 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Privacy Mechanisms via Label Inference Attacks
Jun 04, 2024



We propose reconstruction advantage measures to audit label privatization mechanisms. A reconstruction advantage measure quantifies the increase in an attacker's ability to infer the true label of an unlabeled example when provided with a private version of the labels in a dataset (e.g., aggregate of labels from different users or noisy labels output by randomized response), compared to an attacker that only observes the feature vectors, but may have prior knowledge of the correlation between features and labels. We consider two such auditing measures: one additive, and one multiplicative. These incorporate previous approaches taken in the literature on empirical auditing and differential privacy. The measures allow us to place a variety of proposed privatization schemes -- some differentially private, some not -- on the same footing. We analyze these measures theoretically under a distributional model which encapsulates reasonable adversarial settings. We also quantify their behavior empirically on real and simulated prediction tasks. Across a range of experimental settings, we find that differentially private schemes dominate or match the privacy-utility tradeoff of more heuristic approaches.
DP-SGD for non-decomposable objective functions
Oct 04, 2023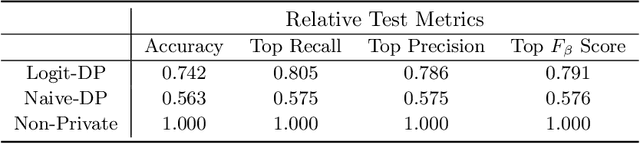
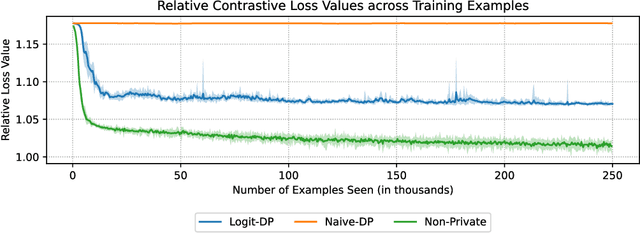
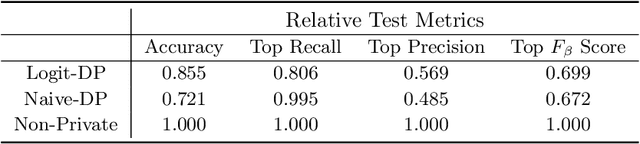
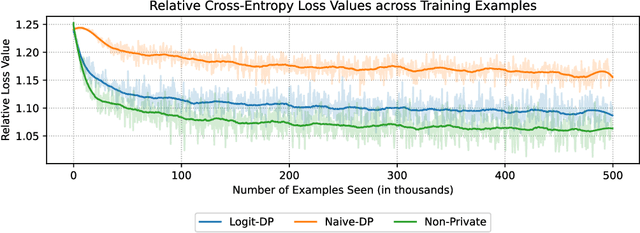
Unsupervised pre-training is a common step in developing computer vision models and large language models. In this setting, the absence of labels requires the use of similarity-based loss functions, such as contrastive loss, that favor minimizing the distance between similar inputs and maximizing the distance between distinct inputs. As privacy concerns mount, training these models using differential privacy has become more important. However, due to how inputs are generated for these losses, one of their undesirable properties is that their $L_2$ sensitivity can grow with increasing batch size. This property is particularly disadvantageous for differentially private training methods, such as DP-SGD. To overcome this issue, we develop a new DP-SGD variant for similarity based loss functions -- in particular the commonly used contrastive loss -- that manipulates gradients of the objective function in a novel way to obtain a senstivity of the summed gradient that is $O(1)$ for batch size $n$. We test our DP-SGD variant on some preliminary CIFAR-10 pre-training and CIFAR-100 finetuning tasks and show that, in both tasks, our method's performance comes close to that of a non-private model and generally outperforms DP-SGD applied directly to the contrastive loss.
Duff: A Dataset-Distance-Based Utility Function Family for the Exponential Mechanism
Oct 08, 2020

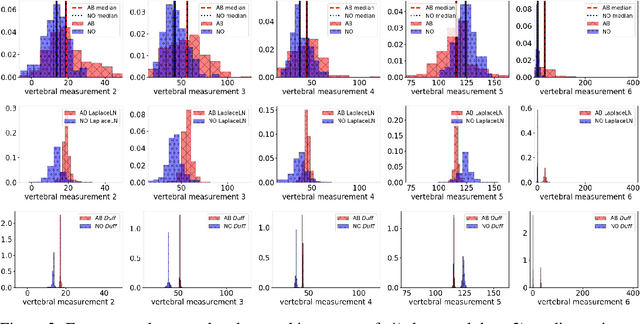
We propose and analyze a general-purpose dataset-distance-based utility function family, Duff, for differential privacy's exponential mechanism. Given a particular dataset and a statistic (e.g., median, mode), this function family assigns utility to a possible output o based on the number of individuals whose data would have to be added to or removed from the dataset in order for the statistic to take on value o. We show that the exponential mechanism based on Duff often offers provably higher fidelity to the statistic's true value compared to existing differential privacy mechanisms based on smooth sensitivity. In particular, Duff is an affirmative answer to the open question of whether it is possible to have a noise distribution whose variance is proportional to smooth sensitivity and whose tails decay at a faster-than-polynomial rate. We conclude our paper with an empirical evaluation of the practical advantages of Duff for the task of computing medians.
Online Learning for Non-Stationary A/B Tests
May 27, 2018
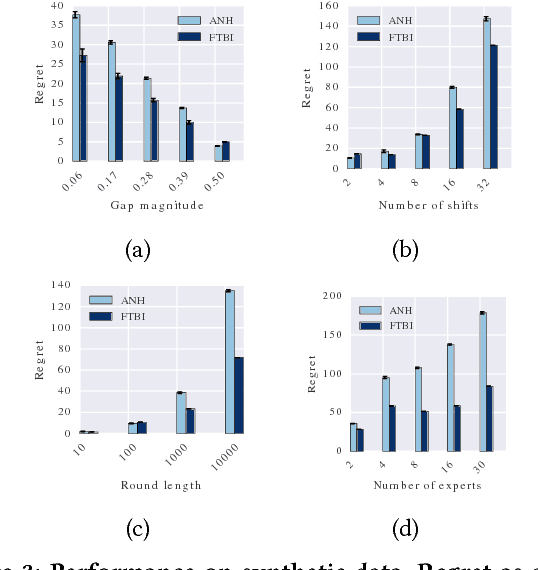

The rollout of new versions of a feature in modern applications is a manual multi-stage process, as the feature is released to ever larger groups of users, while its performance is carefully monitored. This kind of A/B testing is ubiquitous, but suboptimal, as the monitoring requires heavy human intervention, is not guaranteed to capture consistent, but short-term fluctuations in performance, and is inefficient, as better versions take a long time to reach the full population. In this work we formulate this question as that of expert learning, and give a new algorithm Follow-The-Best-Interval, FTBI, that works in dynamic, non-stationary environments. Our approach is practical, simple, and efficient, and has rigorous guarantees on its performance. Finally, we perform a thorough evaluation on synthetic and real world datasets and show that our approach outperforms current state-of-the-art methods.
Revenue Optimization with Approximate Bid Predictions
Nov 06, 2017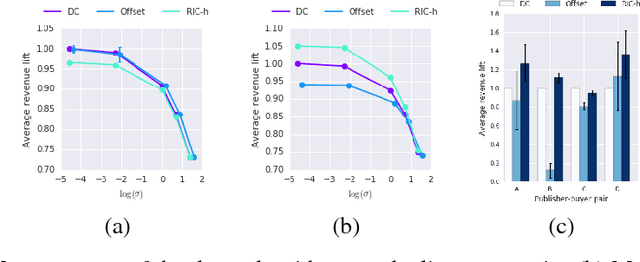
In the context of advertising auctions, finding good reserve prices is a notoriously challenging learning problem. This is due to the heterogeneity of ad opportunity types and the non-convexity of the objective function. In this work, we show how to reduce reserve price optimization to the standard setting of prediction under squared loss, a well understood problem in the learning community. We further bound the gap between the expected bid and revenue in terms of the average loss of the predictor. This is the first result that formally relates the revenue gained to the quality of a standard machine learned model.