 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibrantSR: Sub-Meter Canopy Height Models from Sentinel-2 Using Generative Flow Matching
Jan 14, 2026We present VibrantSR (Vibrant Super-Resolution), a generative super-resolution framework for estimating 0.5 meter canopy height models (CHMs) from 10 meter Sentinel-2 imagery. Unlike approaches based on aerial imagery that are constrained by infrequent and irregular acquisition schedules, VibrantSR leverages globally available Sentinel-2 seasonal composites, enabling consistent monitoring at a seasonal-to-annual cadence. Evaluated across 22 EPA Level 3 eco-regions in the western United States using spatially disjoint validation splits, VibrantSR achieves a Mean Absolute Error of 4.39 meters for canopy heights >= 2 m, outperforming Meta (4.83 m), LANDFIRE (5.96 m), and ETH (7.05 m) satellite-based benchmarks. While aerial-based VibrantVS (2.71 m MAE) retains an accuracy advantage, VibrantSR enables operational forest monitoring and carbon accounting at continental scales without reliance on costly and temporally infrequent aerial acquisitions.
VibrantVS: A high-resolution multi-task transformer for forest canopy height estimation
Dec 13, 2024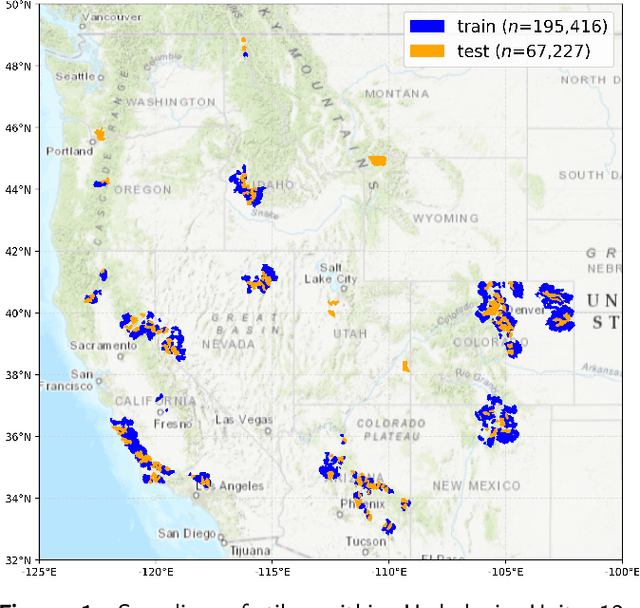
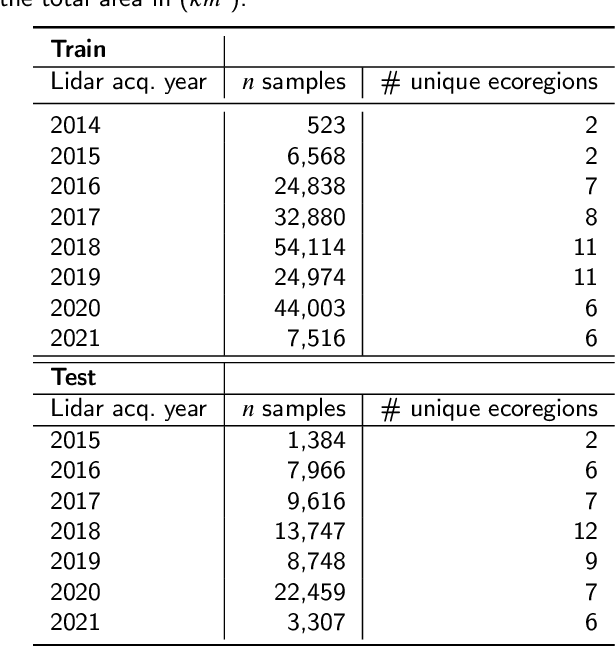
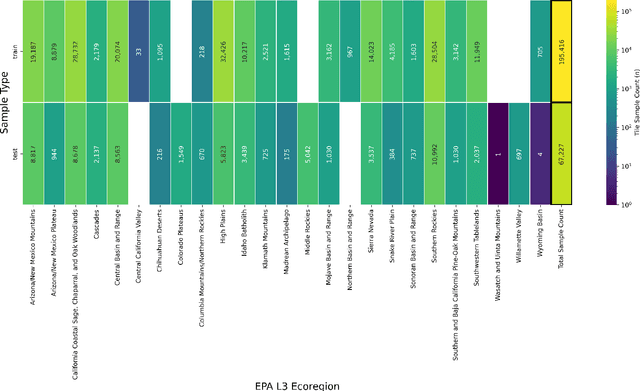
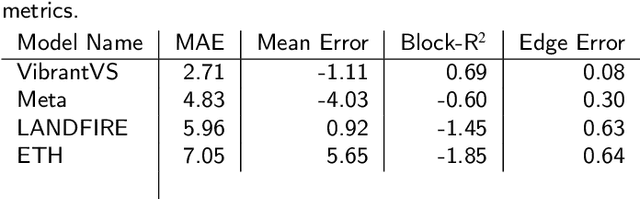
This paper explores the application of a novel multi-task vision transformer (ViT) model for the estimation of canopy height models (CHMs) using 4-band National Agriculture Imagery Program (NAIP) imagery across the western United States. We compare the effectiveness of this model in terms of accuracy and precision aggregated across ecoregions and class heights versus three other benchmark peer-reviewed models. Key findings suggest that, while other benchmark models can provide high precision in localized areas, the VibrantVS model has substantial advantages across a broad reach of ecoregions in the western United States with higher accuracy, higher precision, the ability to generate updated inference at a cadence of three years or less, and high spatial resolution. The VibrantVS model provides significant value for ecological monitoring and land management decisions for wildfire mitigation.
Mapping the world population one building at a time
Dec 15, 2017
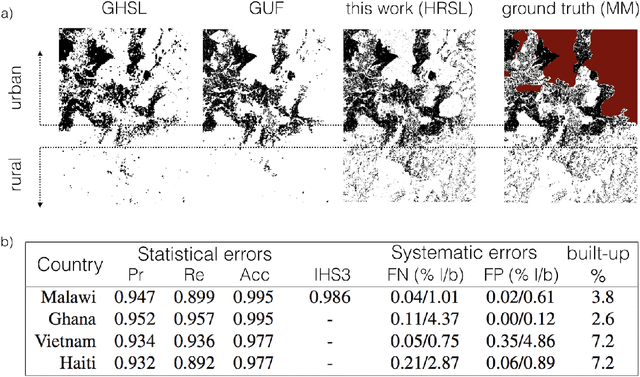
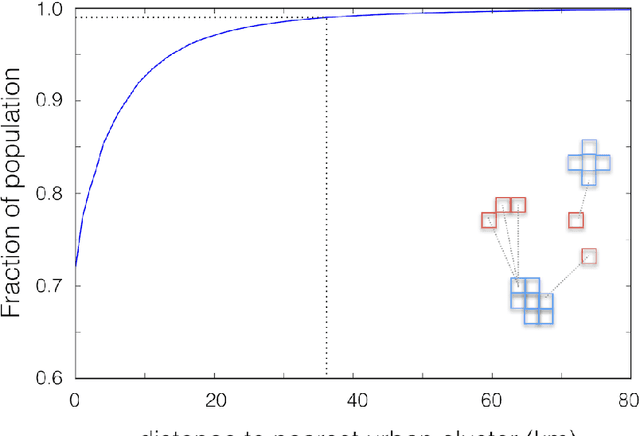
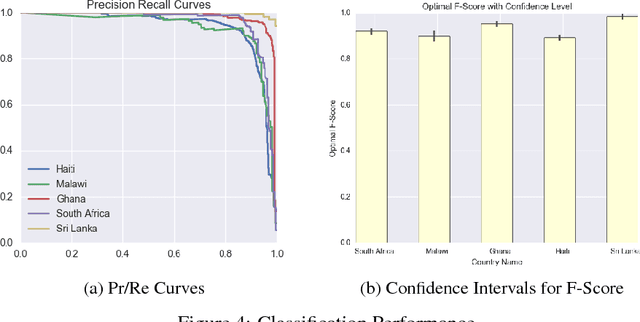
High resolution datasets of population density which accurately map sparsely-distributed human populations do not exist at a global scale. Typically, population data is obtained using censuses and statistical modeling. More recently, methods using remotely-sensed data have emerged, capable of effectively identifying urbanized areas. Obtaining high accuracy in estimation of population distribution in rural areas remains a very challenging task due to the simultaneous requirements of sufficient sensitivity and resolution to detect very sparse populations through remote sensing as well as reliable performance at a global scale. Here, we present a computer vision method based on machine learning to create population maps from satellite imagery at a global scale, with a spatial sensitivity corresponding to individual buildings and suitable for global deployment. By combining this settlement data with census data, we create population maps with ~30 meter resolution for 18 countries. We validate our method, and find that the building identification has an average precision and recall of 0.95 and 0.91, respectively and that the population estimates have a standard error of a factor ~2 or less. Based on our data, we analyze 29 percent of the world population, and show that 99 percent lives within 36 km of the nearest urban cluster. The resulting high-resolution population datasets have applications in infrastructure planning, vaccination campaign planning, disaster response efforts and risk analysis such as high accuracy flood risk analysis.
Building Detection from Satellite Images on a Global Scale
Jul 27, 2017


In the last several years, remote sensing technology has opened up the possibility of performing large scale building detection from satellite imagery. Our work is some of the first to create population density maps from building detection on a large scale. The scale of our work on population density estimation via high resolution satellite images raises many issues, that we will address in this paper. The first was data acquisition. Labeling buildings from satellite images is a hard problem, one where we found our labelers to only be about 85% accurate at. There is a tradeoff of quantity vs. quality of labels, so we designed two separate policies for labels meant for training sets and those meant for test sets, since our requirements of the two set types are quite different. We also trained weakly supervised footprint detection models with the classification labels, and semi-supervised approaches with a small number of pixel-level labels, which are very expensive to procure.
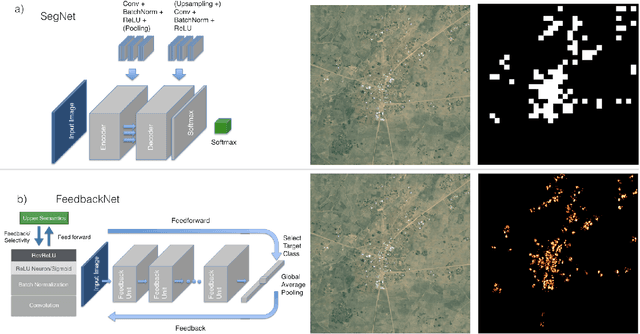
Feedback Neural Network for Weakly Supervised Geo-Semantic Segmentation
Dec 08, 2016

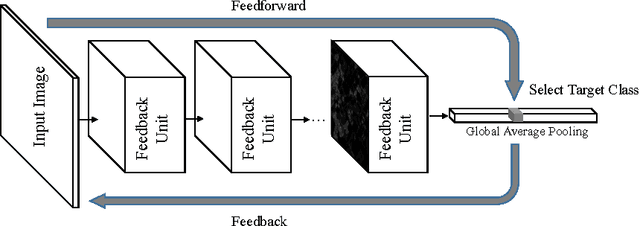

Learning from weakly-supervised data is one of the main challenges in machine learning and computer vision, especially for tasks such as image semantic segmentation where labeling is extremely expensive and subjective. In this paper, we propose a novel neural network architecture to perform weakly-supervised learning by suppressing irrelevant neuron activations. It localizes objects of interest by learning from image-level categorical labels in an end-to-end manner. We apply this algorithm to a practical challenge of transforming satellite images into a map of settlements and individual buildings. Experimental results show that the proposed algorithm achieves superior performance and efficiency when compared with various baseline models.
Sentiment in New York City: A High Resolution Spatial and Temporal View
Aug 22, 2013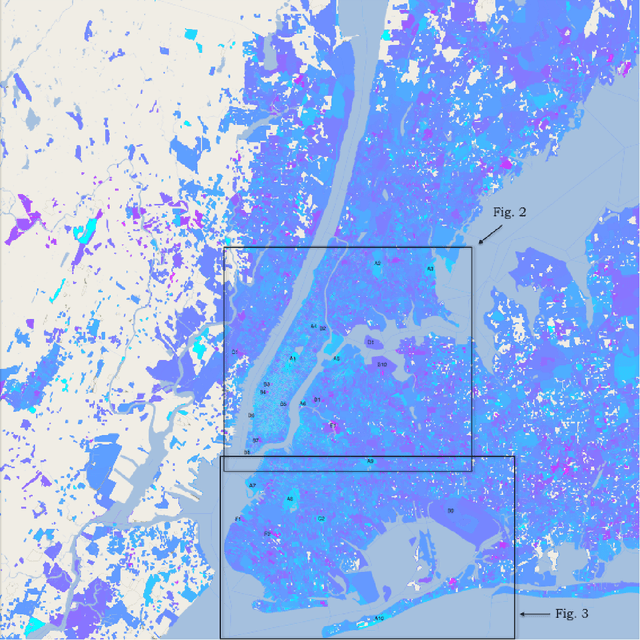
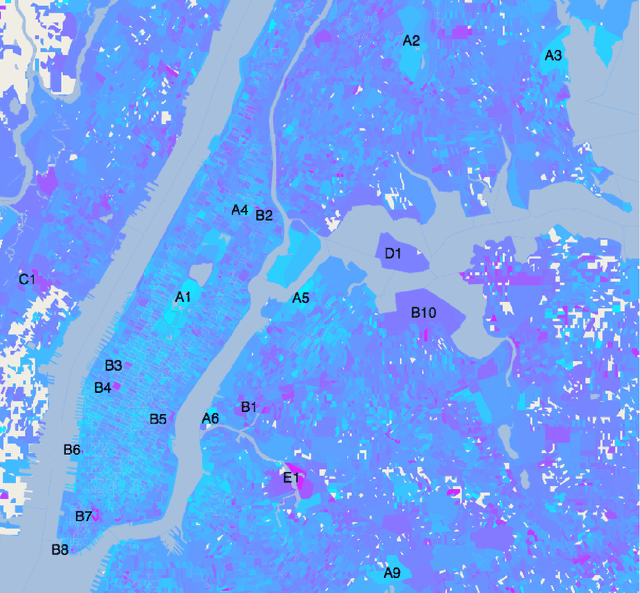
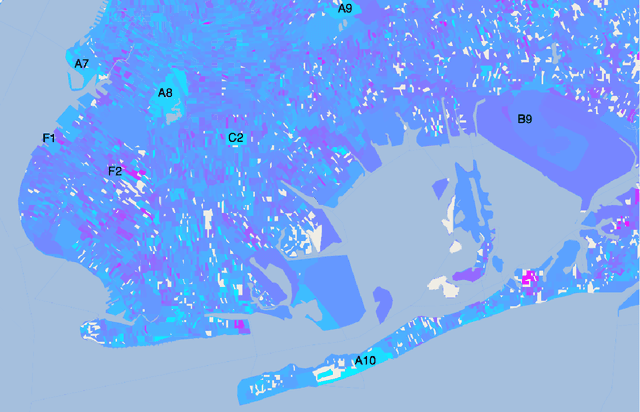

Measuring public sentiment is a key task for researchers and policymakers alike. The explosion of available social media data allows for a more time-sensitive and geographically specific analysis than ever before. In this paper we analyze data from the micro-blogging site Twitter and generate a sentiment map of New York City. We develop a classifier specifically tuned for 140-character Twitter messages, or tweets, using key words, phrases and emoticons to determine the mood of each tweet. This method, combined with geotagging provided by users, enables us to gauge public sentiment on extremely fine-grained spatial and temporal scales. We find that public mood is generally highest in public parks and lowest at transportation hubs, and locate other areas of strong sentiment such as cemeteries, medical centers, a jail, and a sewage facility. Sentiment progressively improves with proximity to Times Square. Periodic patterns of sentiment fluctuate on both a daily and a weekly scale: more positive tweets are posted on weekends than on weekdays, with a daily peak in sentiment around midnight and a nadir between 9:00 a.m. and noon.