 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement and Imitation Learning for Diverse Visuomotor Skills
May 27, 2018

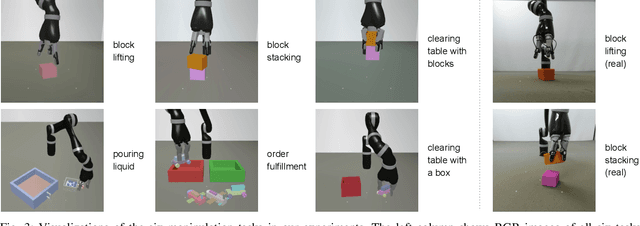
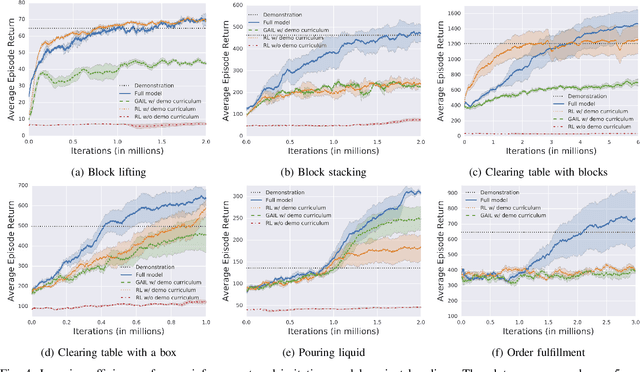
We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. We demonstrate that our approach can solve a wide variety of visuomotor tasks, for which engineering a scripted controller would be laborious. In experiments, our reinforcement and imitation agent achieves significantly better performances than agents trained with reinforcement learning or imitation learning alone. We also illustrate that these policies, trained with large visual and dynamics variations, can achieve preliminary successes in zero-shot sim2real transfer. A brief visual description of this work can be viewed in https://youtu.be/EDl8SQUNjj0