 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Improve When Pretraining Data Matches Target Tasks
Jul 16, 2025Every data selection method inherently has a target. In practice, these targets often emerge implicitly through benchmark-driven iteration: researchers develop selection strategies, train models, measure benchmark performance, then refine accordingly. This raises a natural question: what happens when we make this optimization explicit? To explore this, we propose benchmark-targeted ranking (BETR), a simple method that selects pretraining documents based on similarity to benchmark training examples. BETR embeds benchmark examples and a sample of pretraining documents in a shared space, scores this sample by similarity to benchmarks, then trains a lightweight classifier to predict these scores for the full corpus. We compare data selection methods by training over 500 models spanning $10^{19}$ to $10^{22}$ FLOPs and fitting scaling laws to them. From this, we find that simply aligning pretraining data to evaluation benchmarks using BETR achieves a 2.1x compute multiplier over DCLM-Baseline (4.7x over unfiltered data) and improves performance on 9 out of 10 tasks across all scales. BETR also generalizes well: when targeting a diverse set of benchmarks disjoint from our evaluation suite, it still matches or outperforms baselines. Our scaling analysis further reveals a clear trend: larger models require less aggressive filtering. Overall, our findings show that directly matching pretraining data to target tasks precisely shapes model capabilities and highlight that optimal selection strategies must adapt to model scale.
Dreaming More Data: Class-dependent Distributions over Diffeomorphisms for Learned Data Augmentation
Jun 30, 2016



Data augmentation is a key element in training high-dimensional models. In this approach, one synthesizes new observations by applying pre-specified transformations to the original training data; e.g.~new images are formed by rotating old ones. Current augmentation schemes, however, rely on manual specification of the applied transformations, making data augmentation an implicit form of feature engineering. With an eye towards true end-to-end learning, we suggest learning the applied transformations on a per-class basis. Particularly, we align image pairs within each class under the assumption that the spatial transformation between images belongs to a large class of diffeomorphisms. We then learn a class-specific probabilistic generative models of the transformations in a Riemannian submanifold of the Lie group of diffeomorphisms. We demonstrate significant performance improvements in training deep neural nets over manually-specified augmentation schemes. Our code and augmented datasets are available online.
Autoencoding beyond pixels using a learned similarity metric
Feb 10, 2016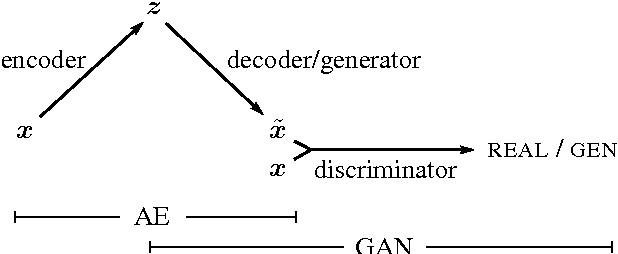

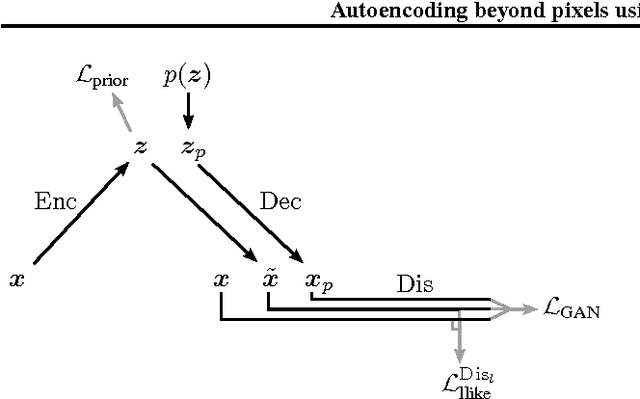

We present an autoencoder that leverages learned representations to better measure similarities in data space. By combining a variational autoencoder with a generative adversarial network we can use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective. Thereby, we replace element-wise errors with feature-wise errors to better capture the data distribution while offering invariance towards e.g. translation. We apply our method to images of faces and show that it outperforms VAEs with element-wise similarity measures in terms of visual fidelity. Moreover, we show that the method learns an embedding in which high-level abstract visual features (e.g. wearing glasses) can be modified using simple arithmetic.