 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Batch Learning Under The Misspecification Setting
Paper and Code
May 12, 2024
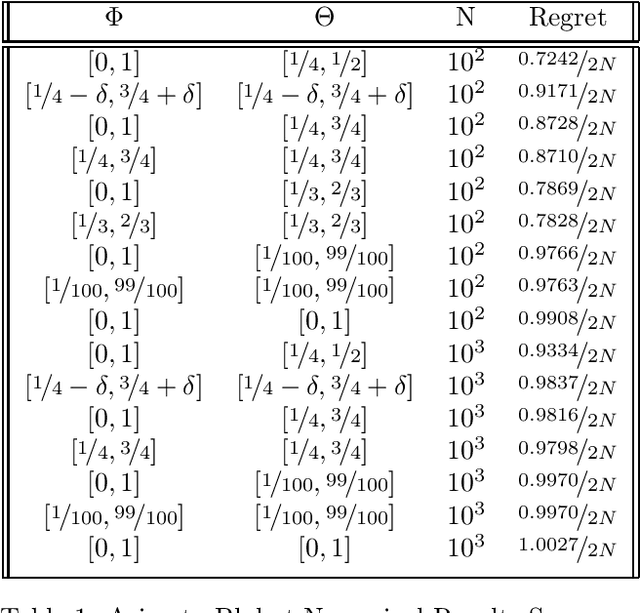
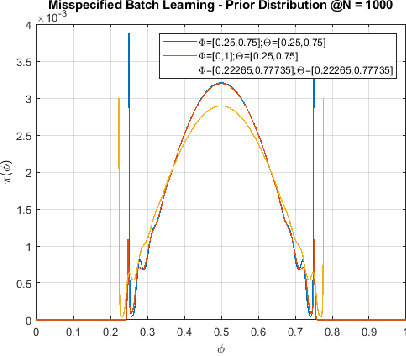
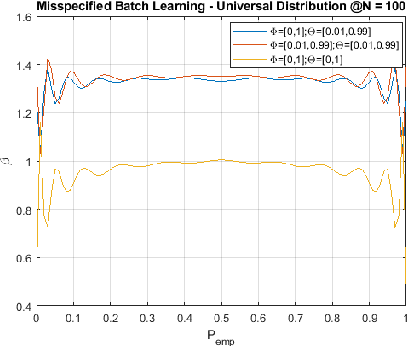
In this paper we consider the problem of universal {\em batch} learning in a misspecification setting with log-loss. In this setting the hypothesis class is a set of models $\Theta$. However, the data is generated by an unknown distribution that may not belong to this set but comes from a larger set of models $\Phi \supset \Theta$. Given a training sample, a universal learner is requested to predict a probability distribution for the next outcome and a log-loss is incurred. The universal learner performance is measured by the regret relative to the best hypothesis matching the data, chosen from $\Theta$. Utilizing the minimax theorem and information theoretical tools, we derive the optimal universal learner, a mixture over the set of the data generating distributions, and get a closed form expression for the min-max regret. We show that this regret can be considered as a constrained version of the conditional capacity between the data and its generating distributions set. We present tight bounds for this min-max regret, implying that the complexity of the problem is dominated by the richness of the hypotheses models $\Theta$ and not by the data generating distributions set $\Phi$. We develop an extension to the Arimoto-Blahut algorithm for numerical evaluation of the regret and its capacity achieving prior distribution. We demonstrate our results for the case where the observations come from a $K$-parameters multinomial distributions while the hypothesis class $\Theta$ is only a subset of this family of distributions.