 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Universality Lens: Why Even Highly Over-Parametrized Models Learn Well
Jun 09, 2025A fundamental question in modern machine learning is why large, over-parameterized models, such as deep neural networks and transformers, tend to generalize well, even when their number of parameters far exceeds the number of training samples. We investigate this phenomenon through the lens of information theory, grounded in universal learning theory. Specifically, we study a Bayesian mixture learner with log-loss and (almost) uniform prior over an expansive hypothesis class. Our key result shows that the learner's regret is not determined by the overall size of the hypothesis class, but rather by the cumulative probability of all models that are close, in Kullback-Leibler divergence distance, to the true data-generating process. We refer to this cumulative probability as the weight of the hypothesis. This leads to a natural notion of model simplicity: simple models are those with large weight and thus require fewer samples to generalize, while complex models have small weight and need more data. This perspective provides a rigorous and intuitive explanation for why over-parameterized models often avoid overfitting: the presence of simple hypotheses allows the posterior to concentrate on them when supported by the data. We further bridge theory and practice by recalling that stochastic gradient descent with Langevin dynamics samples from the correct posterior distribution, enabling our theoretical learner to be approximated using standard machine learning methods combined with ensemble learning. Our analysis yields non-uniform regret bounds and aligns with key practical concepts such as flat minima and model distillation. The results apply broadly across online, batch, and supervised learning settings, offering a unified and principled understanding of the generalization behavior of modern AI systems.
Universal Batch Learning Under The Misspecification Setting
May 12, 2024
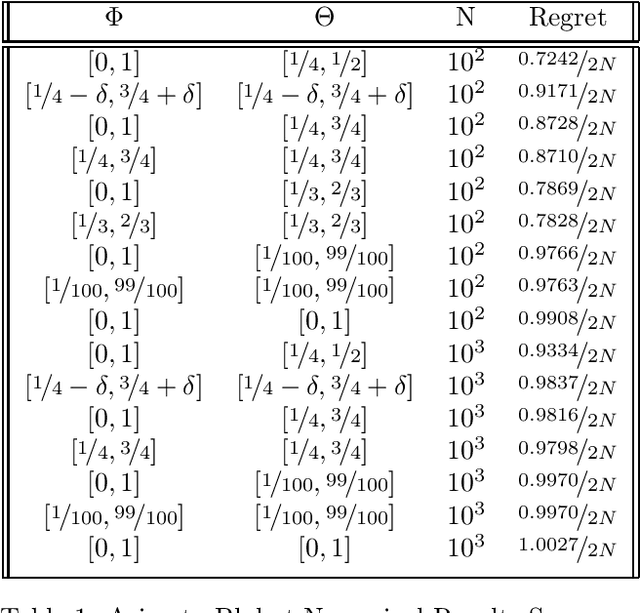
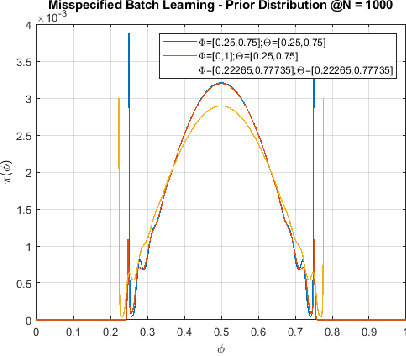
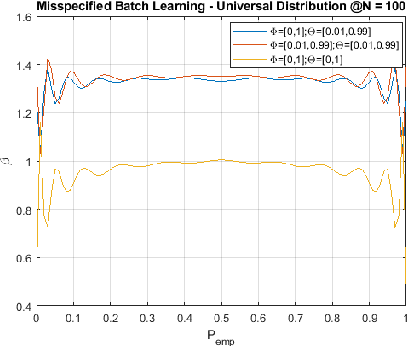
In this paper we consider the problem of universal {\em batch} learning in a misspecification setting with log-loss. In this setting the hypothesis class is a set of models $\Theta$. However, the data is generated by an unknown distribution that may not belong to this set but comes from a larger set of models $\Phi \supset \Theta$. Given a training sample, a universal learner is requested to predict a probability distribution for the next outcome and a log-loss is incurred. The universal learner performance is measured by the regret relative to the best hypothesis matching the data, chosen from $\Theta$. Utilizing the minimax theorem and information theoretical tools, we derive the optimal universal learner, a mixture over the set of the data generating distributions, and get a closed form expression for the min-max regret. We show that this regret can be considered as a constrained version of the conditional capacity between the data and its generating distributions set. We present tight bounds for this min-max regret, implying that the complexity of the problem is dominated by the richness of the hypotheses models $\Theta$ and not by the data generating distributions set $\Phi$. We develop an extension to the Arimoto-Blahut algorithm for numerical evaluation of the regret and its capacity achieving prior distribution. We demonstrate our results for the case where the observations come from a $K$-parameters multinomial distributions while the hypothesis class $\Theta$ is only a subset of this family of distributions.
Error Exponent in Agnostic PAC Learning
May 01, 2024

Statistical learning theory and the Probably Approximately Correct (PAC) criterion are the common approach to mathematical learning theory. PAC is widely used to analyze learning problems and algorithms, and have been studied thoroughly. Uniform worst case bounds on the convergence rate have been well established using, e.g., VC theory or Radamacher complexity. However, in a typical scenario the performance could be much better. In this paper, we consider PAC learning using a somewhat different tradeoff, the error exponent - a well established analysis method in Information Theory - which describes the exponential behavior of the probability that the risk will exceed a certain threshold as function of the sample size. We focus on binary classification and find, under some stability assumptions, an improved distribution dependent error exponent for a wide range of problems, establishing the exponential behavior of the PAC error probability in agnostic learning. Interestingly, under these assumptions, agnostic learning may have the same error exponent as realizable learning. The error exponent criterion can be applied to analyze knowledge distillation, a problem that so far lacks a theoretical analysis.
Batches Stabilize the Minimum Norm Risk in High Dimensional Overparameterized Linear Regression
Jun 14, 2023Learning algorithms that divide the data into batches are prevalent in many machine-learning applications, typically offering useful trade-offs between computational efficiency and performance. In this paper, we examine the benefits of batch-partitioning through the lens of a minimum-norm overparameterized linear regression model with isotropic Gaussian features. We suggest a natural small-batch version of the minimum-norm estimator, and derive an upper bound on its quadratic risk, showing it is inversely proportional to the noise level as well as to the overparameterization ratio, for the optimal choice of batch size. In contrast to minimum-norm, our estimator admits a stable risk behavior that is monotonically increasing in the overparameterization ratio, eliminating both the blowup at the interpolation point and the double-descent phenomenon. Interestingly, we observe that this implicit regularization offered by the batch partition is partially explained by feature overlap between the batches. Our bound is derived via a novel combination of techniques, in particular normal approximation in the Wasserstein metric of noisy projections over random subspaces.
Beyond Ridge Regression for Distribution-Free Data
Jun 17, 2022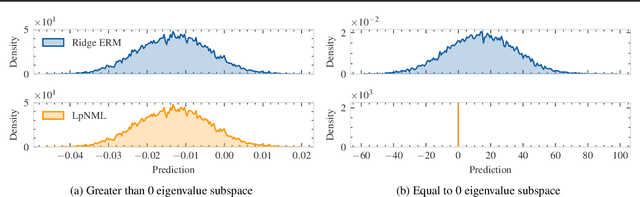

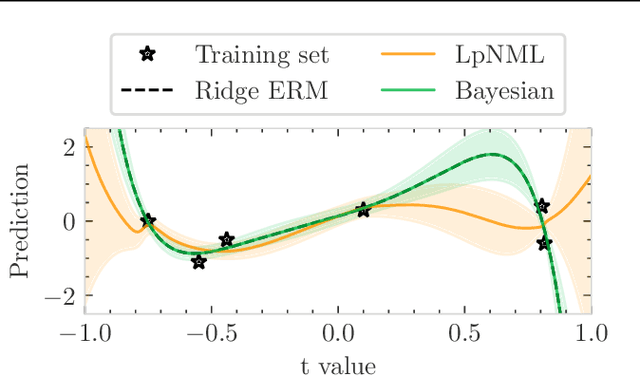
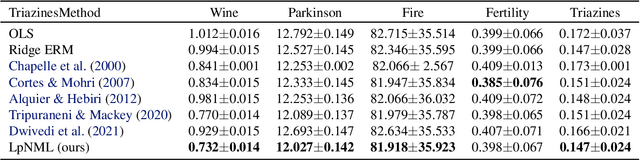
In supervised batch learning, the predictive normalized maximum likelihood (pNML) has been proposed as the min-max regret solution for the distribution-free setting, where no distributional assumptions are made on the data. However, the pNML is not defined for a large capacity hypothesis class as over-parameterized linear regression. For a large class, a common approach is to use regularization or a model prior. In the context of online prediction where the min-max solution is the Normalized Maximum Likelihood (NML), it has been suggested to use NML with ``luckiness'': A prior-like function is applied to the hypothesis class, which reduces its effective size. Motivated by the luckiness concept, for linear regression we incorporate a luckiness function that penalizes the hypothesis proportionally to its l2 norm. This leads to the ridge regression solution. The associated pNML with luckiness (LpNML) prediction deviates from the ridge regression empirical risk minimizer (Ridge ERM): When the test data reside in the subspace corresponding to the small eigenvalues of the empirical correlation matrix of the training data, the prediction is shifted toward 0. Our LpNML reduces the Ridge ERM error by up to 20% for the PMLB sets, and is up to 4.9% more robust in the presence of distribution shift compared to recent leading methods for UCI sets.
Single Layer Predictive Normalized Maximum Likelihood for Out-of-Distribution Detection
Oct 18, 2021


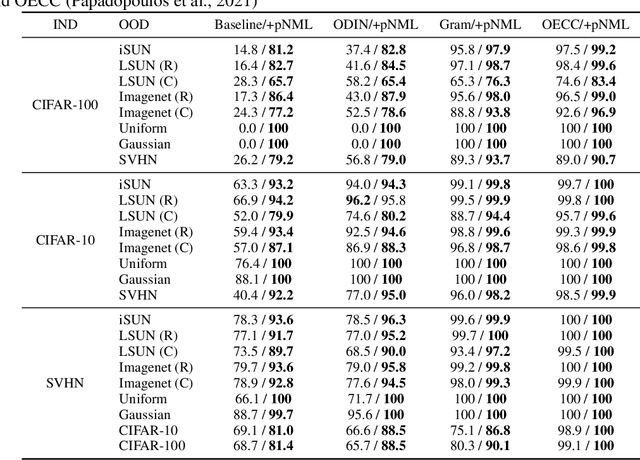
Detecting out-of-distribution (OOD) samples is vital for developing machine learning based models for critical safety systems. Common approaches for OOD detection assume access to some OOD samples during training which may not be available in a real-life scenario. Instead, we utilize the {\em predictive normalized maximum likelihood} (pNML) learner, in which no assumptions are made on the tested input. We derive an explicit expression of the pNML and its generalization error, denoted as the {\em regret}, for a single layer neural network (NN). We show that this learner generalizes well when (i) the test vector resides in a subspace spanned by the eigenvectors associated with the large eigenvalues of the empirical correlation matrix of the training data, or (ii) the test sample is far from the decision boundary. Furthermore, we describe how to efficiently apply the derived pNML regret to any pretrained deep NN, by employing the explicit pNML for the last layer, followed by the softmax function. Applying the derived regret to deep NN requires neither additional tunable parameters nor extra data. We extensively evaluate our approach on 74 OOD detection benchmarks using DenseNet-100, ResNet-34, and WideResNet-40 models trained with CIFAR-100, CIFAR-10, SVHN, and ImageNet-30 showing a significant improvement of up to 15.6\% over recent leading methods.
Utilizing Adversarial Targeted Attacks to Boost Adversarial Robustness
Sep 04, 2021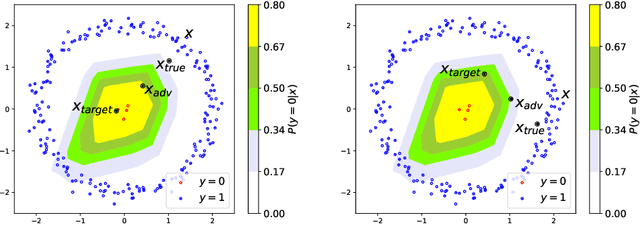



Adversarial attacks have been shown to be highly effective at degrading the performance of deep neural networks (DNNs). The most prominent defense is adversarial training, a method for learning a robust model. Nevertheless, adversarial training does not make DNNs immune to adversarial perturbations. We propose a novel solution by adopting the recently suggested Predictive Normalized Maximum Likelihood. Specifically, our defense performs adversarial targeted attacks according to different hypotheses, where each hypothesis assumes a specific label for the test sample. Then, by comparing the hypothesis probabilities, we predict the label. Our refinement process corresponds to recent findings of the adversarial subspace properties. We extensively evaluate our approach on 16 adversarial attack benchmarks using ResNet-50, WideResNet-28, and a2-layer ConvNet trained with ImageNet, CIFAR10, and MNIST, showing a significant improvement of up to 5.7%, 3.7%, and 0.6% respectively.
The Predictive Normalized Maximum Likelihood for Over-parameterized Linear Regression with Norm Constraint: Regret and Double Descent
Feb 14, 2021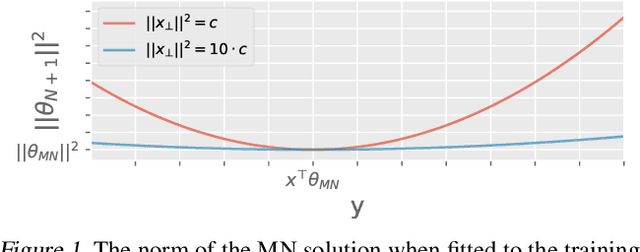

A fundamental tenet of learning theory is that a trade-off exists between the complexity of a prediction rule and its ability to generalize. The double-decent phenomenon shows that modern machine learning models do not obey this paradigm: beyond the interpolation limit, the test error declines as model complexity increases. We investigate over-parameterization in linear regression using the recently proposed predictive normalized maximum likelihood (pNML) learner which is the min-max regret solution for individual data. We derive an upper bound of its regret and show that if the test sample lies mostly in a subspace spanned by the eigenvectors associated with the large eigenvalues of the empirical correlation matrix of the training data, the model generalizes despite its over-parameterized nature. We demonstrate the use of the pNML regret as a point-wise learnability measure on synthetic data and that it can successfully predict the double-decent phenomenon using the UCI dataset.
Sequential prediction under log-loss and misspecification
Jan 29, 2021We consider the question of sequential prediction under the log-loss in terms of cumulative regret. Namely, given a hypothesis class of distributions, learner sequentially predicts the (distribution of the) next letter in sequence and its performance is compared to the baseline of the best constant predictor from the hypothesis class. The well-specified case corresponds to an additional assumption that the data-generating distribution belongs to the hypothesis class as well. Here we present results in the more general misspecified case. Due to special properties of the log-loss, the same problem arises in the context of competitive-optimality in density estimation, and model selection. For the $d$-dimensional Gaussian location hypothesis class, we show that cumulative regrets in the well-specified and misspecified cases asymptotically coincide. In other words, we provide an $o(1)$ characterization of the distribution-free (or PAC) regret in this case -- the first such result as far as we know. We recall that the worst-case (or individual-sequence) regret in this case is larger by an additive constant ${d\over 2} + o(1)$. Surprisingly, neither the traditional Bayesian estimators, nor the Shtarkov's normalized maximum likelihood achieve the PAC regret and our estimator requires special "robustification" against heavy-tailed data. In addition, we show two general results for misspecified regret: the existence and uniqueness of the optimal estimator, and the bound sandwiching the misspecified regret between well-specified regrets with (asymptotically) close hypotheses classes.
Efficient Data-Dependent Learnability
Nov 20, 2020
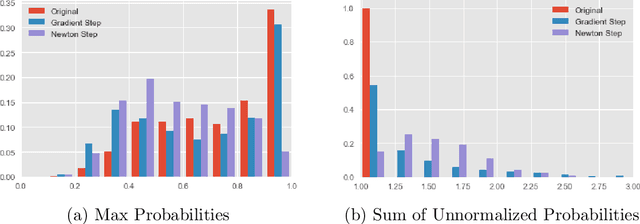
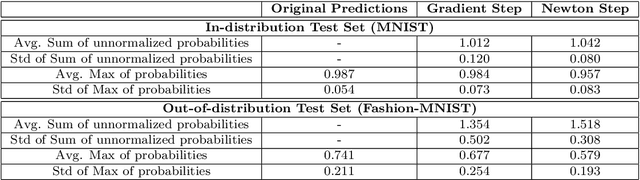
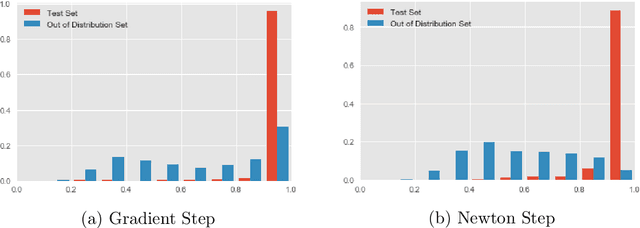
The predictive normalized maximum likelihood (pNML) approach has recently been proposed as the min-max optimal solution to the batch learning problem where both the training set and the test data feature are individuals, known sequences. This approach has yields a learnability measure that can also be interpreted as a stability measure. This measure has shown some potential in detecting out-of-distribution examples, yet it has considerable computational costs. In this project, we propose and analyze an approximation of the pNML, which is based on influence functions. Combining both theoretical analysis and experiments, we show that when applied to neural networks, this approximation can detect out-of-distribution examples effectively. We also compare its performance to that achieved by conducting a single gradient step for each possible label.