 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Universality Lens: Why Even Highly Over-Parametrized Models Learn Well
Jun 09, 2025A fundamental question in modern machine learning is why large, over-parameterized models, such as deep neural networks and transformers, tend to generalize well, even when their number of parameters far exceeds the number of training samples. We investigate this phenomenon through the lens of information theory, grounded in universal learning theory. Specifically, we study a Bayesian mixture learner with log-loss and (almost) uniform prior over an expansive hypothesis class. Our key result shows that the learner's regret is not determined by the overall size of the hypothesis class, but rather by the cumulative probability of all models that are close, in Kullback-Leibler divergence distance, to the true data-generating process. We refer to this cumulative probability as the weight of the hypothesis. This leads to a natural notion of model simplicity: simple models are those with large weight and thus require fewer samples to generalize, while complex models have small weight and need more data. This perspective provides a rigorous and intuitive explanation for why over-parameterized models often avoid overfitting: the presence of simple hypotheses allows the posterior to concentrate on them when supported by the data. We further bridge theory and practice by recalling that stochastic gradient descent with Langevin dynamics samples from the correct posterior distribution, enabling our theoretical learner to be approximated using standard machine learning methods combined with ensemble learning. Our analysis yields non-uniform regret bounds and aligns with key practical concepts such as flat minima and model distillation. The results apply broadly across online, batch, and supervised learning settings, offering a unified and principled understanding of the generalization behavior of modern AI systems.
Efficient Data-Dependent Learnability
Nov 20, 2020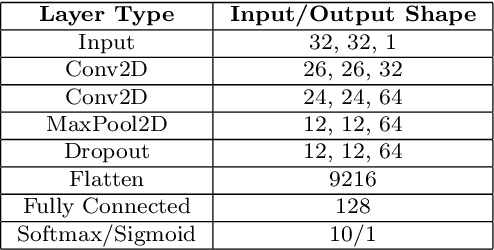
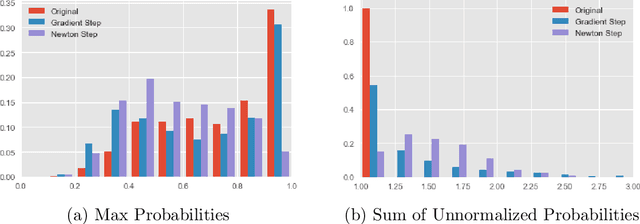
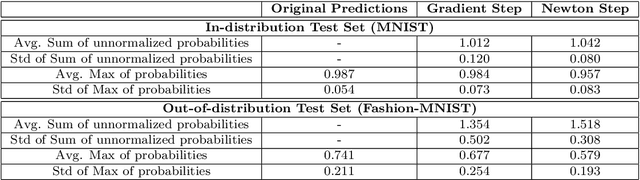
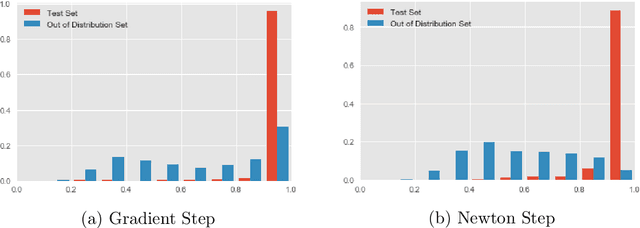
The predictive normalized maximum likelihood (pNML) approach has recently been proposed as the min-max optimal solution to the batch learning problem where both the training set and the test data feature are individuals, known sequences. This approach has yields a learnability measure that can also be interpreted as a stability measure. This measure has shown some potential in detecting out-of-distribution examples, yet it has considerable computational costs. In this project, we propose and analyze an approximation of the pNML, which is based on influence functions. Combining both theoretical analysis and experiments, we show that when applied to neural networks, this approximation can detect out-of-distribution examples effectively. We also compare its performance to that achieved by conducting a single gradient step for each possible label.
A New Look at an Old Problem: A Universal Learning Approach to Linear Regression
May 12, 2019

Linear regression is a classical paradigm in statistics. A new look at it is provided via the lens of universal learning. In applying universal learning to linear regression the hypotheses class represents the label $y\in {\cal R}$ as a linear combination of the feature vector $x^T\theta$ where $x\in {\cal R}^M$, within a Gaussian error. The Predictive Normalized Maximum Likelihood (pNML) solution for universal learning of individual data can be expressed analytically in this case, as well as its associated learnability measure. Interestingly, the situation where the number of parameters $M$ may even be larger than the number of training samples $N$ can be examined. As expected, in this case learnability cannot be attained in every situation; nevertheless, if the test vector resides mostly in a subspace spanned by the eigenvectors associated with the large eigenvalues of the empirical correlation matrix of the training data, linear regression can generalize despite the fact that it uses an ``over-parametrized'' model. We demonstrate the results with a simulation of fitting a polynomial to data with a possibly large polynomial degree.
Deep pNML: Predictive Normalized Maximum Likelihood for Deep Neural Networks
Apr 28, 2019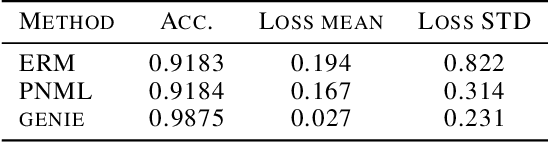
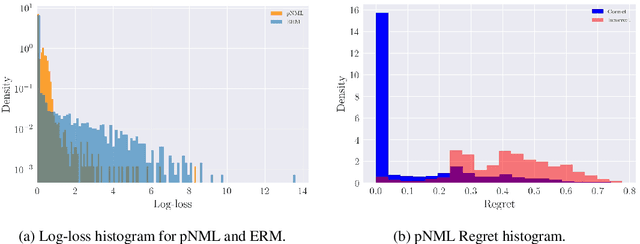
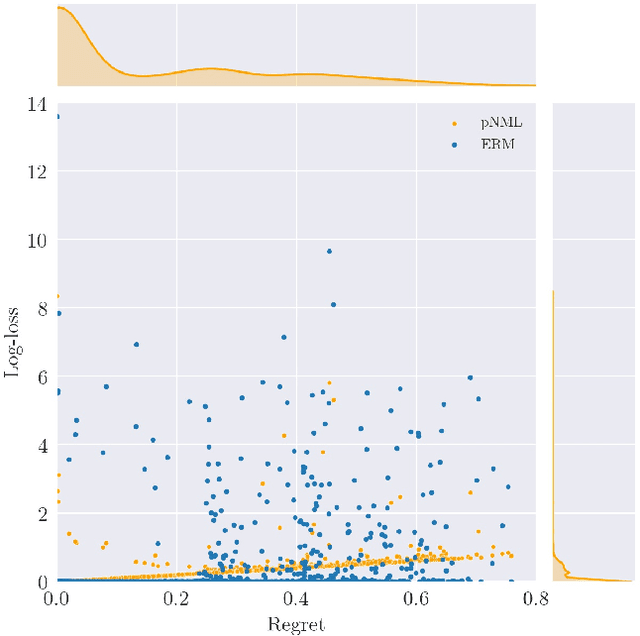
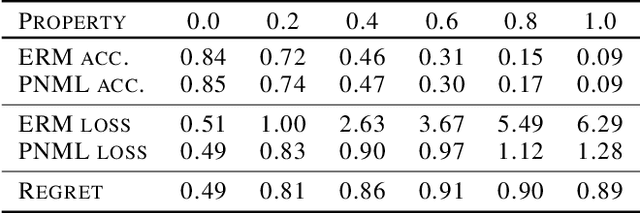
The Predictive Normalized Maximum Likelihood (pNML) scheme has been recently suggested for universal learning in the individual setting, where both the training and test samples are individual data. The goal of universal learning is to compete with a ``genie'' or reference learner that knows the data values, but is restricted to use a learner from a given model class. The pNML minimizes the associated regret for any possible value of the unknown label. Furthermore, its min-max regret can serve as a pointwise measure of learnability for the specific training and data sample. In this work we examine the pNML and its associated learnability measure for the Deep Neural Network (DNN) model class. As shown, the pNML outperforms the commonly used Empirical Risk Minimization (ERM) approach and provides robustness against adversarial attacks. Together with its learnability measure it can detect out of distribution test examples, be tolerant to noisy labels and serve as a confidence measure for the ERM. Finally, we extend the pNML to a ``twice universal'' solution, that provides universality for model class selection and generates a learner competing with the best one from all model classes.
Universal Supervised Learning for Individual Data
Dec 22, 2018
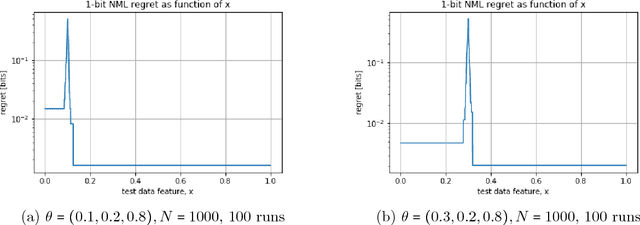
Universal supervised learning is considered from an information theoretic point of view following the universal prediction approach, see Merhav and Feder (1998). We consider the standard supervised "batch" learning where prediction is done on a test sample once the entire training data is observed, and the individual setting where the features and labels, both in the training and test, are specific individual quantities. The information theoretic approach naturally uses the self-information loss or log-loss. Our results provide universal learning schemes that compete with a "genie" (or reference) that knows the true test label. In particular, it is demonstrated that the main proposed scheme, termed Predictive Normalized Maximum Likelihood (pNML), is a robust learning solution that outperforms the current leading approach based on Empirical Risk Minimization (ERM). Furthermore, the pNML construction provides a pointwise indication for the learnability of the specific test challenge with the given training examples