 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is the Winning Algorithm? Rank Aggregation for Comparative Studies
Jan 04, 2026Consider a collection of m competing machine learning algorithms. Given their performance on a benchmark of datasets, we would like to identify the best performing algorithm. Specifically, which algorithm is most likely to ``win'' (rank highest) on a future, unseen dataset. The standard maximum likelihood approach suggests counting the number of wins per each algorithm. In this work, we argue that there is much more information in the complete rankings. That is, the number of times that each algorithm finished second, third and so forth. Yet, it is not entirely clear how to effectively utilize this information for our purpose. In this work we introduce a novel conceptual framework for estimating the win probability for each of the m algorithms, given their complete rankings over a benchmark of datasets. Our proposed framework significantly improves upon currently known methods in synthetic and real-world examples.
Near Optimal Inference for the Best-Performing Algorithm
Aug 07, 2025Consider a collection of competing machine learning algorithms. Given their performance on a benchmark of datasets, we would like to identify the best performing algorithm. Specifically, which algorithm is most likely to rank highest on a future, unseen dataset. A natural approach is to select the algorithm that demonstrates the best performance on the benchmark. However, in many cases the performance differences are marginal and additional candidates may also be considered. This problem is formulated as subset selection for multinomial distributions. Formally, given a sample from a countable alphabet, our goal is to identify a minimal subset of symbols that includes the most frequent symbol in the population with high confidence. In this work, we introduce a novel framework for the subset selection problem. We provide both asymptotic and finite-sample schemes that significantly improve upon currently known methods. In addition, we provide matching lower bounds, demonstrating the favorable performance of our proposed schemes.
Distribution Estimation under the Infinity Norm
Feb 13, 2024


We present novel bounds for estimating discrete probability distributions under the $\ell_\infty$ norm. These are nearly optimal in various precise senses, including a kind of instance-optimality. Our data-dependent convergence guarantees for the maximum likelihood estimator significantly improve upon the currently known results. A variety of techniques are utilized and innovated upon, including Chernoff-type inequalities and empirical Bernstein bounds. We illustrate our results in synthetic and real-world experiments. Finally, we apply our proposed framework to a basic selective inference problem, where we estimate the most frequent probabilities in a sample.
Optimal detection of non-overlapping images via combinatorial auction
Jan 21, 2024This paper studies the classical problem of detecting the location of multiple image occurrences in a two-dimensional, noisy measurement. Assuming the image occurrences do not overlap, we formulate this task as a constrained maximum likelihood optimization problem. We show that the maximum likelihood estimator is equivalent to an instance of the winner determination problem from the field of combinatorial auction, and that the solution can be obtained by searching over a binary tree. We then design a pruning mechanism that significantly accelerates the runtime of the search. We demonstrate on simulations and electron microscopy data sets that the proposed algorithm provides accurate detection in challenging regimes of high noise levels and densely packed image occurrences.
Confidence Intervals for Unobserved Events
Nov 06, 2022Consider a finite sample from an unknown distribution over a countable alphabet. Unobserved events are alphabet symbols which do not appear in the sample. Estimating the probabilities of unobserved events is a basic problem in statistics and related fields, which was extensively studied in the context of point estimation. In this work we introduce a novel interval estimation scheme for unobserved events. Our proposed framework applies selective inference, as we construct confidence intervals (CIs) for the desired set of parameters. Interestingly, we show that obtained CIs are dimension-free, as they do not grow with the alphabet size. Further, we show that these CIs are (almost) tight, in the sense that they cannot be further improved without violating the prescribed coverage rate. We demonstrate the performance of our proposed scheme in synthetic and real-world experiments, showing a significant improvement over the alternatives. Finally, we apply our proposed scheme to large alphabet modeling. We introduce a novel simultaneous CI scheme for large alphabet distributions which outperforms currently known methods while maintaining the prescribed coverage rate.
K-sample Multiple Hypothesis Testing for Signal Detection
Sep 23, 2022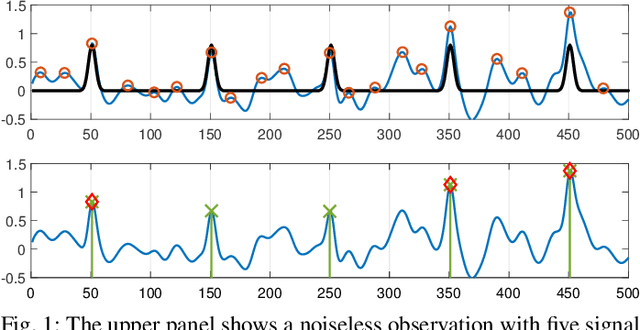
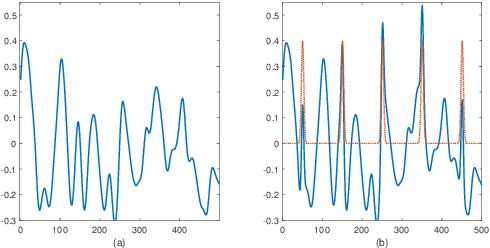
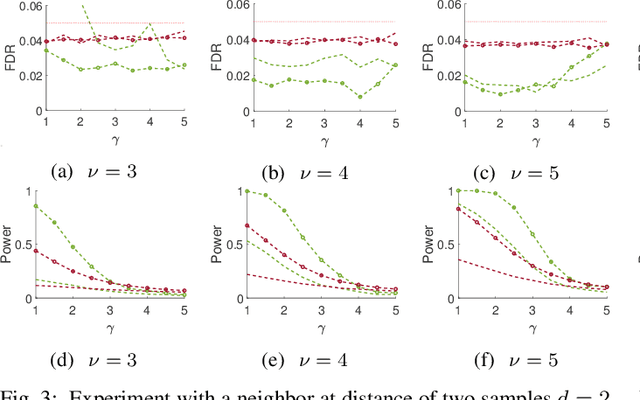
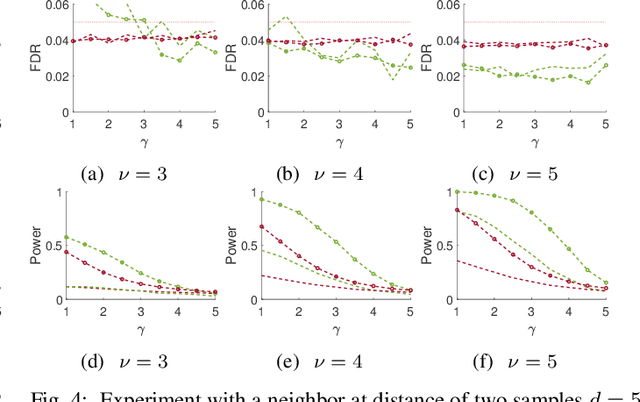
This paper studies the classical problem of estimating the locations of signal occurrences in a noisy measurement. Based on a multiple hypothesis testing scheme, we design a K-sample statistical test to control the false discovery rate (FDR). Specifically, we first convolve the noisy measurement with a smoothing kernel, and find all local maxima. Then, we evaluate the joint probability of K entries in the vicinity of each local maximum, derive the corresponding p-value, and apply the Benjamini-Hochberg procedure to account for multiplicity. We demonstrate through extensive experiments that our proposed method, with K=2, controls the prescribed FDR while increasing the power compared to a one-sample test.
Signal detection with dynamic programming
Aug 16, 2022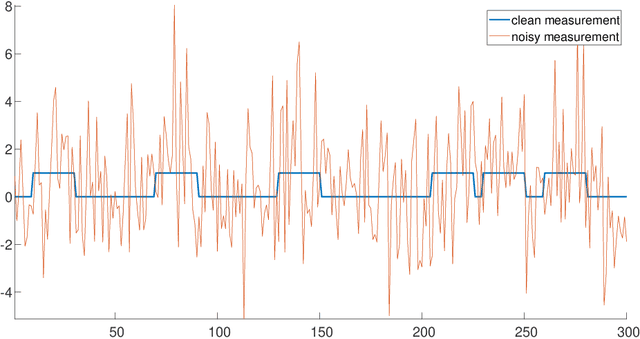
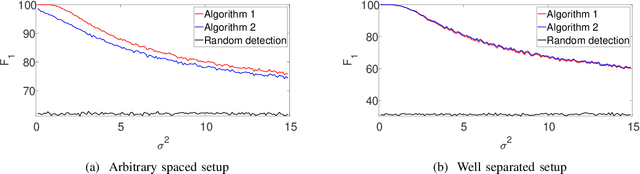

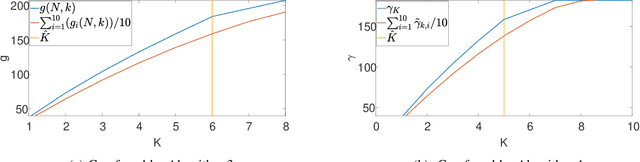
This paper studies the classical problem of detecting the locations of signal occurrences in a one-dimensional noisy measurement. Assuming the signal occurrences do not overlap, we formulate the detection task as a constrained likelihood optimization problem, and design a computationally efficient dynamic program that attains its optimal solution. Our proposed framework is scalable, simple to implement, and robust to model uncertainties. We show by extensive numerical experiments that our algorithm accurately estimates the locations in dense and noisy environments, and outperforms alternative methods.
Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection
Sep 12, 2021

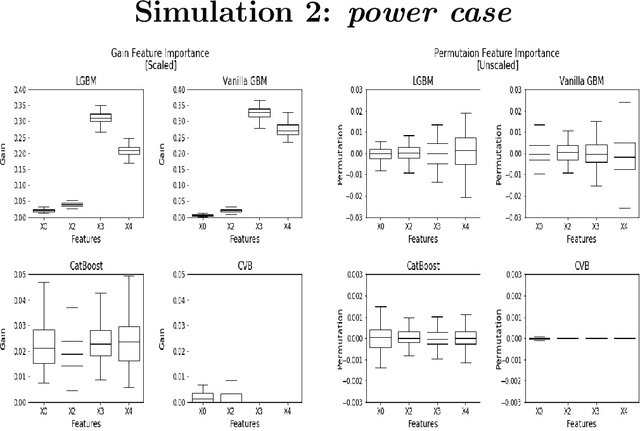
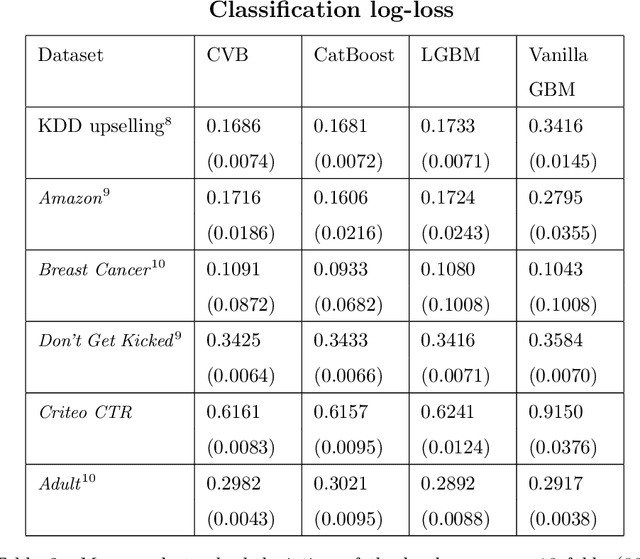
Gradient Boosting Machines (GBM) are among the go-to algorithms on tabular data, which produce state of the art results in many prediction tasks. Despite its popularity, the GBM framework suffers from a fundamental flaw in its base learners. Specifically, most implementations utilize decision trees that are typically biased towards categorical variables with large cardinalities. The effect of this bias was extensively studied over the years, mostly in terms of predictive performance. In this work, we extend the scope and study the effect of biased base learners on GBM feature importance (FI) measures. We show that although these implementation demonstrate highly competitive predictive performance, they still, surprisingly, suffer from bias in FI. By utilizing cross-validated (CV) unbiased base learners, we fix this flaw at a relatively low computational cost. We demonstrate the suggested framework in a variety of synthetic and real-world setups, showing a significant improvement in all GBM FI measures while maintaining relatively the same level of prediction accuracy.
Neural Joint Entropy Estimation
Dec 21, 2020

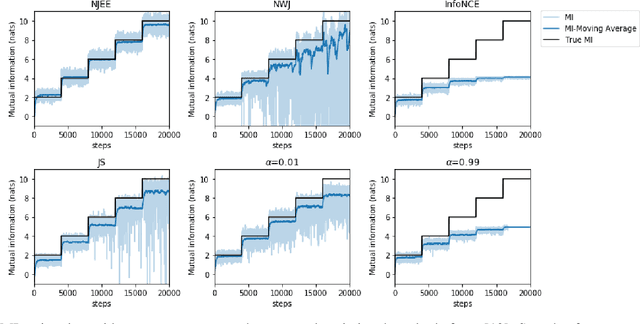

Estimating the entropy of a discrete random variable is a fundamental problem in information theory and related fields. This problem has many applications in various domains, including machine learning, statistics and data compression. Over the years, a variety of estimation schemes have been suggested. However, despite significant progress, most methods still struggle when the sample is small, compared to the variable's alphabet size. In this work, we introduce a practical solution to this problem, which extends the work of McAllester and Statos (2020). The proposed scheme uses the generalization abilities of cross-entropy estimation in deep neural networks (DNNs) to introduce improved entropy estimation accuracy. Furthermore, we introduce a family of estimators for related information-theoretic measures, such as conditional entropy and mutual information. We show that these estimators are strongly consistent and demonstrate their performance in a variety of use-cases. First, we consider large alphabet entropy estimation. Then, we extend the scope to mutual information estimation. Next, we apply the proposed scheme to conditional mutual information estimation, as we focus on independence testing tasks. Finally, we study a transfer entropy estimation problem. The proposed estimators demonstrate improved performance compared to existing methods in all tested setups.
An Information-Theoretic Framework for Non-linear Canonical Correlation Analysis
Oct 31, 2018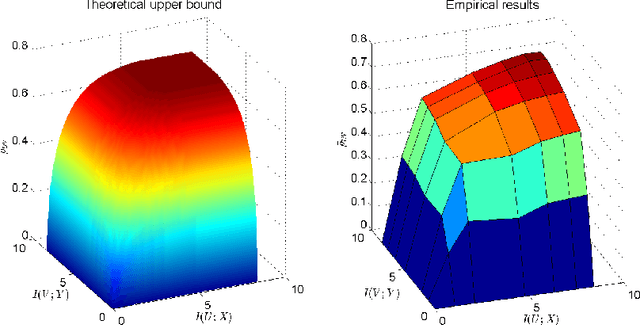
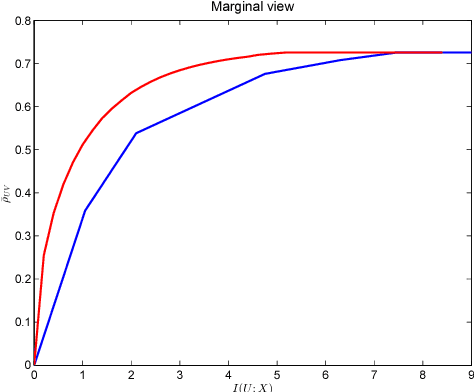
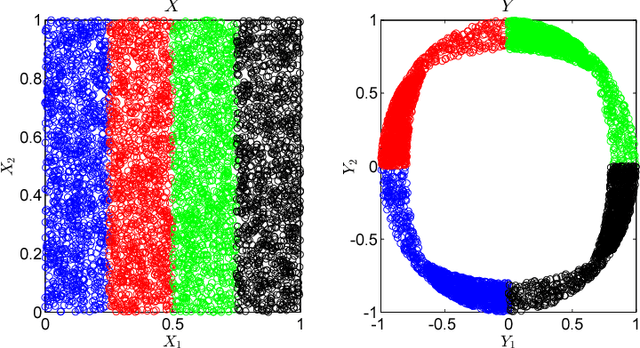
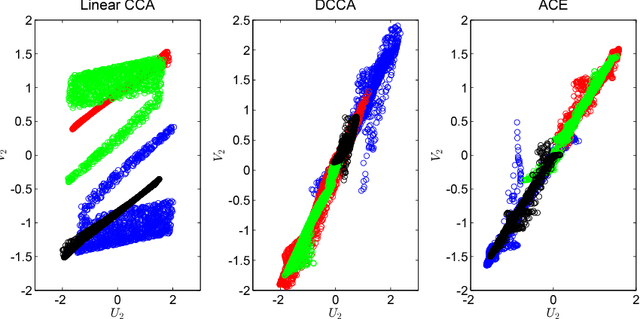
Canonical Correlation Analysis (CCA) is a linear representation learning method that seeks maximally correlated variables in multi-view data. Non-linear CCA extends this notion to a broader family of transformations, which are more powerful for many real-world applications. Given the joint probability, the Alternating Conditional Expectation (ACE) provides an optimal solution to the non-linear CCA problem. However, it suffers from limited performance and an increasing computational burden when only a finite number of observations is available. In this work we introduce an information-theoretic framework for the non-linear CCA problem (ITCCA), which extends the classical ACE approach. Our suggested framework seeks compressed representations of the data that allow a maximal level of correlation. This way we control the trade-off between the flexibility and the complexity of the representation. Our approach demonstrates favorable performance at a reduced computational burden, compared to non-linear alternatives, in a finite sample size regime. Further, ITCCA provides theoretical bounds and optimality conditions, as we establish fundamental connections to rate-distortion theory, the information bottleneck and remote source coding. In addition, it implies a "soft" dimensionality reduction, as the compression level is measured (and governed) by the mutual information between the original noisy data and the signals that we extract.