 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Web Page Classifier Library Based on Random Image Content Analysis Using Deep Learning
Paper and Code
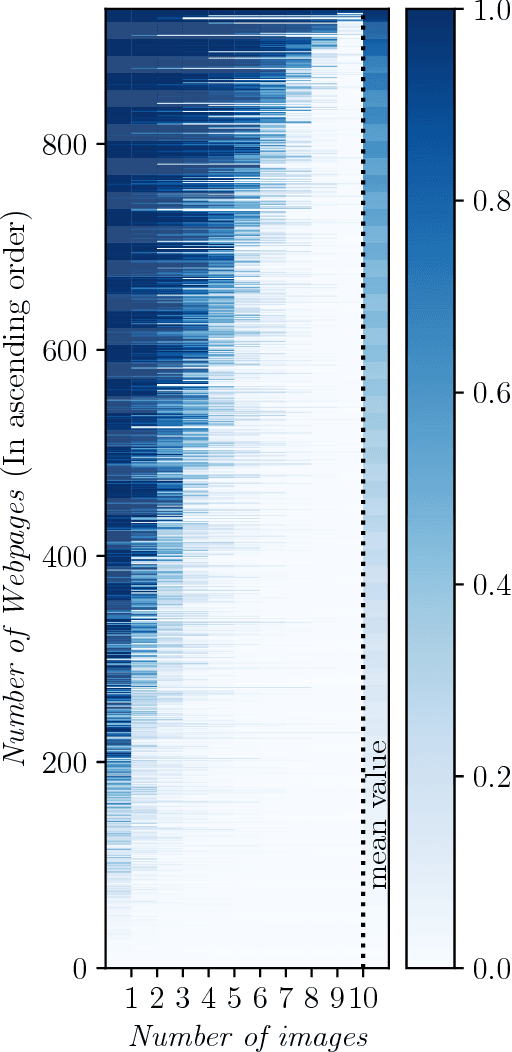
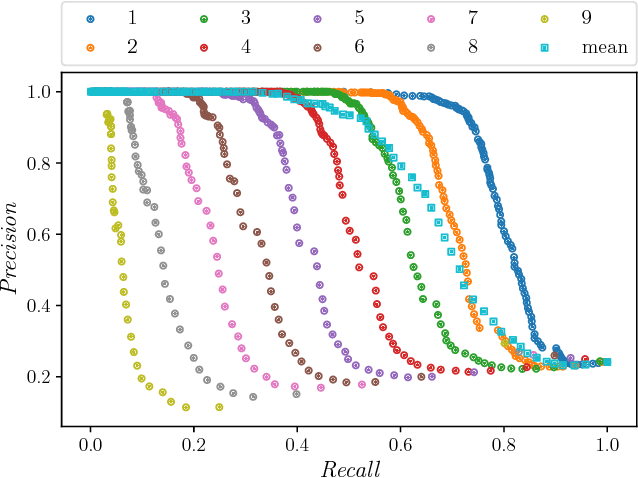
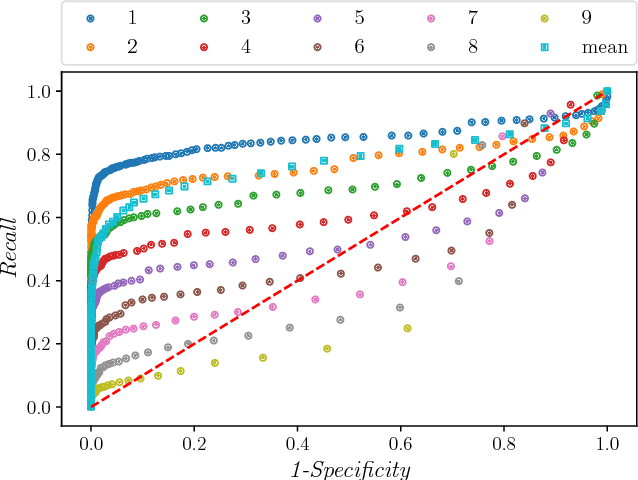
In this paper, we present a methodology and the corresponding Python library 1 for the classification of webpages. Our method retrieves a fixed number of images from a given webpage, and based on them classifies the webpage into a set of established classes with a given probability. The library trains a random forest model build upon the features extracted from images by a pre-trained deep network. The implementation is tested by recognizing weapon class webpages in a curated list of 3859 websites. The results show that the best method of classifying a webpage into the studies classes is to assign the class according to the maximum probability of any image belonging to this (weapon) class being above the threshold, across all the retrieved images. Further research explores the possibilities for the developed methodology to also apply in image classification for healthcare applications.