 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRASP: GRAph-Structured Pyramidal Whole Slide Image Representation
Feb 06, 2024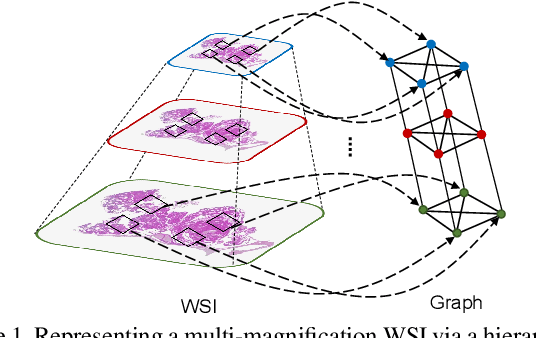
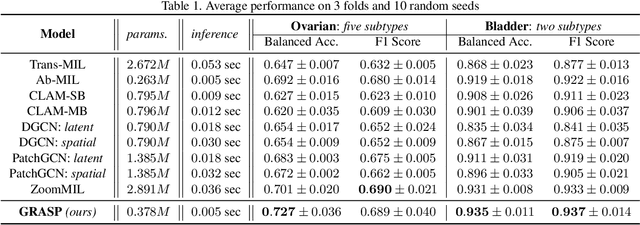
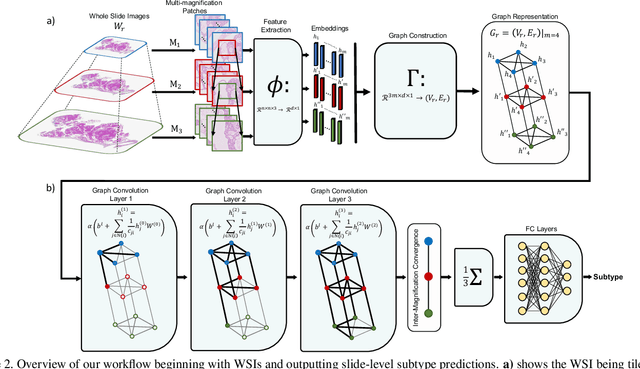
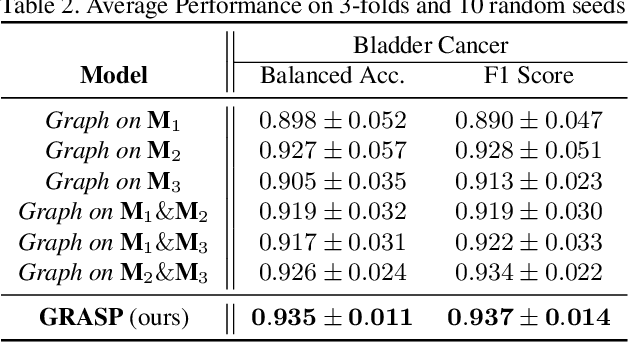
Cancer subtyping is one of the most challenging tasks in digital pathology, where Multiple Instance Learning (MIL) by processing gigapixel whole slide images (WSIs) has been in the spotlight of recent research. However, MIL approaches do not take advantage of inter- and intra-magnification information contained in WSIs. In this work, we present GRASP, a novel graph-structured multi-magnification framework for processing WSIs in digital pathology. Our approach is designed to dynamically emulate the pathologist's behavior in handling WSIs and benefits from the hierarchical structure of WSIs. GRASP, which introduces a convergence-based node aggregation instead of traditional pooling mechanisms, outperforms state-of-the-art methods over two distinct cancer datasets by a margin of up to 10% balanced accuracy, while being 7 times smaller than the closest-performing state-of-the-art model in terms of the number of parameters. Our results show that GRASP is dynamic in finding and consulting with different magnifications for subtyping cancers and is reliable and stable across different hyperparameters. The model's behavior has been evaluated by two expert pathologists confirming the interpretability of the model's dynamic. We also provide a theoretical foundation, along with empirical evidence, for our work, explaining how GRASP interacts with different magnifications and nodes in the graph to make predictions. We believe that the strong characteristics yet simple structure of GRASP will encourage the development of interpretable, structure-based designs for WSI representation in digital pathology. Furthermore, we publish two large graph datasets of rare Ovarian and Bladder cancers to contribute to the field.
VOLTA: an Environment-Aware Contrastive Cell Representation Learning for Histopathology
Mar 08, 2023
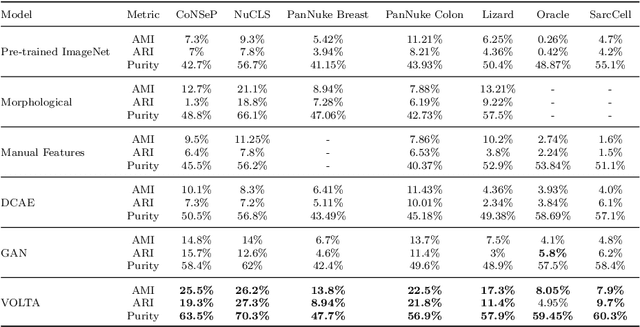

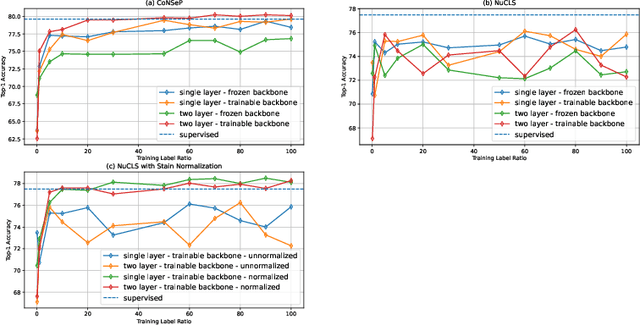
In clinical practice, many diagnosis tasks rely on the identification of cells in histopathology images. While supervised machine learning techniques require labels, providing manual cell annotations is time-consuming due to the large number of cells. In this paper, we propose a self-supervised framework (VOLTA) for cell representation learning in histopathology images using a novel technique that accounts for the cell's mutual relationship with its environment for improved cell representations. We subjected our model to extensive experiments on the data collected from multiple institutions around the world comprising of over 700,000 cells, four cancer types, and cell types ranging from three to six categories for each dataset. The results show that our model outperforms the state-of-the-art models in cell representation learning. To showcase the potential power of our proposed framework, we applied VOLTA to ovarian and endometrial cancers with very small sample sizes (10-20 samples) and demonstrated that our cell representations can be utilized to identify the known histotypes of ovarian cancer and provide novel insights that link histopathology and molecular subtypes of endometrial cancer. Unlike supervised deep learning models that require large sample sizes for training, we provide a framework that can empower new discoveries without any annotation data in situations where sample sizes are limited.
CCRL: Contrastive Cell Representation Learning
Aug 12, 2022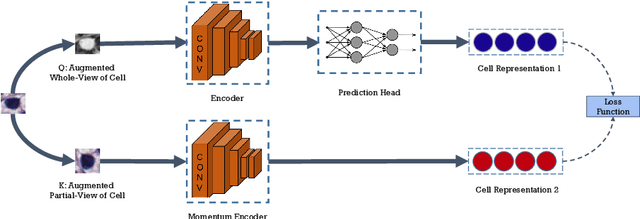
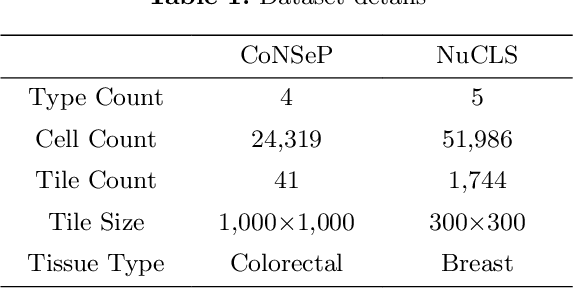
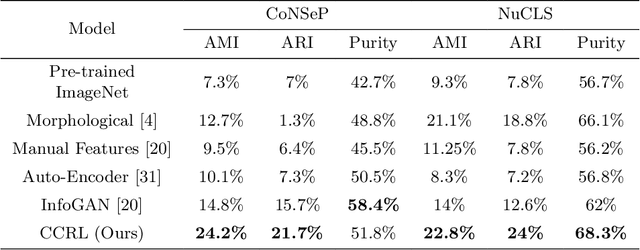
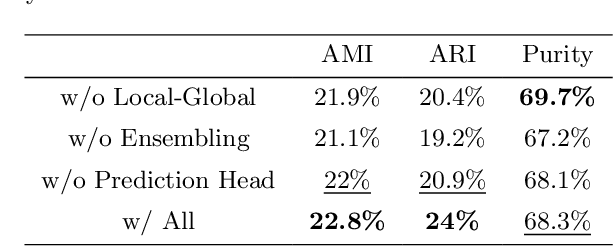
Cell identification within the H&E slides is an essential prerequisite that can pave the way towards further pathology analyses including tissue classification, cancer grading, and phenotype prediction. However, performing such a task using deep learning techniques requires a large cell-level annotated dataset. Although previous studies have investigated the performance of contrastive self-supervised methods in tissue classification, the utility of this class of algorithms in cell identification and clustering is still unknown. In this work, we investigated the utility of Self-Supervised Learning (SSL) in cell clustering by proposing the Contrastive Cell Representation Learning (CCRL) model. Through comprehensive comparisons, we show that this model can outperform all currently available cell clustering models by a large margin across two datasets from different tissue types. More interestingly, the results show that our proposed model worked well with a few number of cell categories while the utility of SSL models has been mainly shown in the context of natural image datasets with large numbers of classes (e.g., ImageNet). The unsupervised representation learning approach proposed in this research eliminates the time-consuming step of data annotation in cell classification tasks, which enables us to train our model on a much larger dataset compared to previous methods. Therefore, considering the promising outcome, this approach can open a new avenue to automatic cell representation learning.