 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to be EXACT, Cell Detection for Asthma on Partially Annotated Whole Slide Images
Jan 13, 2021
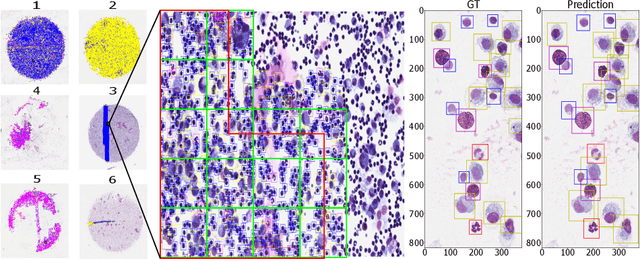
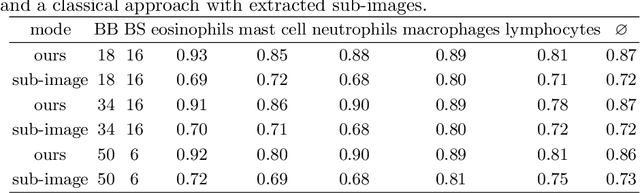
Asthma is a chronic inflammatory disorder of the lower respiratory tract and naturally occurs in humans and animals including horses. The annotation of an asthma microscopy whole slide image (WSI) is an extremely labour-intensive task due to the hundreds of thousands of cells per WSI. To overcome the limitation of annotating WSI incompletely, we developed a training pipeline which can train a deep learning-based object detection model with partially annotated WSIs and compensate class imbalances on the fly. With this approach we can freely sample from annotated WSIs areas and are not restricted to fully annotated extracted sub-images of the WSI as with classical approaches. We evaluated our pipeline in a cross-validation setup with a fixed training set using a dataset of six equine WSIs of which four are partially annotated and used for training, and two fully annotated WSI are used for validation and testing. Our WSI-based training approach outperformed classical sub-image-based training methods by up to 15\% $mAP$ and yielded human-like performance when compared to the annotations of ten trained pathologists.
Deep Learning-Based Quantification of Pulmonary Hemosiderophages in Cytology Slides
Aug 12, 2019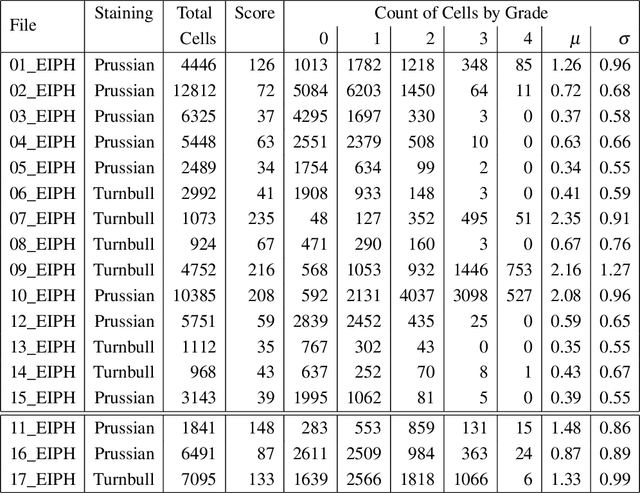
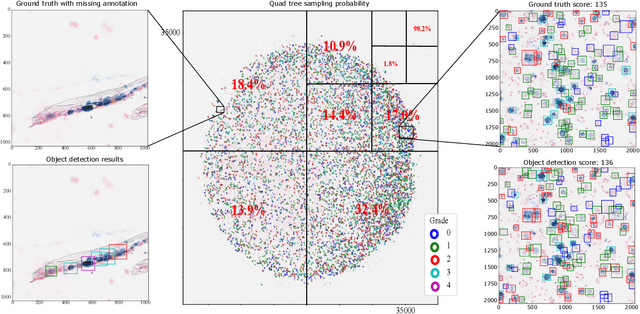
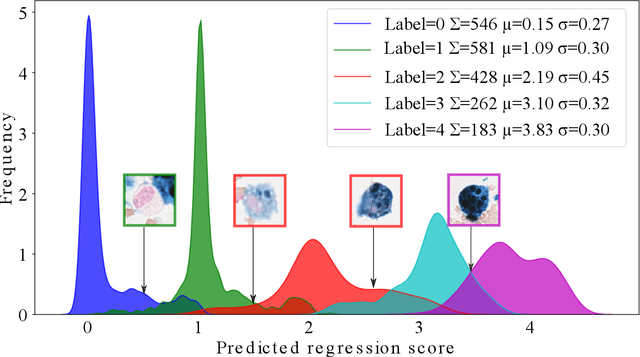
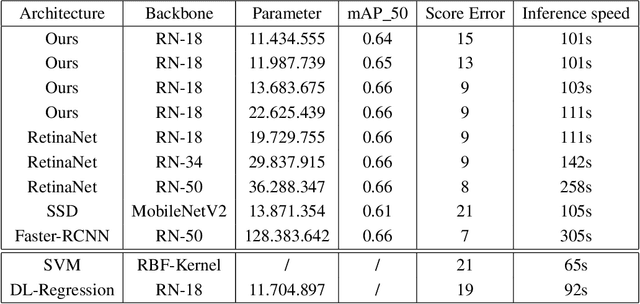
Purpose: Exercise-induced pulmonary hemorrhage (EIPH) is a common syndrome in sport horses with negative impact on performance. Cytology of bronchoalveolar lavage fluid by use of a scoring system is considered the most sensitive diagnostic method. Macrophages are classified depending on the degree of cytoplasmic hemosiderin content. The current gold standard is manual grading, which is however monotonous and time-consuming. Methods: We evaluated state-of-the-art deep learning-based methods for single cell macrophage classification and compared them against the performance of nine cytology experts and evaluated inter- and intra-observer variability. Additionally, we evaluated object detection methods on a novel data set of 17 completely annotated cytology whole slide images (WSI) containing 78,047 hemosiderophages. Resultsf: Our deep learning-based approach reached a concordance of 0.85, partially exceeding human expert concordance (0.68 to 0.86, $\mu$=0.73, $\sigma$ =0.04). Intra-observer variability was high (0.68 to 0.88) and inter-observer concordance was moderate (Fleiss kappa = 0.67). Our object detection approach has a mean average precision of 0.66 over the five classes from the whole slide gigapixel image and a computation time of below two minutes. Conclusion: To mitigate the high inter- and intra-rater variability, we propose our automated object detection pipeline, enabling accurate, reproducible and quick EIPH scoring in WSI.