 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-SGD for non-decomposable objective functions
Oct 04, 2023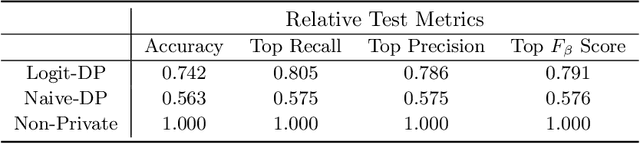
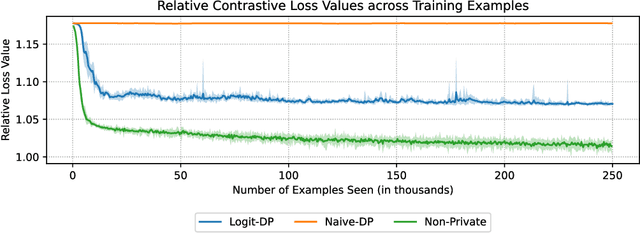
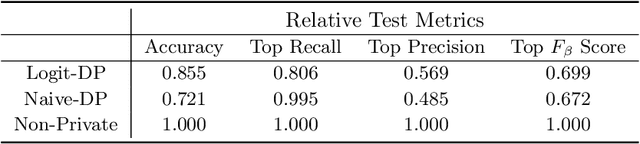
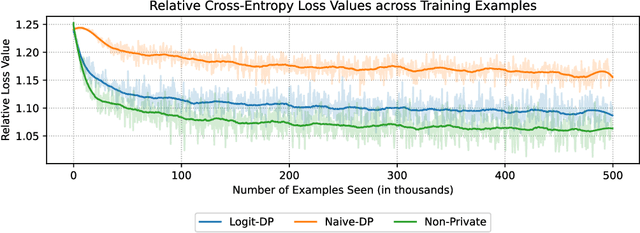
Unsupervised pre-training is a common step in developing computer vision models and large language models. In this setting, the absence of labels requires the use of similarity-based loss functions, such as contrastive loss, that favor minimizing the distance between similar inputs and maximizing the distance between distinct inputs. As privacy concerns mount, training these models using differential privacy has become more important. However, due to how inputs are generated for these losses, one of their undesirable properties is that their $L_2$ sensitivity can grow with increasing batch size. This property is particularly disadvantageous for differentially private training methods, such as DP-SGD. To overcome this issue, we develop a new DP-SGD variant for similarity based loss functions -- in particular the commonly used contrastive loss -- that manipulates gradients of the objective function in a novel way to obtain a senstivity of the summed gradient that is $O(1)$ for batch size $n$. We test our DP-SGD variant on some preliminary CIFAR-10 pre-training and CIFAR-100 finetuning tasks and show that, in both tasks, our method's performance comes close to that of a non-private model and generally outperforms DP-SGD applied directly to the contrastive loss.