 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegregation Dynamics with Reinforcement Learning and Agent Based Modeling
Sep 18, 2019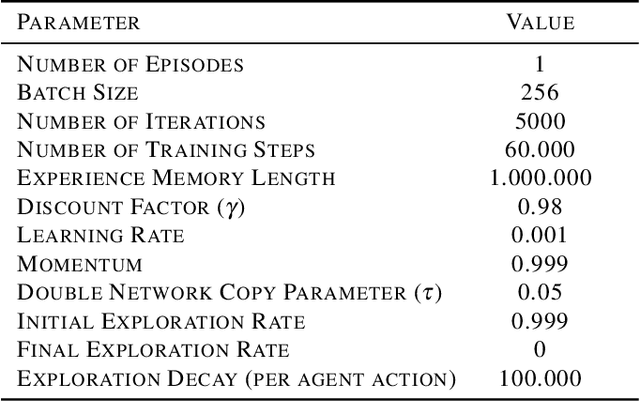
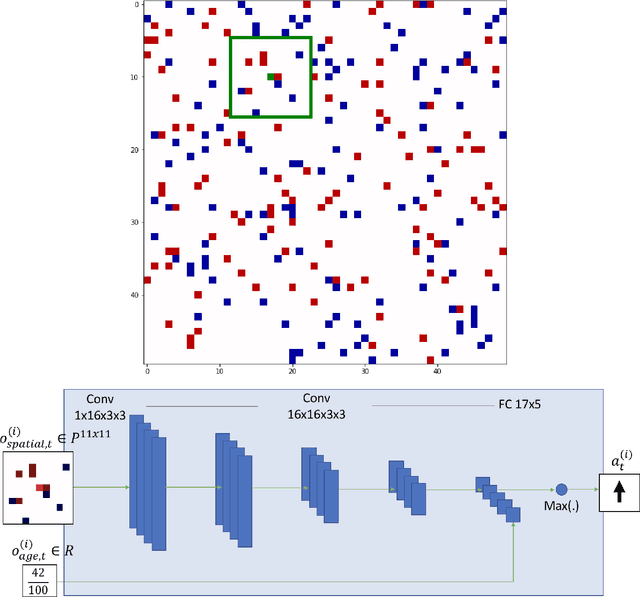
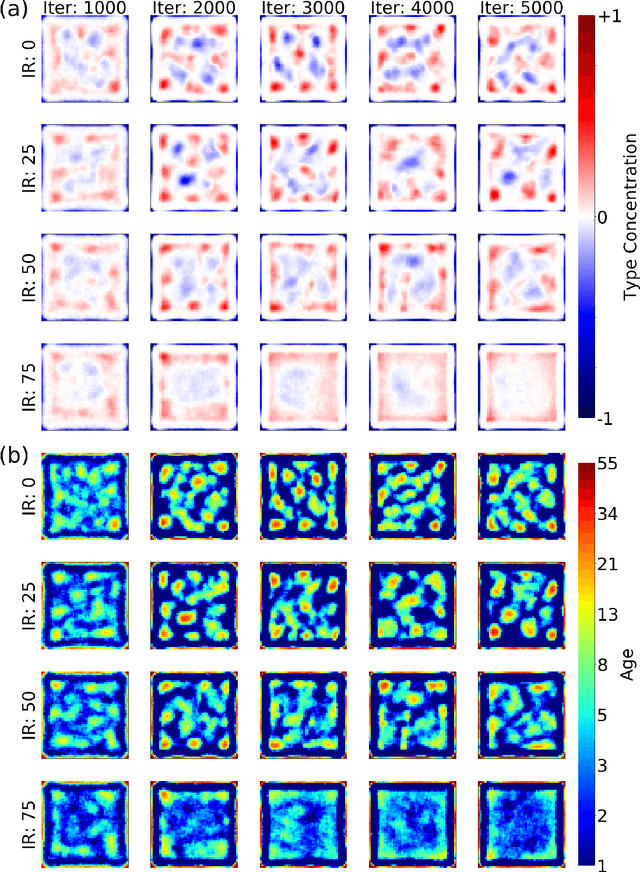
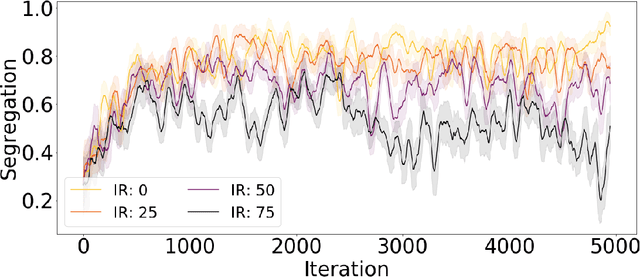
Societies are complex. Properties of social systems can be explained by the interplay and weaving of individual actions. Incentives are key to understand people's choices and decisions. For instance, individual preferences of where to live may lead to the emergence of social segregation. In this paper, we combine Reinforcement Learning (RL) with Agent Based Models (ABM) in order to address the self-organizing dynamics of social segregation and explore the space of possibilities that emerge from considering different types of incentives. Our model promotes the creation of interdependencies and interactions among multiple agents of two different kinds that want to segregate from each other. For this purpose, agents use Deep Q-Networks to make decisions based on the rules of the Schelling Segregation model and the Predator-Prey model. Despite the segregation incentive, our experiments show that spatial integration can be achieved by establishing interdependencies among agents of different kinds. They also reveal that segregated areas are more probable to host older people than diverse areas, which attract younger ones. Through this work, we show that the combination of RL and ABMs can create an artificial environment for policy makers to observe potential and existing behaviors associated to incentives.
How Do People Differ? A Social Media Approach
Aug 09, 2017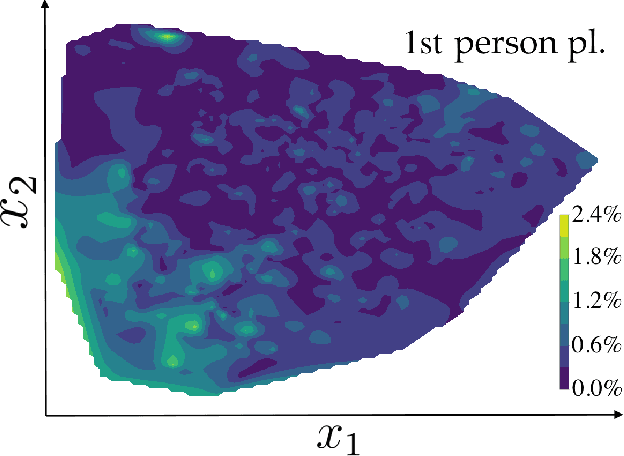
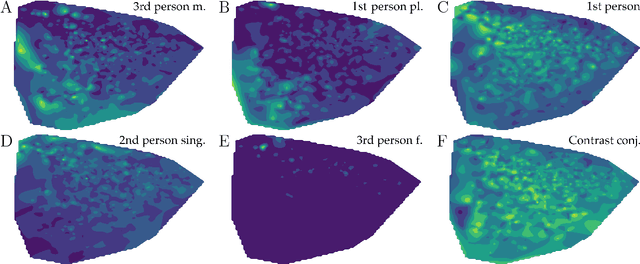
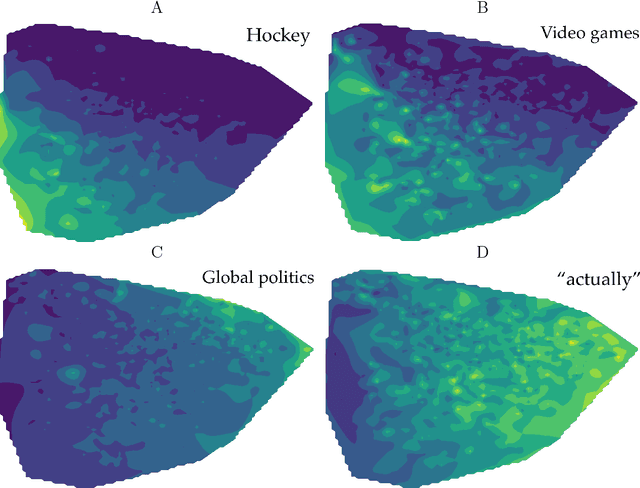
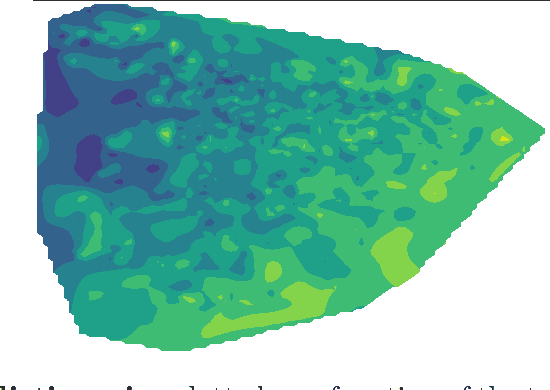
Research from a variety of fields including psychology and linguistics have found correlations and patterns in personal attributes and behavior, but efforts to understand the broader heterogeneity in human behavior have not yet integrated these approaches and perspectives with a cohesive methodology. Here we extract patterns in behavior and relate those patterns together in a high-dimensional picture. We use dimension reduction to analyze word usage in text data from the online discussion platform Reddit. We find that pronouns can be used to characterize the space of the two most prominent dimensions that capture the greatest differences in word usage, even though pronouns were not included in the determination of those dimensions. These patterns overlap with patterns of topics of discussion to reveal relationships between pronouns and topics that can describe the user population. This analysis corroborates findings from past research that have identified word use differences across populations and synthesizes them relative to one another. We believe this is a step toward understanding how differences between people are related to each other.
Sentiment in New York City: A High Resolution Spatial and Temporal View
Aug 22, 2013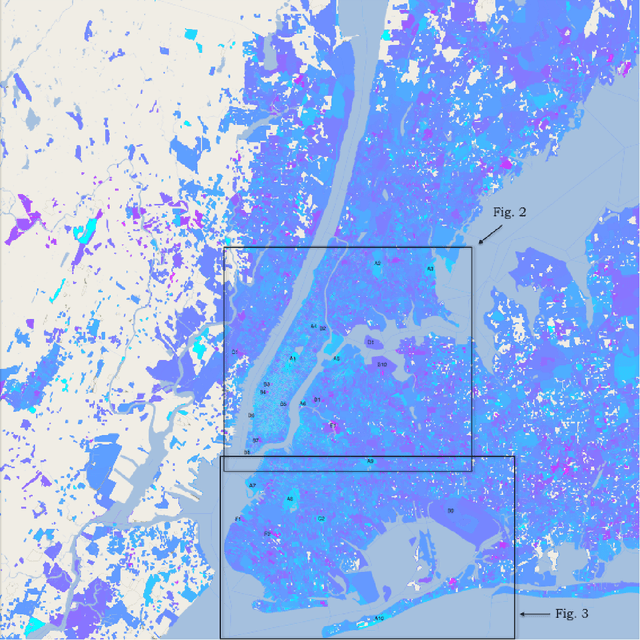
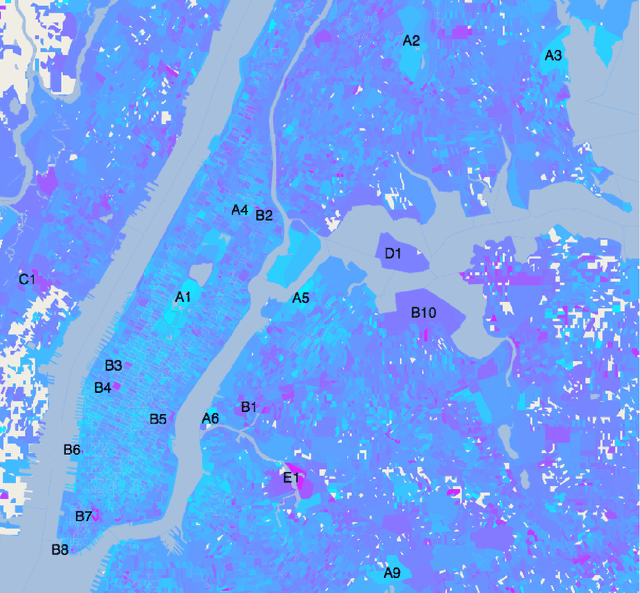
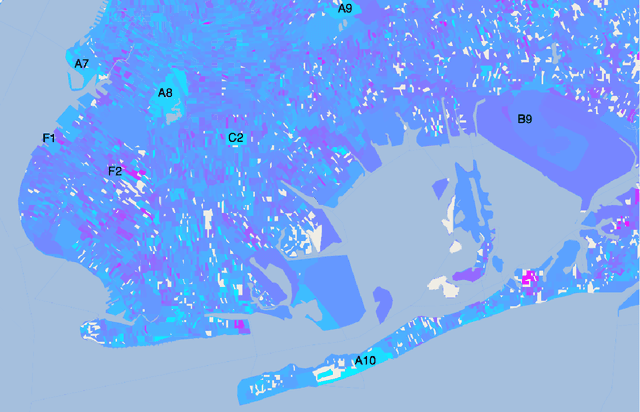

Measuring public sentiment is a key task for researchers and policymakers alike. The explosion of available social media data allows for a more time-sensitive and geographically specific analysis than ever before. In this paper we analyze data from the micro-blogging site Twitter and generate a sentiment map of New York City. We develop a classifier specifically tuned for 140-character Twitter messages, or tweets, using key words, phrases and emoticons to determine the mood of each tweet. This method, combined with geotagging provided by users, enables us to gauge public sentiment on extremely fine-grained spatial and temporal scales. We find that public mood is generally highest in public parks and lowest at transportation hubs, and locate other areas of strong sentiment such as cemeteries, medical centers, a jail, and a sewage facility. Sentiment progressively improves with proximity to Times Square. Periodic patterns of sentiment fluctuate on both a daily and a weekly scale: more positive tweets are posted on weekends than on weekdays, with a daily peak in sentiment around midnight and a nadir between 9:00 a.m. and noon.