 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetGANs: Enforcing Distributional Accuracy in Generative Adversarial Networks
Paper and Code
Jun 28, 2019
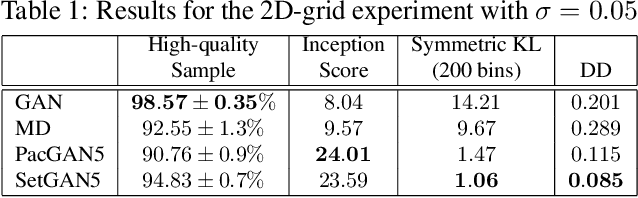

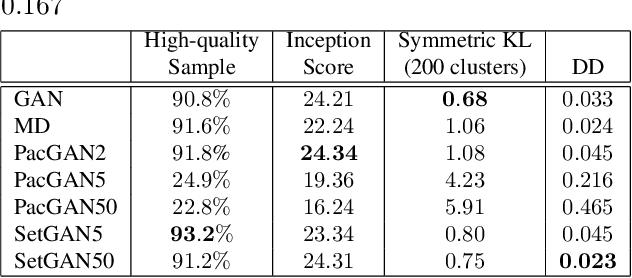
This paper addresses the ability of generative adversarial networks (GANs) to model complex distributions of data in high-dimensional spaces. Our proposition is that the more effective the adversary is in discriminating the output of the generator, the more effective the generator will be at modeling (or generating) the distribution represented by the training data. The most extreme failure of GANs in this context is mode collapse, and there are several proposed methods to address that problem. However, mode collapse is merely a symptom of a more general problem of GANs, where the generator fools the adversary while failing to faithfully model the distribution of the training data. Here, we address the challenge of constructing and evaluating GANs that more effectively represent the input distribution. We introduce an adversarial architecture that processes sets of generated and real samples, and discriminates between the origins of these sets (i.e., training versus generated data) in a flexible, permutation invariant manner. We present quantitative and qualitative results that demonstrate the effectiveness of this approach relative to state-of-the-art methods for avoiding mode collapse.