 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pathologist-Informed Workflow for Classification of Prostate Glands in Histopathology
Sep 27, 2022Pathologists diagnose and grade prostate cancer by examining tissue from needle biopsies on glass slides. The cancer's severity and risk of metastasis are determined by the Gleason grade, a score based on the organization and morphology of prostate cancer glands. For diagnostic work-up, pathologists first locate glands in the whole biopsy core, and -- if they detect cancer -- they assign a Gleason grade. This time-consuming process is subject to errors and significant inter-observer variability, despite strict diagnostic criteria. This paper proposes an automated workflow that follows pathologists' \textit{modus operandi}, isolating and classifying multi-scale patches of individual glands in whole slide images (WSI) of biopsy tissues using distinct steps: (1) two fully convolutional networks segment epithelium versus stroma and gland boundaries, respectively; (2) a classifier network separates benign from cancer glands at high magnification; and (3) an additional classifier predicts the grade of each cancer gland at low magnification. Altogether, this process provides a gland-specific approach for prostate cancer grading that we compare against other machine-learning-based grading methods.
* Published as a workshop paper at MICCAI MOVI 2022
Stain based contrastive co-training for histopathological image analysis
Jun 24, 2022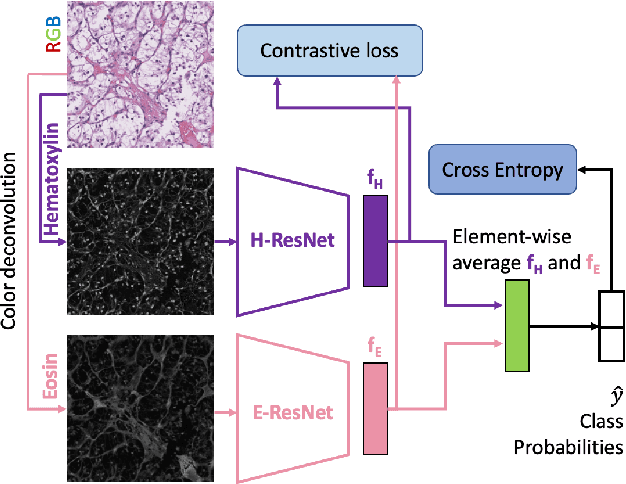
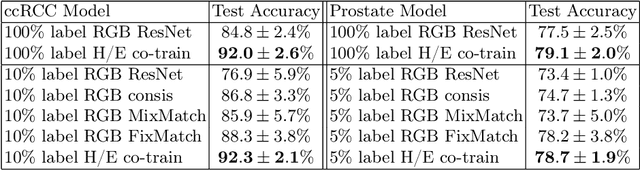

We propose a novel semi-supervised learning approach for classification of histopathology images. We employ strong supervision with patch-level annotations combined with a novel co-training loss to create a semi-supervised learning framework. Co-training relies on multiple conditionally independent and sufficient views of the data. We separate the hematoxylin and eosin channels in pathology images using color deconvolution to create two views of each slide that can partially fulfill these requirements. Two separate CNNs are used to embed the two views into a joint feature space. We use a contrastive loss between the views in this feature space to implement co-training. We evaluate our approach in clear cell renal cell and prostate carcinomas, and demonstrate improvement over state-of-the-art semi-supervised learning methods.
SetGANs: Enforcing Distributional Accuracy in Generative Adversarial Networks
Jun 28, 2019
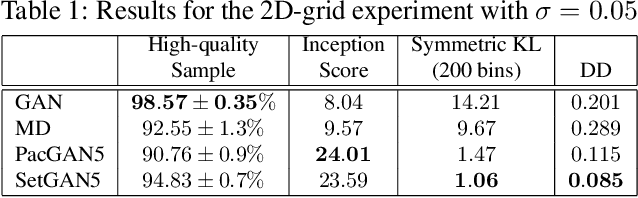

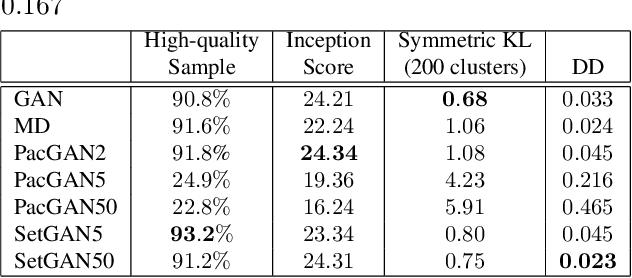
This paper addresses the ability of generative adversarial networks (GANs) to model complex distributions of data in high-dimensional spaces. Our proposition is that the more effective the adversary is in discriminating the output of the generator, the more effective the generator will be at modeling (or generating) the distribution represented by the training data. The most extreme failure of GANs in this context is mode collapse, and there are several proposed methods to address that problem. However, mode collapse is merely a symptom of a more general problem of GANs, where the generator fools the adversary while failing to faithfully model the distribution of the training data. Here, we address the challenge of constructing and evaluating GANs that more effectively represent the input distribution. We introduce an adversarial architecture that processes sets of generated and real samples, and discriminates between the origins of these sets (i.e., training versus generated data) in a flexible, permutation invariant manner. We present quantitative and qualitative results that demonstrate the effectiveness of this approach relative to state-of-the-art methods for avoiding mode collapse.