 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Neural Network Plasticity for Faster Transfer Learning
Mar 21, 2026Transfer learning with models pretrained on ImageNet has become a standard practice in computer vision. Transfer learning refers to fine-tuning pretrained weights of a neural network on a downstream task, typically unrelated to ImageNet. However, pretrained weights can become saturated and may yield insignificant gradients, failing to adapt to the downstream task. This hinders the ability of the model to train effectively, and is commonly referred to as loss of neural plasticity. Loss of plasticity may prevent the model from fully adapting to the target domain, especially when the downstream dataset is atypical in nature. While this issue has been widely explored in continual learning, it remains relatively understudied in the context of transfer learning. In this work, we propose the use of a targeted weight re-initialization strategy to restore neural plasticity prior to fine-tuning. Our experiments show that both convolutional neural networks (CNNs) and vision transformers (ViTs) benefit from this approach, yielding higher test accuracy with faster convergence on several image classification benchmarks. Our method introduces negligible computational overhead and is compatible with common transfer learning pipelines.
* 11 pages, 1 figure, 6 tables and 2 formulas
Online Meta-learning for AutoML in Real-time (OnMAR)
Feb 27, 2025Automated machine learning (AutoML) is a research area focusing on using optimisation techniques to design machine learning (ML) algorithms, alleviating the need for a human to perform manual algorithm design. Real-time AutoML enables the design process to happen while the ML algorithm is being applied to a task. Real-time AutoML is an emerging research area, as such existing real-time AutoML techniques need improvement with respect to the quality of designs and time taken to create designs. To address these issues, this study proposes an Online Meta-learning for AutoML in Real-time (OnMAR) approach. Meta-learning gathers information about the optimisation process undertaken by the ML algorithm in the form of meta-features. Meta-features are used in conjunction with a meta-learner to optimise the optimisation process. The OnMAR approach uses a meta-learner to predict the accuracy of an ML design. If the accuracy predicted by the meta-learner is sufficient, the design is used, and if the predicted accuracy is low, an optimisation technique creates a new design. A genetic algorithm (GA) is the optimisation technique used as part of the OnMAR approach. Different meta-learners (k-nearest neighbours, random forest and XGBoost) are tested. The OnMAR approach is model-agnostic (i.e. not specific to a single real-time AutoML application) and therefore evaluated on three different real-time AutoML applications, namely: composing an image clustering algorithm, configuring the hyper-parameters of a convolutional neural network, and configuring a video classification pipeline. The OnMAR approach is effective, matching or outperforming existing real-time AutoML approaches, with the added benefit of a faster runtime.
Multi-Objective Evolutionary Neural Architecture Search for Recurrent Neural Networks
Mar 17, 2024Artificial neural network (NN) architecture design is a nontrivial and time-consuming task that often requires a high level of human expertise. Neural architecture search (NAS) serves to automate the design of NN architectures and has proven to be successful in automatically finding NN architectures that outperform those manually designed by human experts. NN architecture performance can be quantified based on multiple objectives, which include model accuracy and some NN architecture complexity objectives, among others. The majority of modern NAS methods that consider multiple objectives for NN architecture performance evaluation are concerned with automated feed forward NN architecture design, which leaves multi-objective automated recurrent neural network (RNN) architecture design unexplored. RNNs are important for modeling sequential datasets, and prominent within the natural language processing domain. It is often the case in real world implementations of machine learning and NNs that a reasonable trade-off is accepted for marginally reduced model accuracy in favour of lower computational resources demanded by the model. This paper proposes a multi-objective evolutionary algorithm-based RNN architecture search method. The proposed method relies on approximate network morphisms for RNN architecture complexity optimisation during evolution. The results show that the proposed method is capable of finding novel RNN architectures with comparable performance to state-of-the-art manually designed RNN architectures, but with reduced computational demand.
Distal Interference: Exploring the Limits of Model-Based Continual Learning
Feb 13, 2024
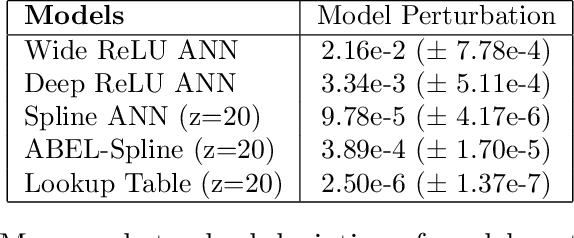

Continual learning is the sequential learning of different tasks by a machine learning model. Continual learning is known to be hindered by catastrophic interference or forgetting, i.e. rapid unlearning of earlier learned tasks when new tasks are learned. Despite their practical success, artificial neural networks (ANNs) are prone to catastrophic interference. This study analyses how gradient descent and overlapping representations between distant input points lead to distal interference and catastrophic interference. Distal interference refers to the phenomenon where training a model on a subset of the domain leads to non-local changes on other subsets of the domain. This study shows that uniformly trainable models without distal interference must be exponentially large. A novel antisymmetric bounded exponential layer B-spline ANN architecture named ABEL-Spline is proposed that can approximate any continuous function, is uniformly trainable, has polynomial computational complexity, and provides some guarantees for distal interference. Experiments are presented to demonstrate the theoretical properties of ABEL-Splines. ABEL-Splines are also evaluated on benchmark regression problems. It is concluded that the weaker distal interference guarantees in ABEL-Splines are insufficient for model-only continual learning. It is conjectured that continual learning with polynomial complexity models requires augmentation of the training data or algorithm.
Empirical Loss Landscape Analysis of Neural Network Activation Functions
Jun 28, 2023
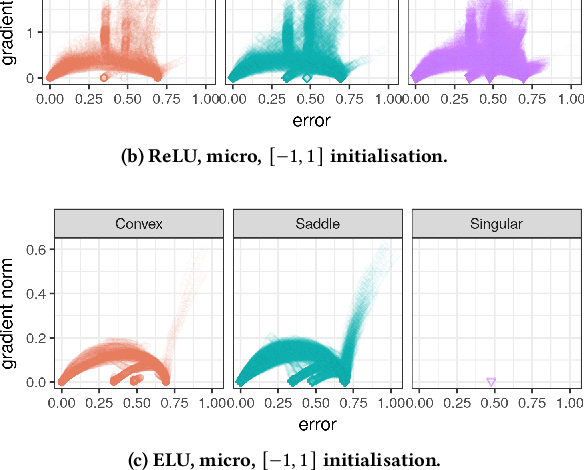
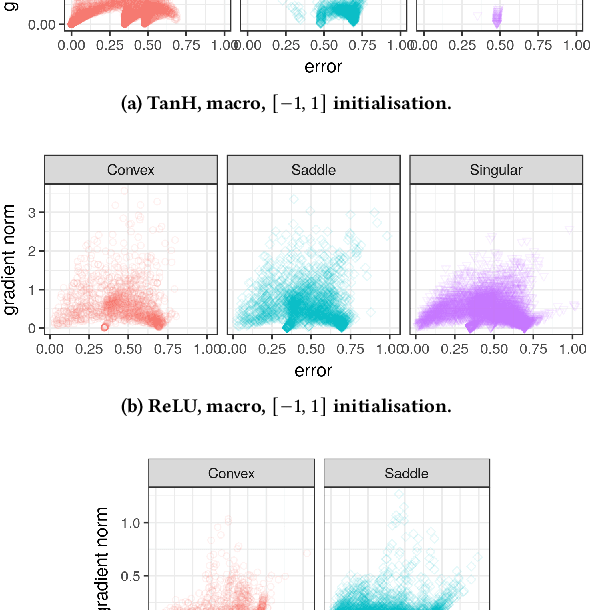
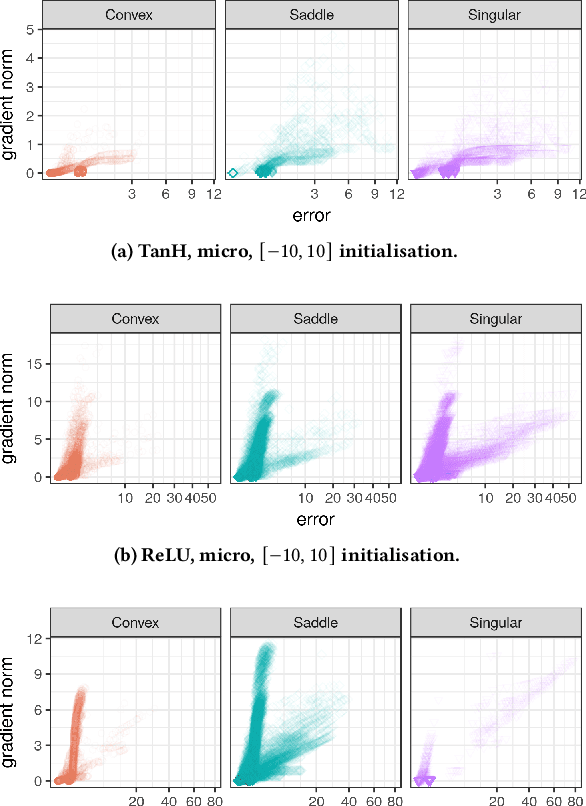
Activation functions play a significant role in neural network design by enabling non-linearity. The choice of activation function was previously shown to influence the properties of the resulting loss landscape. Understanding the relationship between activation functions and loss landscape properties is important for neural architecture and training algorithm design. This study empirically investigates neural network loss landscapes associated with hyperbolic tangent, rectified linear unit, and exponential linear unit activation functions. Rectified linear unit is shown to yield the most convex loss landscape, and exponential linear unit is shown to yield the least flat loss landscape, and to exhibit superior generalisation performance. The presence of wide and narrow valleys in the loss landscape is established for all activation functions, and the narrow valleys are shown to correlate with saturated neurons and implicitly regularised network configurations.
Genetic Micro-Programs for Automated Software Testing with Large Path Coverage
Feb 14, 2023Ongoing progress in computational intelligence (CI) has led to an increased desire to apply CI techniques for the purpose of improving software engineering processes, particularly software testing. Existing state-of-the-art automated software testing techniques focus on utilising search algorithms to discover input values that achieve high execution path coverage. These algorithms are trained on the same code that they intend to test, requiring instrumentation and lengthy search times to test each software component. This paper outlines a novel genetic programming framework, where the evolved solutions are not input values, but micro-programs that can repeatedly generate input values to efficiently explore a software component's input parameter domain. We also argue that our approach can be generalised such as to be applied to many different software systems, and is thus not specific to merely the particular software component on which it was trained.
Cauchy Loss Function: Robustness Under Gaussian and Cauchy Noise
Feb 14, 2023In supervised machine learning, the choice of loss function implicitly assumes a particular noise distribution over the data. For example, the frequently used mean squared error (MSE) loss assumes a Gaussian noise distribution. The choice of loss function during training and testing affects the performance of artificial neural networks (ANNs). It is known that MSE may yield substandard performance in the presence of outliers. The Cauchy loss function (CLF) assumes a Cauchy noise distribution, and is therefore potentially better suited for data with outliers. This papers aims to determine the extent of robustness and generalisability of the CLF as compared to MSE. CLF and MSE are assessed on a few handcrafted regression problems, and a real-world regression problem with artificially simulated outliers, in the context of ANN training. CLF yielded results that were either comparable to or better than the results yielded by MSE, with a few notable exceptions.
Comparision Of Adversarial And Non-Adversarial LSTM Music Generative Models
Nov 01, 2022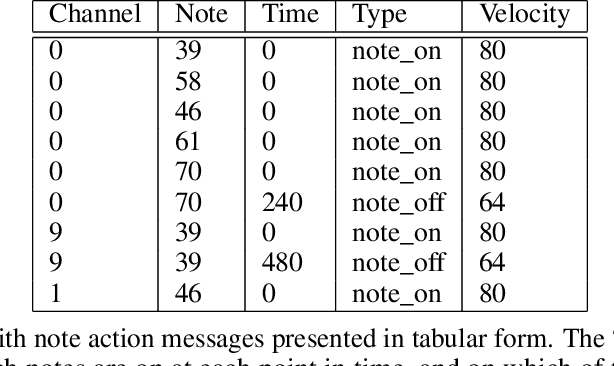
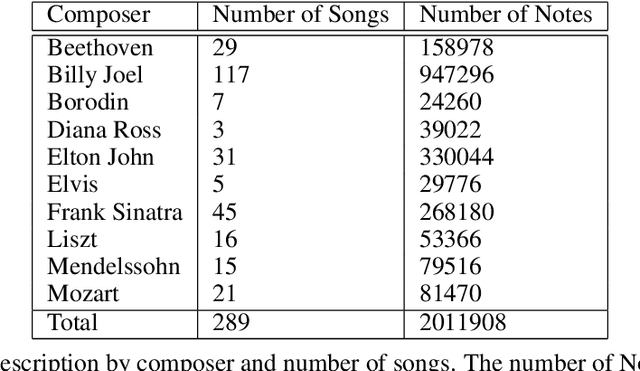
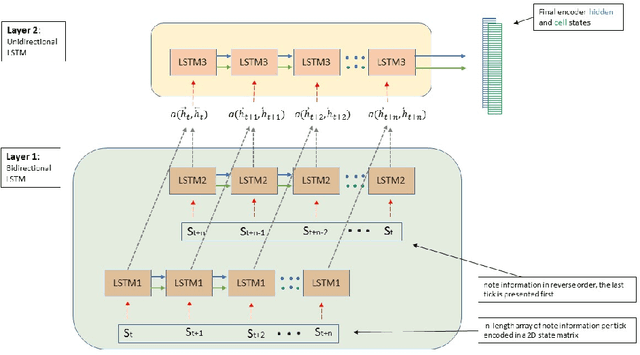
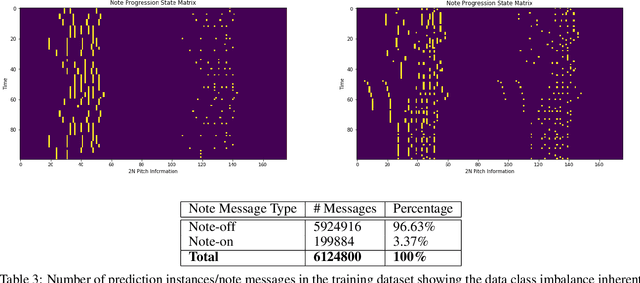
Algorithmic music composition is a way of composing musical pieces with minimal to no human intervention. While recurrent neural networks are traditionally applied to many sequence-to-sequence prediction tasks, including successful implementations of music composition, their standard supervised learning approach based on input-to-output mapping leads to a lack of note variety. These models can therefore be seen as potentially unsuitable for tasks such as music generation. Generative adversarial networks learn the generative distribution of data and lead to varied samples. This work implements and compares adversarial and non-adversarial training of recurrent neural network music composers on MIDI data. The resulting music samples are evaluated by human listeners, their preferences recorded. The evaluation indicates that adversarial training produces more aesthetically pleasing music.
Black-Box Saliency Map Generation Using Bayesian Optimisation
Jan 30, 2020

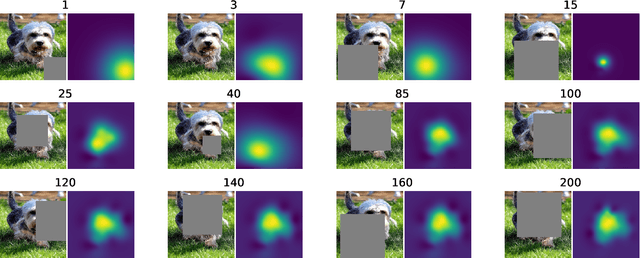
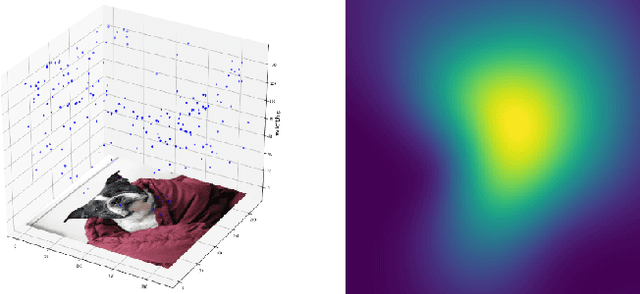
Saliency maps are often used in computer vision to provide intuitive interpretations of what input regions a model has used to produce a specific prediction. A number of approaches to saliency map generation are available, but most require access to model parameters. This work proposes an approach for saliency map generation for black-box models, where no access to model parameters is available, using a Bayesian optimisation sampling method. The approach aims to find the global salient image region responsible for a particular (black-box) model's prediction. This is achieved by a sampling-based approach to model perturbations that seeks to localise salient regions of an image to the black-box model. Results show that the proposed approach to saliency map generation outperforms grid-based perturbation approaches, and performs similarly to gradient-based approaches which require access to model parameters.
Loss Surface Modality of Feed-Forward Neural Network Architectures
May 24, 2019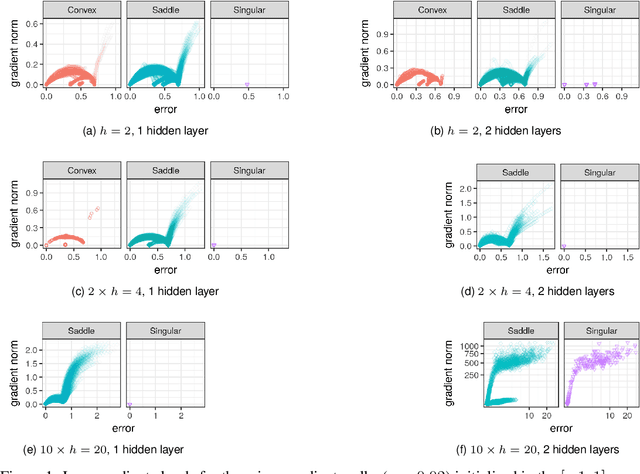
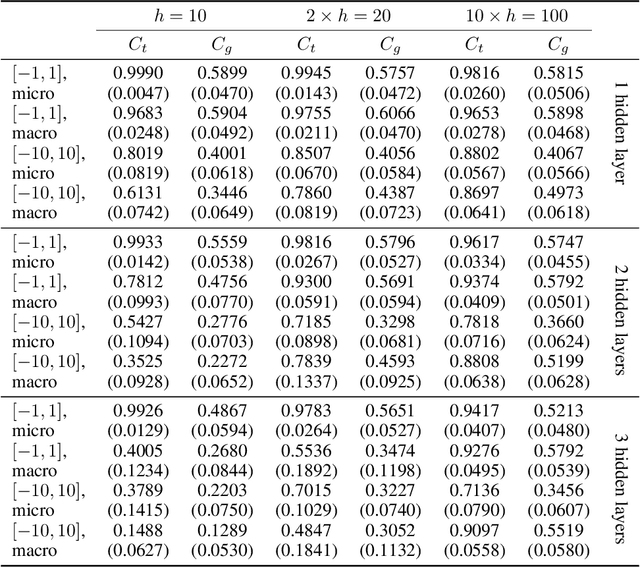
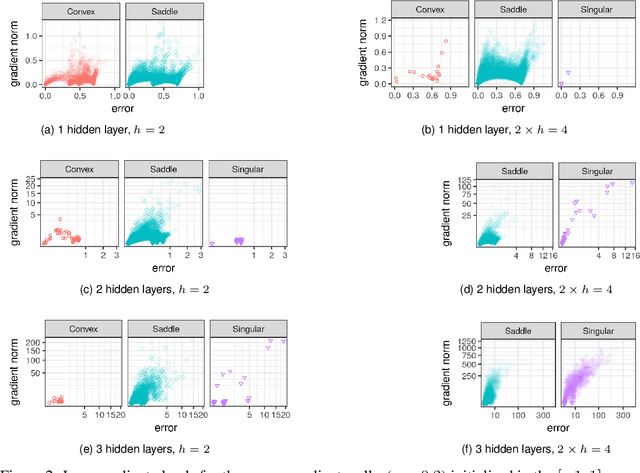
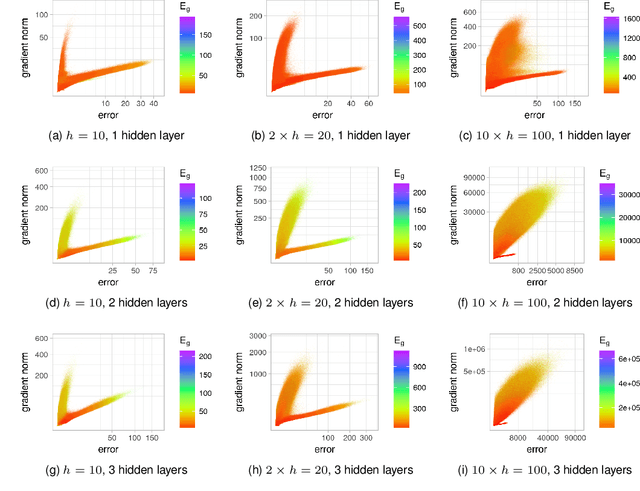
It has been argued in the past that high-dimensional neural networks do not exhibit local minima capable of trapping an optimisation algorithm. However, the relationship between loss surface modality and the neural architecture parameters, such as the number of hidden neurons per layer and the number of hidden layers, remains poorly understood. This study employs fitness landscape analysis to study the modality of neural network loss surfaces under various feed-forward architecture settings. An increase in the problem dimensionality is shown to yield a more searchable and more exploitable loss surface. An increase in the hidden layer width is shown to effectively reduce the number of local minima, and simplify the shape of the global attractor. An increase in the architecture depth is shown to sharpen the global attractor, thus making it more exploitable.