 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental ELMVIS for unsupervised learning
Paper and Code
Dec 18, 2019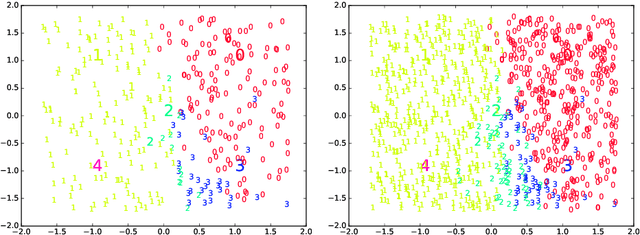
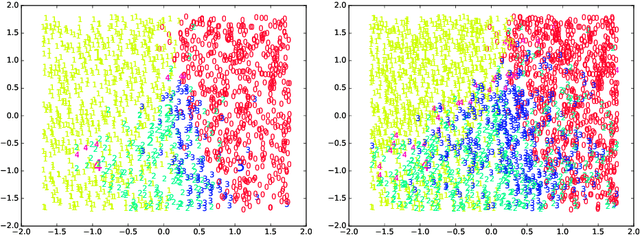
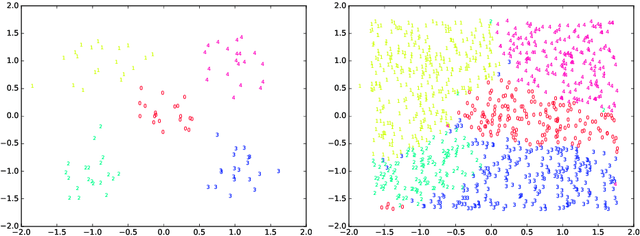
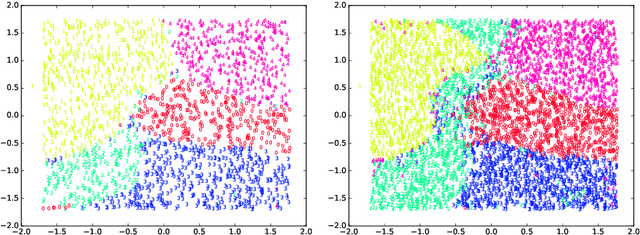
An incremental version of the ELMVIS+ method is proposed in this paper. It iteratively selects a few best fitting data samples from a large pool, and adds them to the model. The method keeps high speed of ELMVIS+ while allowing for much larger possible sample pools due to lower memory requirements. The extension is useful for reaching a better local optimum with greedy optimization of ELMVIS, and the data structure can be specified in semi-supervised optimization. The major new application of incremental ELMVIS is not to visualization, but to a general dataset processing. The method is capable of learning dependencies from non-organized unsupervised data -- either reconstructing a shuffled dataset, or learning dependencies in complex high-dimensional space. The results are interesting and promising, although there is space for improvements.