 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning-based Anomaly Detection Framework in Life Insurance Contracts
Nov 26, 2024Life insurance, like other forms of insurance, relies heavily on large volumes of data. The business model is based on an exchange where companies receive payments in return for the promise to provide coverage in case of an accident. Thus, trust in the integrity of the data stored in databases is crucial. One method to ensure data reliability is the automatic detection of anomalies. While this approach is highly useful, it is also challenging due to the scarcity of labeled data that distinguish between normal and anomalous contracts or inter\-actions. This manuscript discusses several classical and modern unsupervised anomaly detection methods and compares their performance across two different datasets. In order to facilitate the adoption of these methods by companies, this work also explores ways to automate the process, making it accessible even to non-data scientists.
Churn modeling of life insurance policies via statistical and machine learning methods -- Analysis of important features
Feb 18, 2022
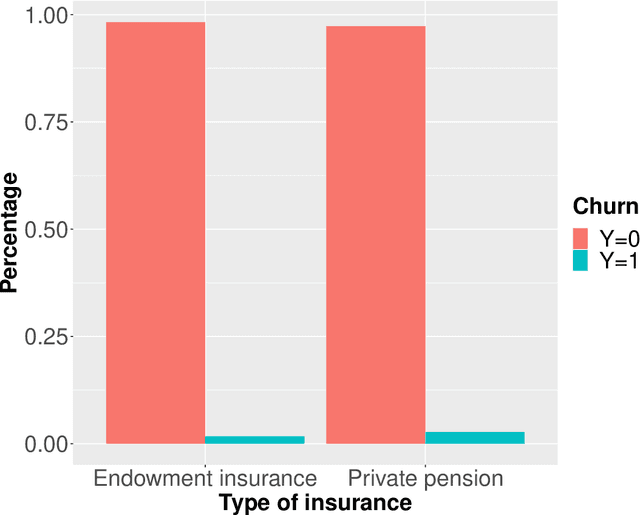
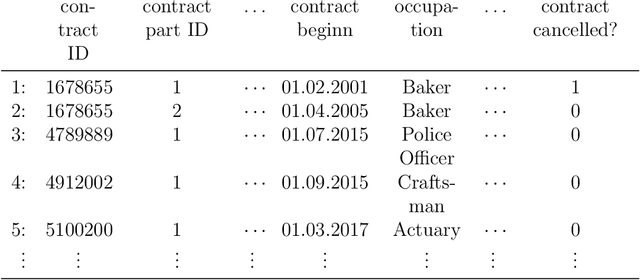

Life assurance companies typically possess a wealth of data covering multiple systems and databases. These data are often used for analyzing the past and for describing the present. Taking account of the past, the future is mostly forecasted by traditional statistical methods. So far, only a few attempts were undertaken to perform estimations by means of machine learning approaches. In this work, the individual contract cancellation behavior of customers within two partial stocks is modeled by the aid of various classification methods. Partial stocks of private pension and endowment policy are considered. We describe the data used for the modeling, their structured and in which way they are cleansed. The utilized models are calibrated on the basis of an extensive tuning process, then graphically evaluated regarding their goodness-of-fit and with the help of a variable relevance concept, we investigate which features notably affect the individual contract cancellation behavior.