 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-to-event prediction for grouped variables using Exclusive Lasso
Apr 02, 2025


The integration of high-dimensional genomic data and clinical data into time-to-event prediction models has gained significant attention due to the growing availability of these datasets. Traditionally, a Cox regression model is employed, concatenating various covariate types linearly. Given that much of the data may be redundant or irrelevant, feature selection through penalization is often desirable. A notable characteristic of these datasets is their organization into blocks of distinct data types, such as methylation and clinical predictors, which requires selecting a subset of covariates from each group due to high intra-group correlations. For this reason, we propose utilizing Exclusive Lasso regularization in place of standard Lasso penalization. We apply our methodology to a real-life cancer dataset, demonstrating enhanced survival prediction performance compared to the conventional Cox regression model.
A Machine Learning-based Anomaly Detection Framework in Life Insurance Contracts
Nov 26, 2024Life insurance, like other forms of insurance, relies heavily on large volumes of data. The business model is based on an exchange where companies receive payments in return for the promise to provide coverage in case of an accident. Thus, trust in the integrity of the data stored in databases is crucial. One method to ensure data reliability is the automatic detection of anomalies. While this approach is highly useful, it is also challenging due to the scarcity of labeled data that distinguish between normal and anomalous contracts or inter\-actions. This manuscript discusses several classical and modern unsupervised anomaly detection methods and compares their performance across two different datasets. In order to facilitate the adoption of these methods by companies, this work also explores ways to automate the process, making it accessible even to non-data scientists.
Churn modeling of life insurance policies via statistical and machine learning methods -- Analysis of important features
Feb 18, 2022
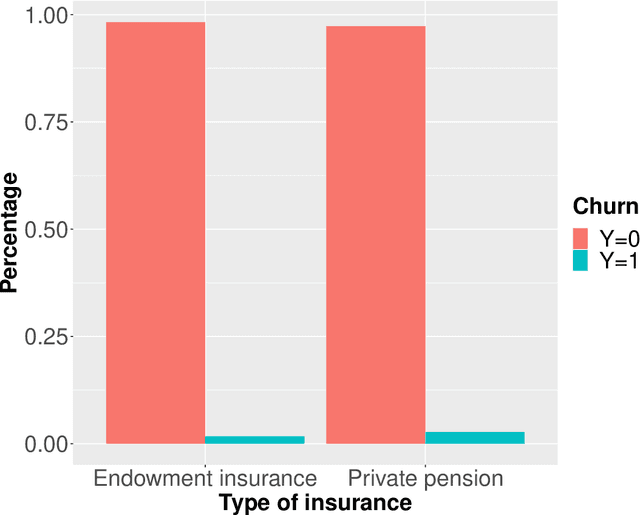
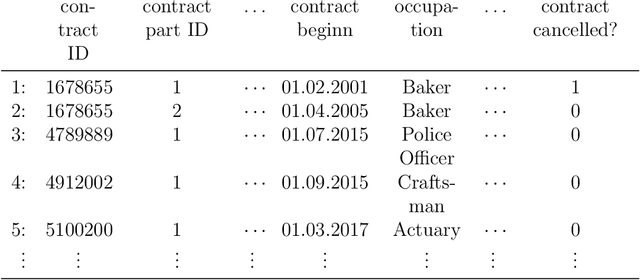

Life assurance companies typically possess a wealth of data covering multiple systems and databases. These data are often used for analyzing the past and for describing the present. Taking account of the past, the future is mostly forecasted by traditional statistical methods. So far, only a few attempts were undertaken to perform estimations by means of machine learning approaches. In this work, the individual contract cancellation behavior of customers within two partial stocks is modeled by the aid of various classification methods. Partial stocks of private pension and endowment policy are considered. We describe the data used for the modeling, their structured and in which way they are cleansed. The utilized models are calibrated on the basis of an extensive tuning process, then graphically evaluated regarding their goodness-of-fit and with the help of a variable relevance concept, we investigate which features notably affect the individual contract cancellation behavior.
Machine Learning for Multi-Output Regression: When should a holistic multivariate approach be preferred over separate univariate ones?
Jan 14, 2022
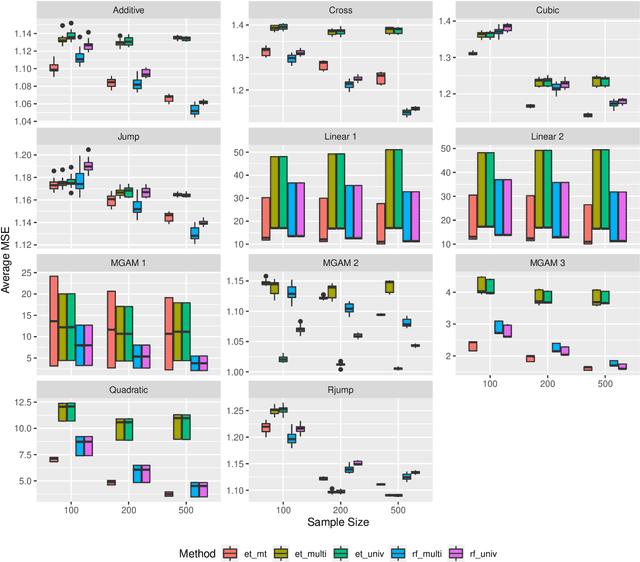
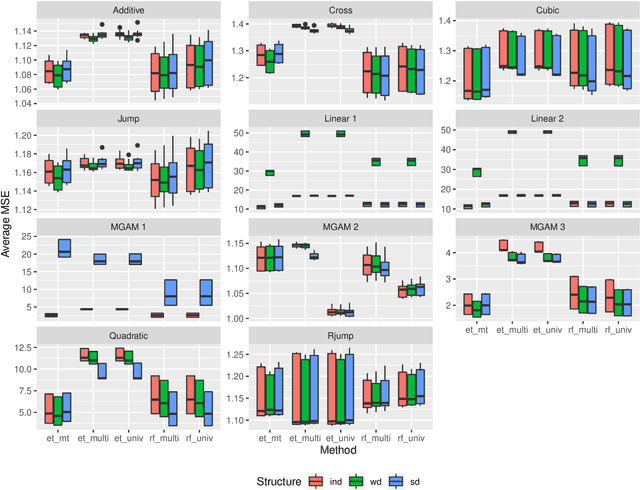
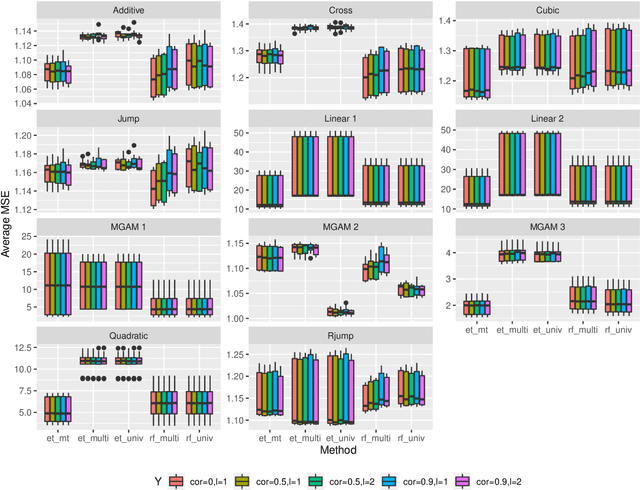
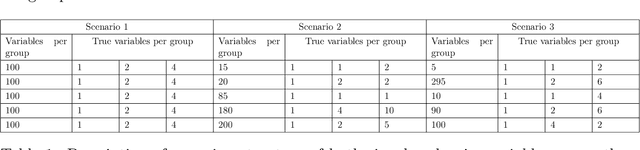
Tree-based ensembles such as the Random Forest are modern classics among statistical learning methods. In particular, they are used for predicting univariate responses. In case of multiple outputs the question arises whether we separately fit univariate models or directly follow a multivariate approach. For the latter, several possibilities exist that are, e.g. based on modified splitting or stopping rules for multi-output regression. In this work we compare these methods in extensive simulations to help in answering the primary question when to use multivariate ensemble techniques.
Hybrid Machine Learning Forecasts for the UEFA EURO 2020
Jun 07, 2021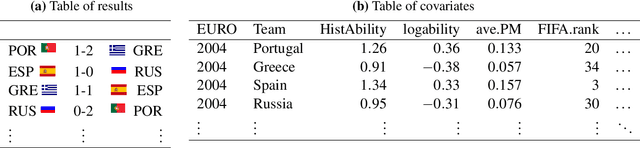
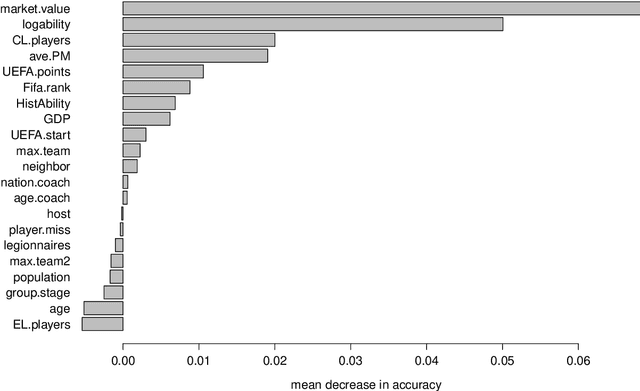
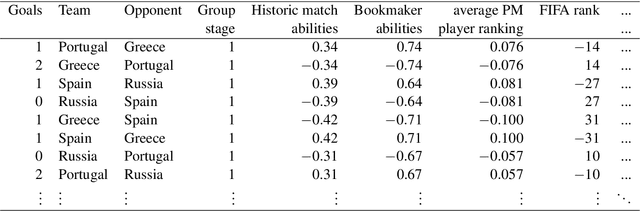
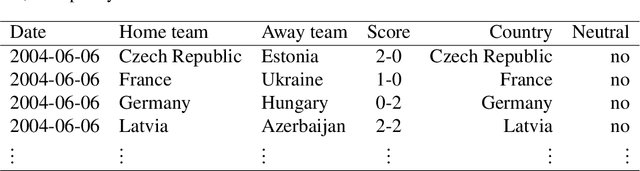
Three state-of-the-art statistical ranking methods for forecasting football matches are combined with several other predictors in a hybrid machine learning model. Namely an ability estimate for every team based on historic matches; an ability estimate for every team based on bookmaker consensus; average plus-minus player ratings based on their individual performances in their home clubs and national teams; and further team covariates (e.g., market value, team structure) and country-specific socio-economic factors (population, GDP). The proposed combined approach is used for learning the number of goals scored in the matches from the four previous UEFA EUROs 2004-2016 and then applied to current information to forecast the upcoming UEFA EURO 2020. Based on the resulting estimates, the tournament is simulated repeatedly and winning probabilities are obtained for all teams. A random forest model favors the current World Champion France with a winning probability of 14.8% before England (13.5%) and Spain (12.3%). Additionally, we provide survival probabilities for all teams and at all tournament stages.
Deducing neighborhoods of classes from a fitted model
Sep 17, 2020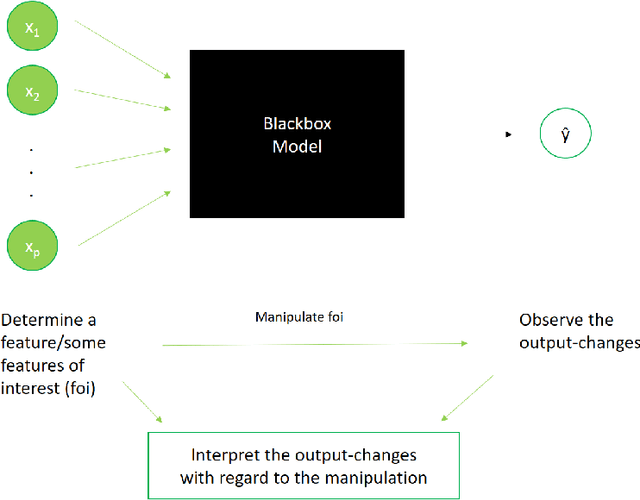

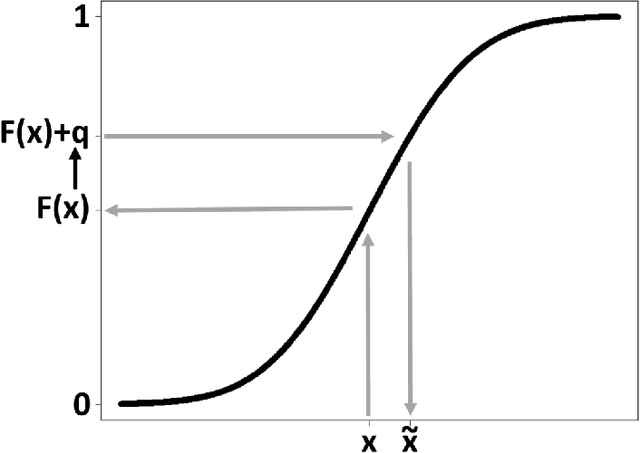

In todays world the request for very complex models for huge data sets is rising steadily. The problem with these models is that by raising the complexity of the models, it gets much harder to interpret them. The growing field of \emph{interpretable machine learning} tries to make up for the lack of interpretability in these complex (or even blackbox-)models by using specific techniques that can help to understand those models better. In this article a new kind of interpretable machine learning method is presented, which can help to understand the partitioning of the feature space into predicted classes in a classification model using quantile shifts. To illustrate in which situations this quantile shift method (QSM) could become beneficial, it is applied to a theoretical medical example and a real data example. Basically, real data points (or specific points of interest) are used and the changes of the prediction after slightly raising or decreasing specific features are observed. By comparing the predictions before and after the manipulations, under certain conditions the observed changes in the predictions can be interpreted as neighborhoods of the classes with regard to the manipulated features. Chordgraphs are used to visualize the observed changes.
Random boosting and random^2 forests -- A random tree depth injection approach
Sep 13, 2020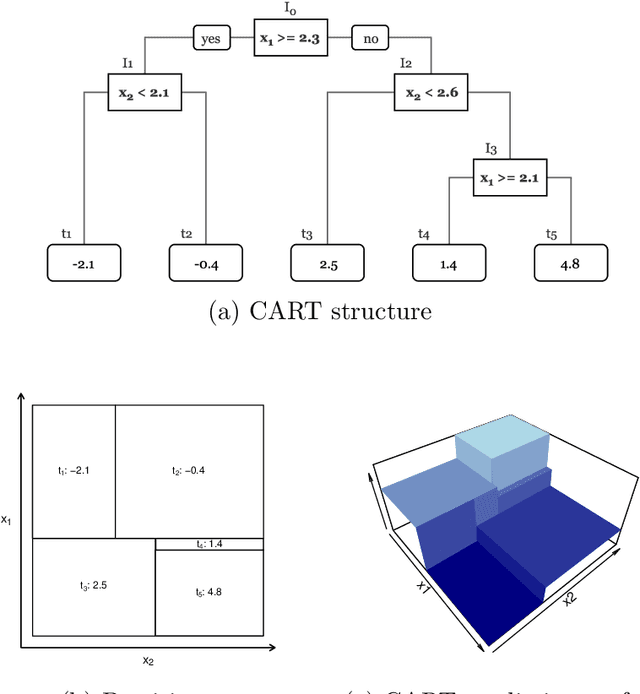
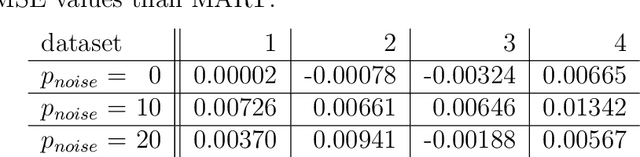
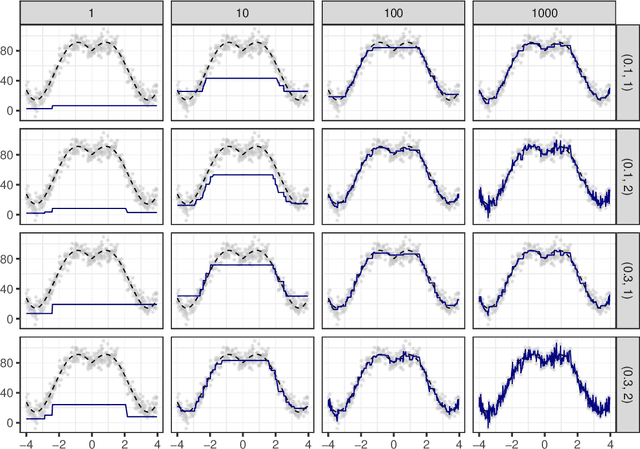
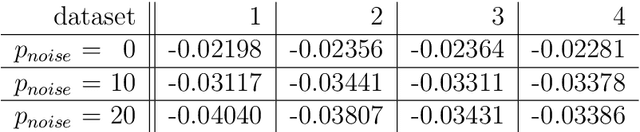
The induction of additional randomness in parallel and sequential ensemble methods has proven to be worthwhile in many aspects. In this manuscript, we propose and examine a novel random tree depth injection approach suitable for sequential and parallel tree-based approaches including Boosting and Random Forests. The resulting methods are called \emph{Random Boost} and \emph{Random$^2$ Forest}. Both approaches serve as valuable extensions to the existing literature on the gradient boosting framework and random forests. A Monte Carlo simulation, in which tree-shaped data sets with different numbers of final partitions are built, suggests that there are several scenarios where \emph{Random Boost} and \emph{Random$^2$ Forest} can improve the prediction performance of conventional hierarchical boosting and random forest approaches. The new algorithms appear to be especially successful in cases where there are merely a few high-order interactions in the generated data. In addition, our simulations suggest that our random tree depth injection approach can improve computation time by up to 40%, while at the same time the performance losses in terms of prediction accuracy turn out to be minor or even negligible in most cases.
Hybrid Machine Learning Forecasts for the FIFA Women's World Cup 2019
Jun 03, 2019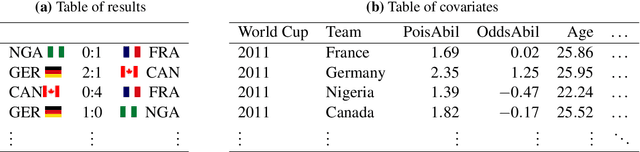
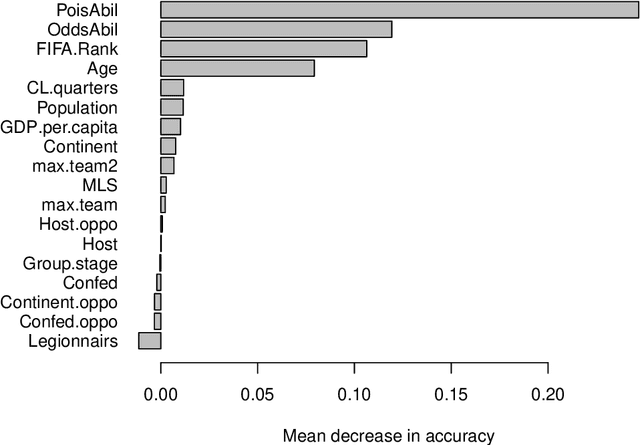
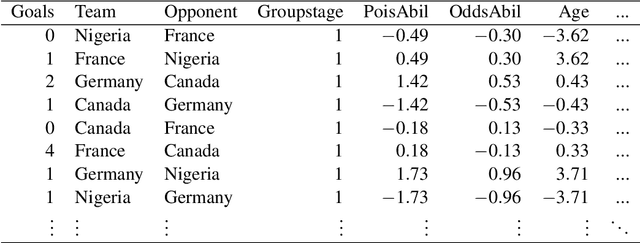

In this work, we combine two different ranking methods together with several other predictors in a joint random forest approach for the scores of soccer matches. The first ranking method is based on the bookmaker consensus, the second ranking method estimates adequate ability parameters that reflect the current strength of the teams best. The proposed combined approach is then applied to the data from the two previous FIFA Women's World Cups 2011 and 2015. Finally, based on the resulting estimates, the FIFA Women's World Cup 2019 is simulated repeatedly and winning probabilities are obtained for all teams. The model clearly favors the defending champion USA before the host France.