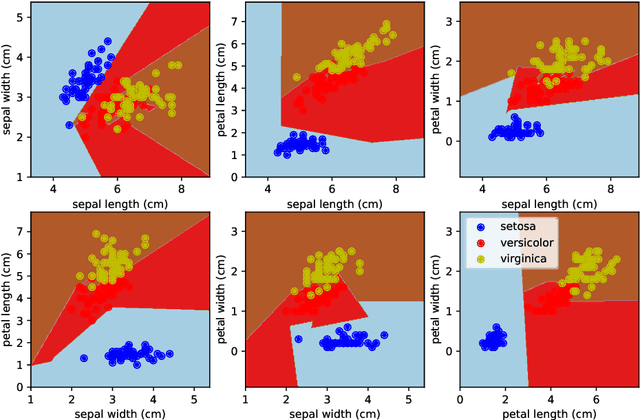
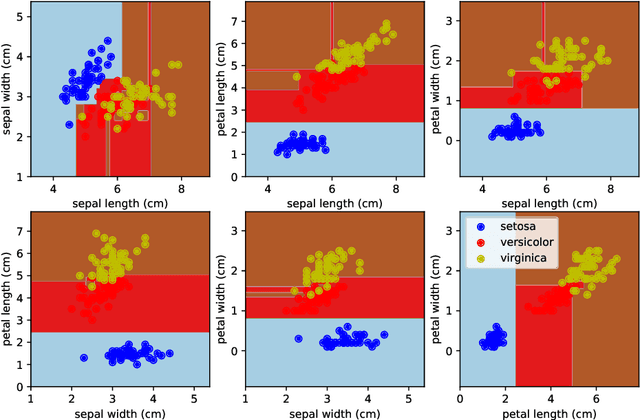
The paper proposes a new variant of a decision tree, called an Extreme Learning Tree. It consists of an extremely random tree with non-linear data transformation, and a linear observer that provides predictions based on the leaf index where the data samples fall. The proposed method outperforms linear models on a benchmark dataset, and may be a building block for a future variant of Random Forest.
Spiking Networks for Improved Cognitive Abilities of Edge Computing Devices
Dec 19, 2019
This concept paper highlights a recently opened opportunity for large scale analytical algorithms to be trained directly on edge devices. Such approach is a response to the arising need of processing data generated by natural person (a human being), also known as personal data. Spiking Neural networks are the core method behind it: suitable for a low latency energy-constrained hardware, enabling local training or re-training, while not taking advantage of scalability available in the Cloud.
A Web Page Classifier Library Based on Random Image Content Analysis Using Deep Learning
Dec 18, 2019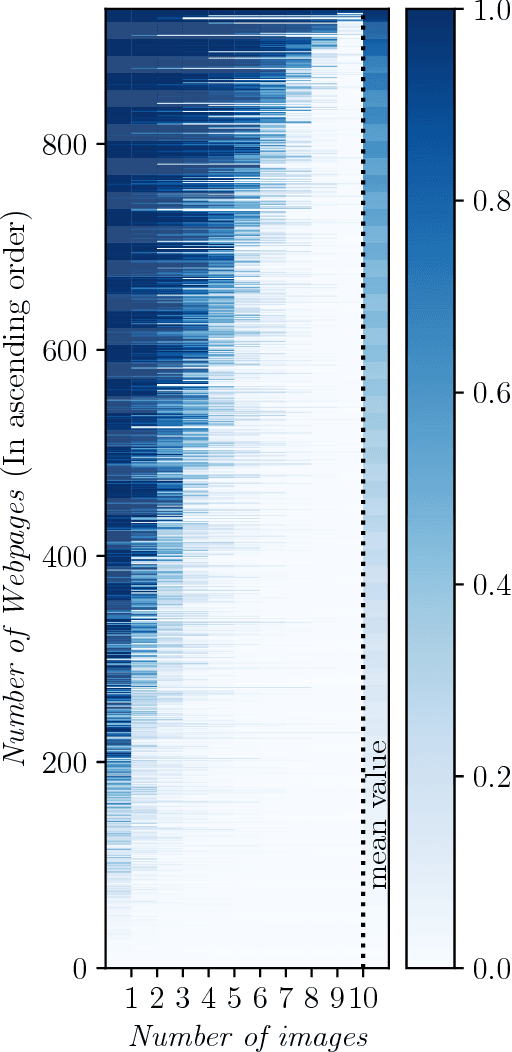
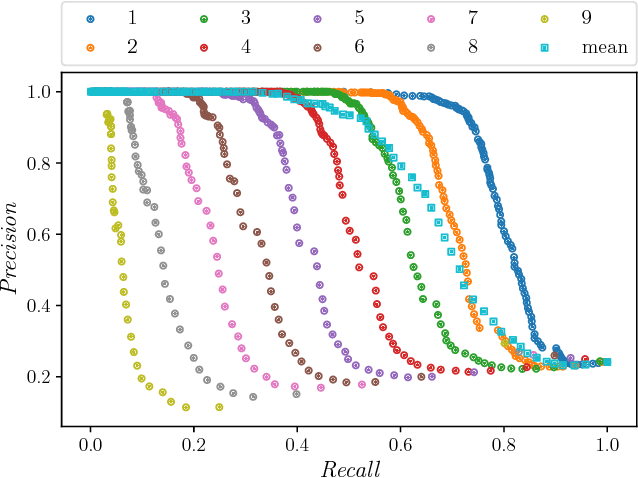
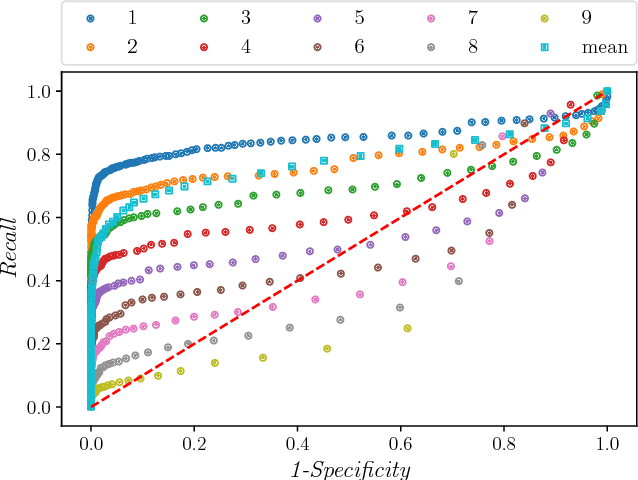
In this paper, we present a methodology and the corresponding Python library 1 for the classification of webpages. Our method retrieves a fixed number of images from a given webpage, and based on them classifies the webpage into a set of established classes with a given probability. The library trains a random forest model build upon the features extracted from images by a pre-trained deep network. The implementation is tested by recognizing weapon class webpages in a curated list of 3859 websites. The results show that the best method of classifying a webpage into the studies classes is to assign the class according to the maximum probability of any image belonging to this (weapon) class being above the threshold, across all the retrieved images. Further research explores the possibilities for the developed methodology to also apply in image classification for healthcare applications.
Incremental ELMVIS for unsupervised learning
Dec 18, 2019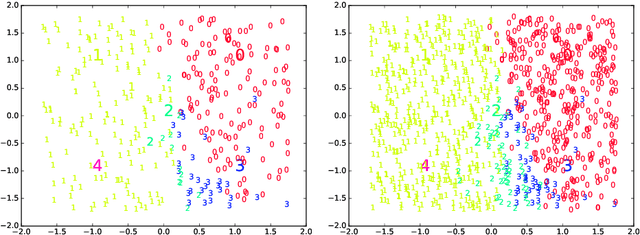
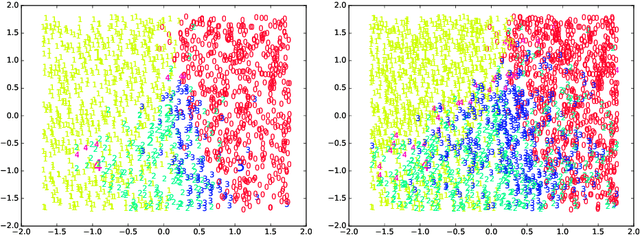
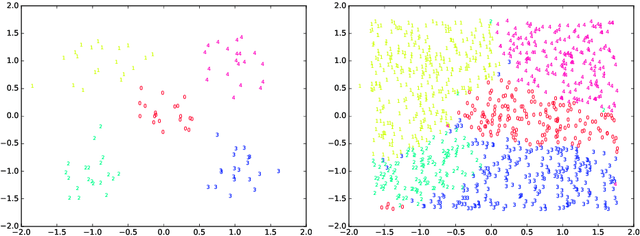
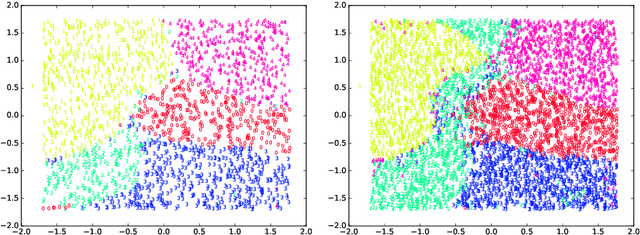
An incremental version of the ELMVIS+ method is proposed in this paper. It iteratively selects a few best fitting data samples from a large pool, and adds them to the model. The method keeps high speed of ELMVIS+ while allowing for much larger possible sample pools due to lower memory requirements. The extension is useful for reaching a better local optimum with greedy optimization of ELMVIS, and the data structure can be specified in semi-supervised optimization. The major new application of incremental ELMVIS is not to visualization, but to a general dataset processing. The method is capable of learning dependencies from non-organized unsupervised data -- either reconstructing a shuffled dataset, or learning dependencies in complex high-dimensional space. The results are interesting and promising, although there is space for improvements.
Comparison of Classification Methods for Very High-Dimensional Data in Sparse Random Projection Representation
Dec 18, 2019


The big data trend has inspired feature-driven learning tasks, which cannot be handled by conventional machine learning models. Unstructured data produces very large binary matrices with millions of columns when converted to vector form. However, such data is often sparse, and hence can be manageable through the use of sparse random projections. This work studies efficient non-iterative and iterative methods suitable for such data, evaluating the results on two representative machine learning tasks with millions of samples and features. An efficient Jaccard kernel is introduced as an alternative to the sparse random projection. Findings indicate that non-iterative methods can find larger, more accurate models than iterative methods in different application scenarios.