 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding based Deep Learning
Jun 22, 2021

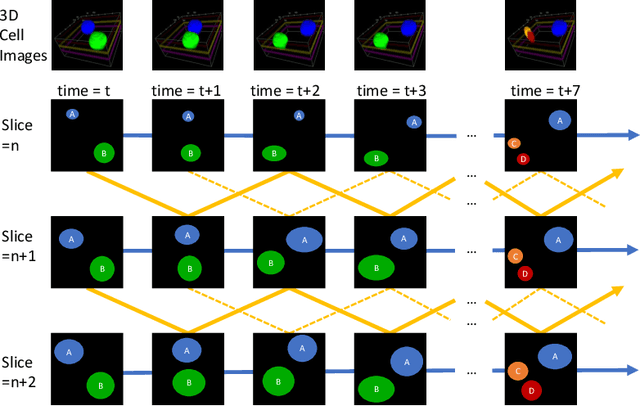

Recent advances in bioimaging have provided scientists a superior high spatial-temporal resolution to observe dynamics of living cells as 3D volumetric videos. Unfortunately, the 3D biomedical video analysis is lagging, impeded by resource insensitive human curation using off-the-shelf 3D analytic tools. Herein, biologists often need to discard a considerable amount of rich 3D spatial information by compromising on 2D analysis via maximum intensity projection. Recently, pixel embedding-based cell instance segmentation and tracking provided a neat and generalizable computing paradigm for understanding cellular dynamics. In this work, we propose a novel spatial-temporal voxel-embedding (VoxelEmbed) based learning method to perform simultaneous cell instance segmenting and tracking on 3D volumetric video sequences. Our contribution is in four-fold: (1) The proposed voxel embedding generalizes the pixel embedding with 3D context information; (2) Present a simple multi-stream learning approach that allows effective spatial-temporal embedding; (3) Accomplished an end-to-end framework for one-stage 3D cell instance segmentation and tracking without heavy parameter tuning; (4) The proposed 3D quantification is memory efficient via a single GPU with 12 GB memory. We evaluate our VoxelEmbed method on four 3D datasets (with different cell types) from the ISBI Cell Tracking Challenge. The proposed VoxelEmbed method achieved consistent superior overall performance (OP) on two densely annotated datasets. The performance is also competitive on two sparsely annotated cohorts with 20.6% and 2% of data-set having segmentation annotations. The results demonstrate that the VoxelEmbed method is a generalizable and memory-efficient solution.
Towards Annotation-free Instance Segmentation and Tracking with Adversarial Simulations
Jan 19, 2021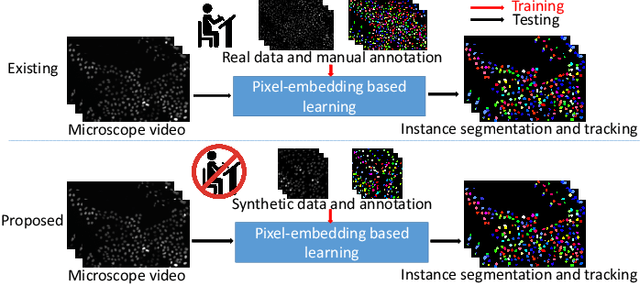

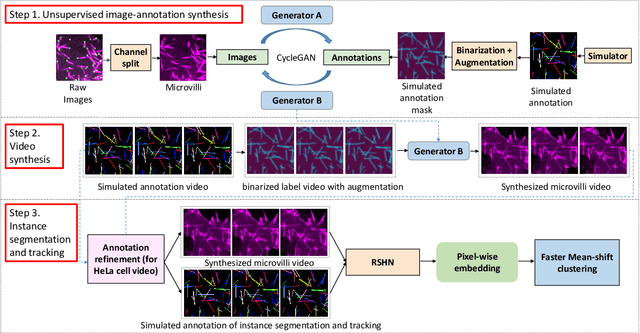

The quantitative analysis of microscope videos often requires instance segmentation and tracking of cellular and subcellular objects. The traditional method is composed of two stages: (1) performing instance object segmentation of each frame, and (2) associating objects frame-by-frame. Recently, pixel-embedding-based deep learning approaches provide single stage holistic solutions to tackle instance segmentation and tracking simultaneously. However, such deep learning methods require consistent annotations not only spatially (for segmentation), but also temporally (for tracking). In computer vision, annotated training data with consistent segmentation and tracking is resource intensive, the severity of which can be multiplied in microscopy imaging due to (1) dense objects (e.g., overlapping or touching), and (2) high dynamics (e.g., irregular motion and mitosis). To alleviate the lack of such annotations in dynamics scenes, adversarial simulations have provided successful solutions in computer vision, such as using simulated environments (e.g., computer games) to train real-world self-driving systems. In this paper, we propose an annotation-free synthetic instance segmentation and tracking (ASIST) method with adversarial simulation and single-stage pixel-embedding based learning. The contribution of this paper is three-fold: (1) the proposed method aggregates adversarial simulations and single-stage pixel-embedding based deep learning; (2) the method is assessed with both the cellular (i.e., HeLa cells) and subcellular (i.e., microvilli) objects; and (3) to the best of our knowledge, this is the first study to explore annotation-free instance segmentation and tracking study for microscope videos. This ASIST method achieved an important step forward, when compared with fully supervised approaches.
ASIST: Annotation-free synthetic instance segmentation and tracking for microscope video analysis
Nov 02, 2020
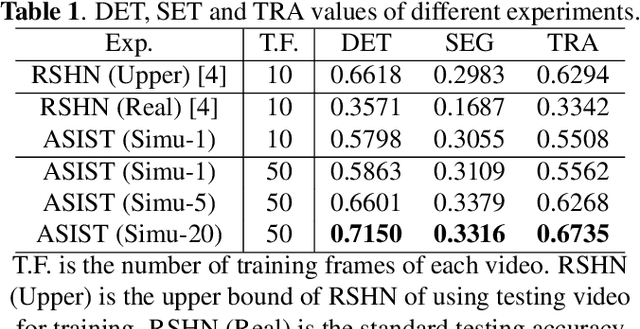
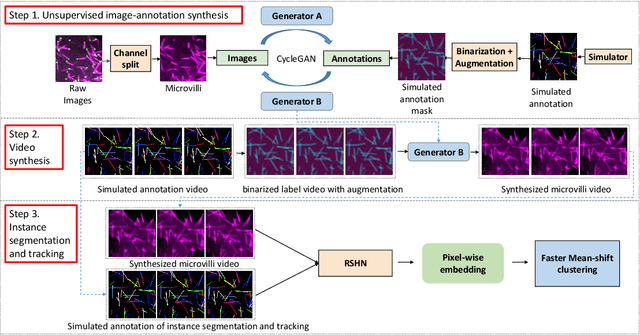
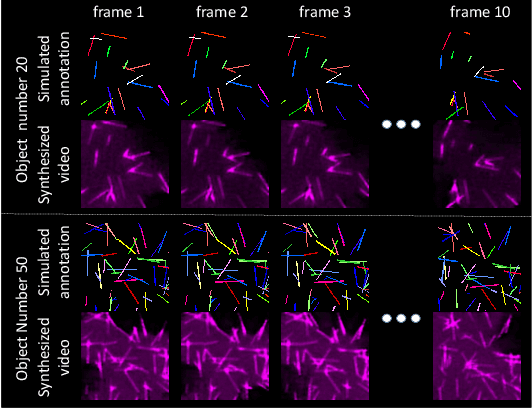
Instance object segmentation and tracking provide comprehensive quantification of objects across microscope videos. The recent single-stage pixel-embedding based deep learning approach has shown its superior performance compared with "segment-then-associate" two-stage solutions. However, one major limitation of applying a supervised pixel-embedding based method to microscope videos is the resource-intensive manual labeling, which involves tracing hundreds of overlapped objects with their temporal associations across video frames. Inspired by the recent generative adversarial network (GAN) based annotation-free image segmentation, we propose a novel annotation-free synthetic instance segmentation and tracking (ASIST) algorithm for analyzing microscope videos of sub-cellular microvilli. The contributions of this paper are three-fold: (1) proposing a new annotation-free video analysis paradigm is proposed. (2) aggregating the embedding based instance segmentation and tracking with annotation-free synthetic learning as a holistic framework; and (3) to the best of our knowledge, this is first study to investigate microvilli instance segmentation and tracking using embedding based deep learning. From the experimental results, the proposed annotation-free method achieved superior performance compared with supervised learning.
Faster Mean-shift: GPU-accelerated Embedding-clustering for Cell Segmentation and Tracking
Jul 28, 2020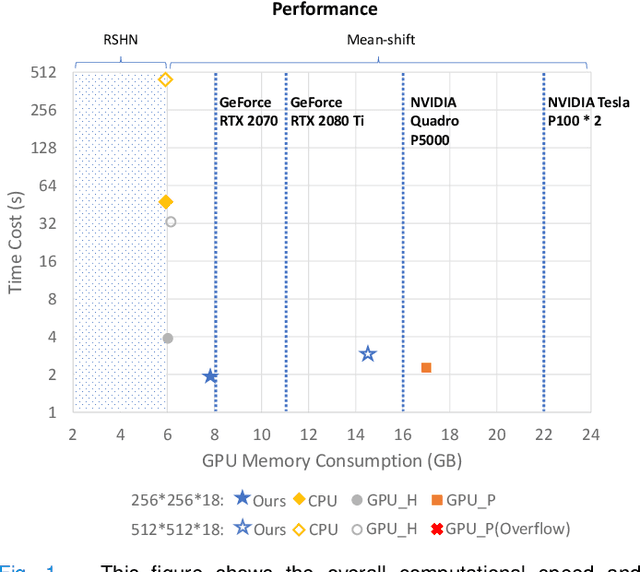
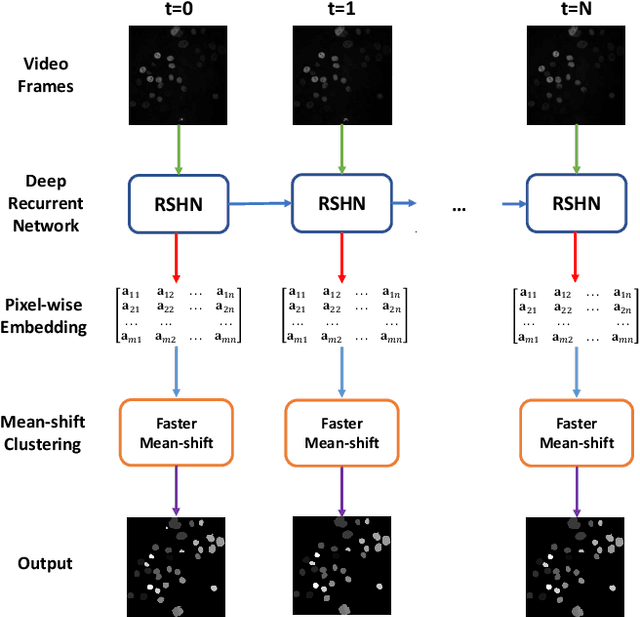

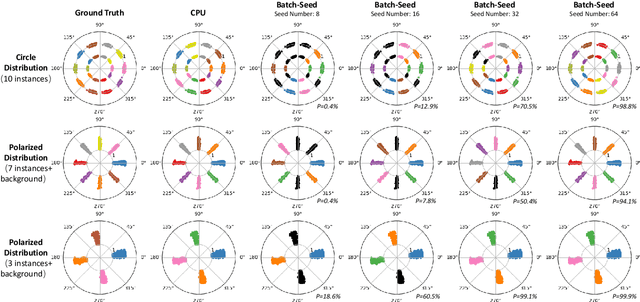
Recently, single-stage embedding based deep learning algorithms gain increasing attention in cell segmentation and tracking. Compared with the traditional "segment-then-associate" two-stage approach, a single-stage algorithm not only simultaneously achieves consistent instance cell segmentation and tracking but also gains superior performance when distinguishing ambiguous pixels on boundaries and overlapped objects. However, the deployment of an embedding based algorithm is restricted by slow inference speed (e.g., around 1-2 mins per frame). In this study, we propose a novel Faster Mean-shift algorithm, which tackles the computational bottleneck of embedding based cell segmentation and tracking. Different from previous GPU-accelerated fast mean-shift algorithms, a new online seed optimization policy (OSOP) is introduced to adaptively determine the minimal number of seeds, accelerate computation, and save GPU memory. With both embedding simulation and empirical validation via the four cohorts from the ISBI cell tracking challenge, the proposed Faster Mean-shift algorithm achieved 7-10 times speedup compared to the state-of-the-art embedding based cell instance segmentation and tracking algorithm. Our Faster Mean-shift algorithm also achieved the highest computational speed compared to other GPU benchmarks with optimized memory consumption. The Faster Mean-shift is a plug-and-play model, which can be employed on other pixel embedding based clustering inference for medical image analysis.