 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Reinforcement Learning Using Attention Augmented Agents
Paper and Code
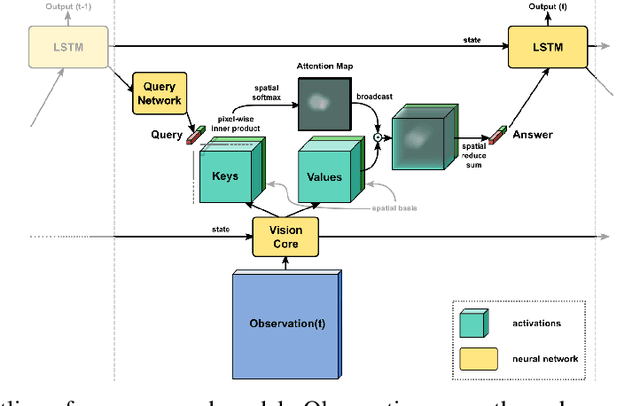
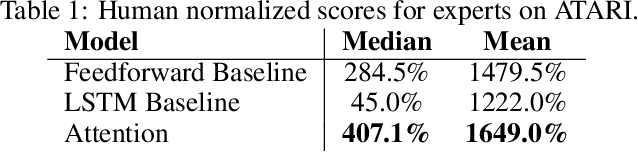

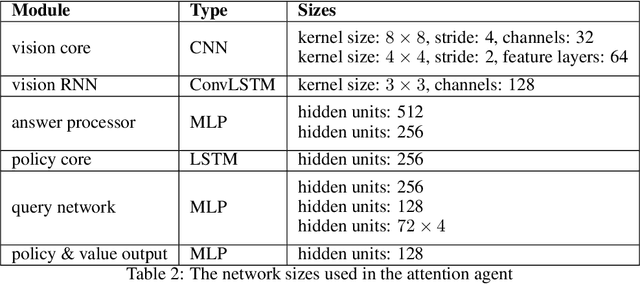
Inspired by recent work in attention models for image captioning and question answering, we present a soft attention model for the reinforcement learning domain. This model uses a soft, top-down attention mechanism to create a bottleneck in the agent, forcing it to focus on task-relevant information by sequentially querying its view of the environment. The output of the attention mechanism allows direct observation of the information used by the agent to select its actions, enabling easier interpretation of this model than of traditional models. We analyze different strategies that the agents learn and show that a handful of strategies arise repeatedly across different games. We also show that the model learns to query separately about space and content (`where' vs. `what'). We demonstrate that an agent using this mechanism can achieve performance competitive with state-of-the-art models on ATARI tasks while still being interpretable.