 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Memory Replay in Large Scale Continual Learning
Oct 06, 2020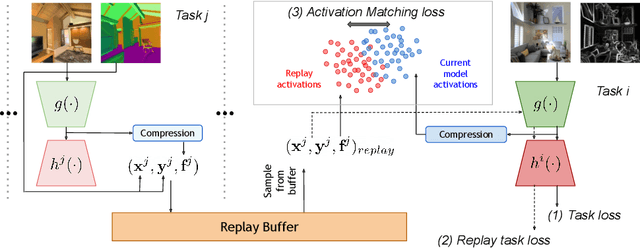
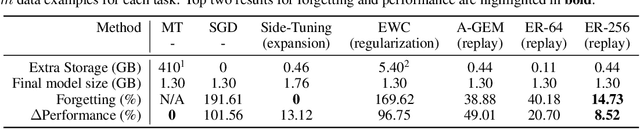
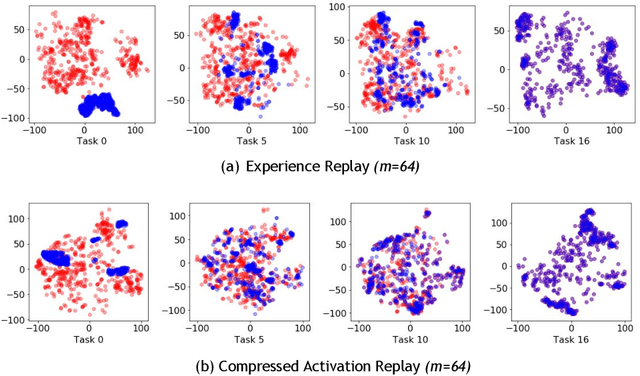
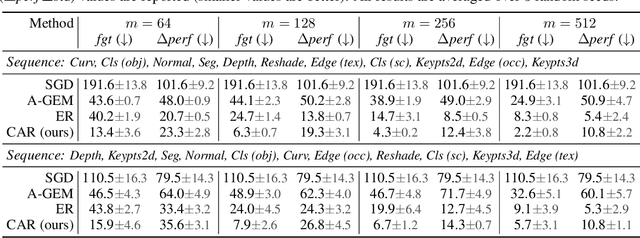
We study continual learning in the large scale setting where tasks in the input sequence are not limited to classification, and the outputs can be of high dimension. Among multiple state-of-the-art methods, we found vanilla experience replay (ER) still very competitive in terms of both performance and scalability, despite its simplicity. However, a degraded performance is observed for ER with small memory. A further visualization of the feature space reveals that the intermediate representation undergoes a distributional drift. While existing methods usually replay only the input-output pairs, we hypothesize that their regularization effect is inadequate for complex deep models and diverse tasks with small replay buffer size. Following this observation, we propose to replay the activation of the intermediate layers in addition to the input-output pairs. Considering that saving raw activation maps can dramatically increase memory and compute cost, we propose the Compressed Activation Replay technique, where compressed representations of layer activation are saved to the replay buffer. We show that this approach can achieve superior regularization effect while adding negligible memory overhead to replay method. Experiments on both the large-scale Taskonomy benchmark with a diverse set of tasks and standard common datasets (Split-CIFAR and Split-miniImageNet) demonstrate the effectiveness of the proposed method.
Towards Robust Image Classification Using Sequential Attention Models
Dec 04, 2019
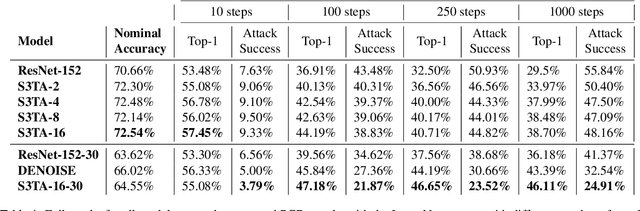

In this paper we propose to augment a modern neural-network architecture with an attention model inspired by human perception. Specifically, we adversarially train and analyze a neural model incorporating a human inspired, visual attention component that is guided by a recurrent top-down sequential process. Our experimental evaluation uncovers several notable findings about the robustness and behavior of this new model. First, introducing attention to the model significantly improves adversarial robustness resulting in state-of-the-art ImageNet accuracies under a wide range of random targeted attack strengths. Second, we show that by varying the number of attention steps (glances/fixations) for which the model is unrolled, we are able to make its defense capabilities stronger, even in light of stronger attacks --- resulting in a "computational race" between the attacker and the defender. Finally, we show that some of the adversarial examples generated by attacking our model are quite different from conventional adversarial examples --- they contain global, salient and spatially coherent structures coming from the target class that would be recognizable even to a human, and work by distracting the attention of the model away from the main object in the original image.
Orthogonal Gradient Descent for Continual Learning
Oct 15, 2019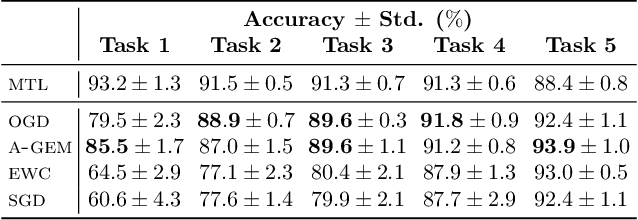
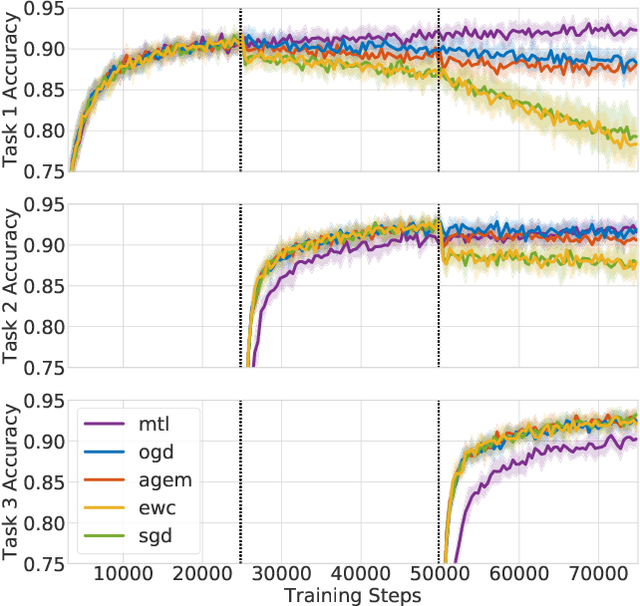
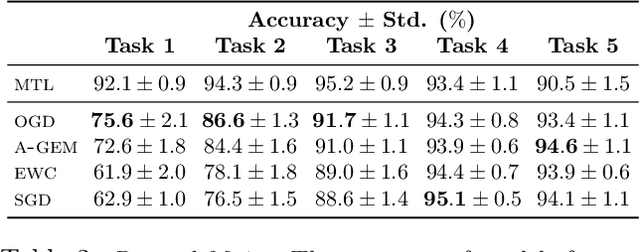
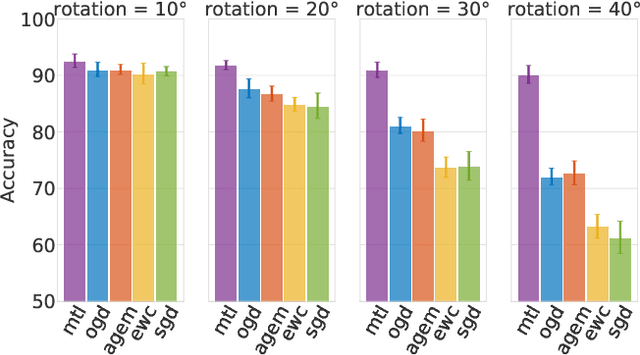
Neural networks are achieving state of the art and sometimes super-human performance on learning tasks across a variety of domains. Whenever these problems require learning in a continual or sequential manner, however, neural networks suffer from the problem of catastrophic forgetting; they forget how to solve previous tasks after being trained on a new task, despite having the essential capacity to solve both tasks if they were trained on both simultaneously. In this paper, we propose to address this issue from a parameter space perspective and study an approach to restrict the direction of the gradient updates to avoid forgetting previously-learned data. We present the Orthogonal Gradient Descent (OGD) method, which accomplishes this goal by projecting the gradients from new tasks onto a subspace in which the neural network output on previous task does not change and the projected gradient is still in a useful direction for learning the new task. Our approach utilizes the high capacity of a neural network more efficiently and does not require storing the previously learned data that might raise privacy concerns. Experiments on common benchmarks reveal the effectiveness of the proposed OGD method.
Quantum adiabatic machine learning with zooming
Aug 13, 2019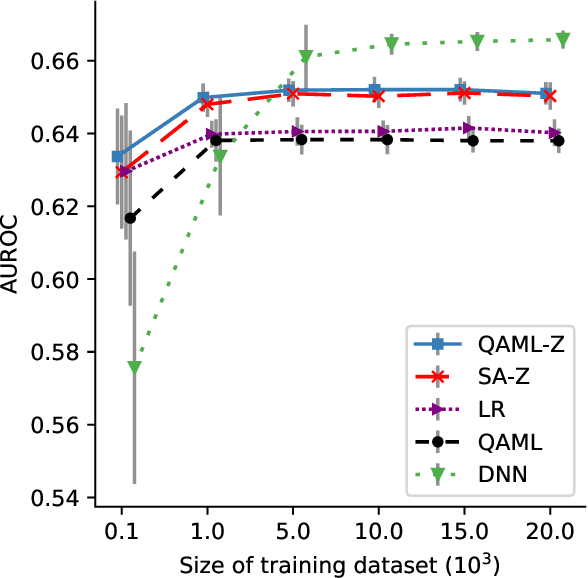

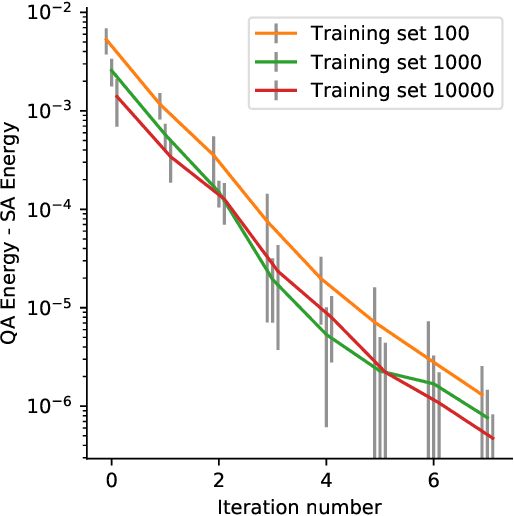
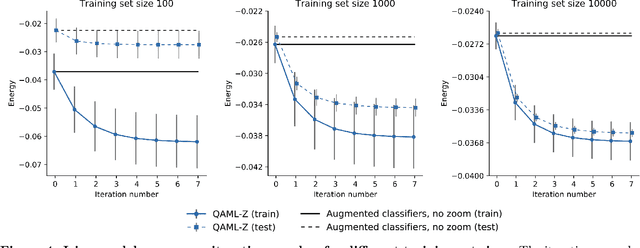
Recent work has shown that quantum annealing for machine learning (QAML) can perform comparably to state-of-the-art machine learning methods with a specific application to Higgs boson classification. We propose a variant algorithm (QAML-Z) that iteratively zooms in on a region of the energy surface by mapping the problem to a continuous space and sequentially applying quantum annealing to an augmented set of weak classifiers. Results on a programmable quantum annealer show that QAML-Z increases the performance difference between QAML and classical deep neural networks by over 40% as measured by area under the ROC curve for small training set sizes. Furthermore, QAML-Z reduces the advantage of deep neural networks over QAML for large training sets by around 50%, indicating that QAML-Z produces stronger classifiers that retain the robustness of the original QAML algorithm.
Towards Interpretable Reinforcement Learning Using Attention Augmented Agents
Jun 06, 2019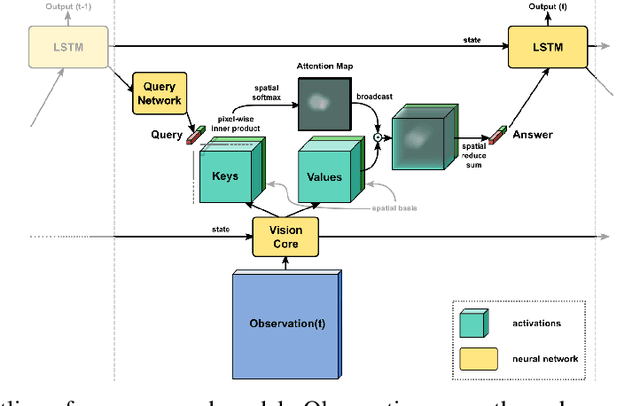
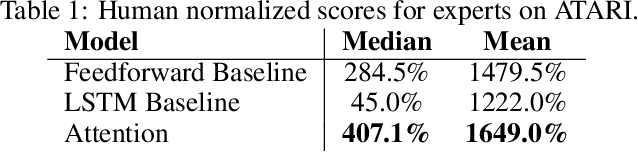

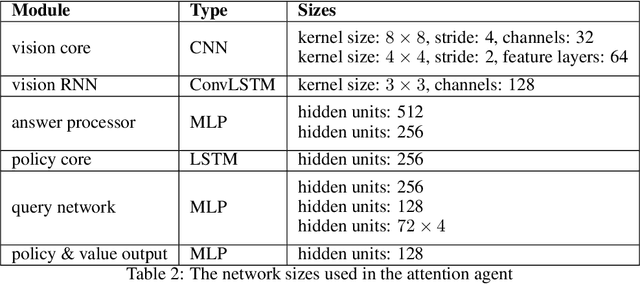
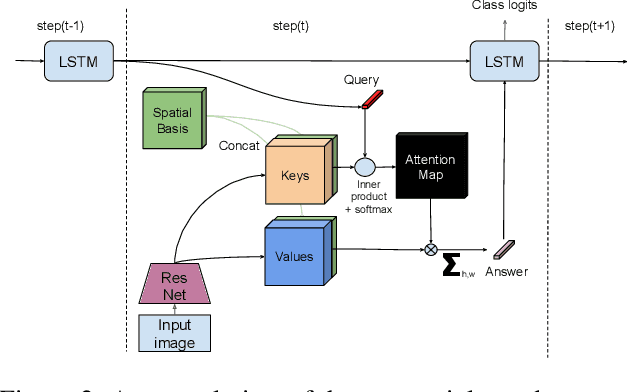
Inspired by recent work in attention models for image captioning and question answering, we present a soft attention model for the reinforcement learning domain. This model uses a soft, top-down attention mechanism to create a bottleneck in the agent, forcing it to focus on task-relevant information by sequentially querying its view of the environment. The output of the attention mechanism allows direct observation of the information used by the agent to select its actions, enabling easier interpretation of this model than of traditional models. We analyze different strategies that the agents learn and show that a handful of strategies arise repeatedly across different games. We also show that the model learns to query separately about space and content (`where' vs. `what'). We demonstrate that an agent using this mechanism can achieve performance competitive with state-of-the-art models on ATARI tasks while still being interpretable.