 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Gradient Descent for Continual Learning
Paper and Code
Oct 15, 2019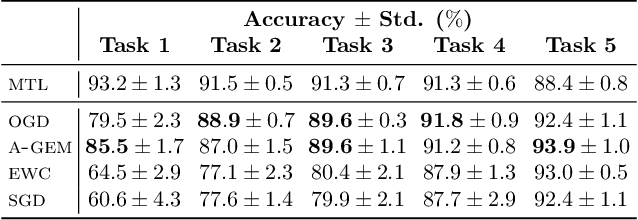
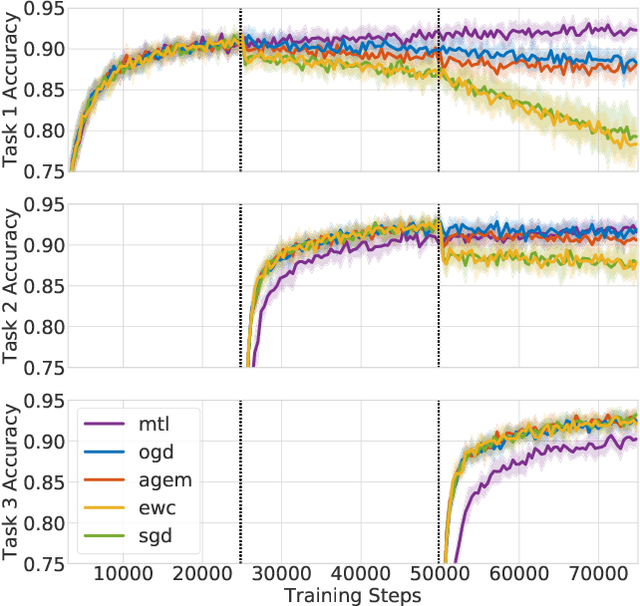
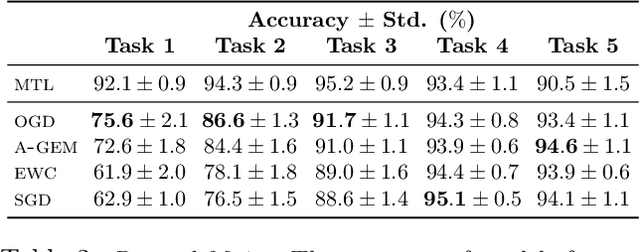
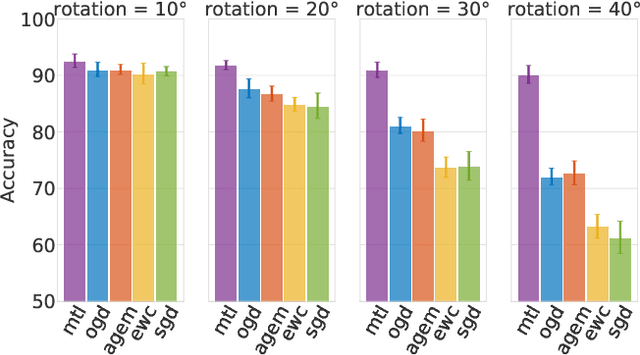
Neural networks are achieving state of the art and sometimes super-human performance on learning tasks across a variety of domains. Whenever these problems require learning in a continual or sequential manner, however, neural networks suffer from the problem of catastrophic forgetting; they forget how to solve previous tasks after being trained on a new task, despite having the essential capacity to solve both tasks if they were trained on both simultaneously. In this paper, we propose to address this issue from a parameter space perspective and study an approach to restrict the direction of the gradient updates to avoid forgetting previously-learned data. We present the Orthogonal Gradient Descent (OGD) method, which accomplishes this goal by projecting the gradients from new tasks onto a subspace in which the neural network output on previous task does not change and the projected gradient is still in a useful direction for learning the new task. Our approach utilizes the high capacity of a neural network more efficiently and does not require storing the previously learned data that might raise privacy concerns. Experiments on common benchmarks reveal the effectiveness of the proposed OGD method.