 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPRF: A Transformer-based Pseudo-Relevance Feedback Model for Efficient and Effective Retrieval
Jan 24, 2024


This paper considers Pseudo-Relevance Feedback (PRF) methods for dense retrievers in a resource constrained environment such as that of cheap cloud instances or embedded systems (e.g., smartphones and smartwatches), where memory and CPU are limited and GPUs are not present. For this, we propose a transformer-based PRF method (TPRF), which has a much smaller memory footprint and faster inference time compared to other deep language models that employ PRF mechanisms, with a marginal effectiveness loss. TPRF learns how to effectively combine the relevance feedback signals from dense passage representations. Specifically, TPRF provides a mechanism for modelling relationships and weights between the query and the relevance feedback signals. The method is agnostic to the specific dense representation used and thus can be generally applied to any dense retriever.
AgAsk: An Agent to Help Answer Farmer's Questions From Scientific Documents
Dec 21, 2022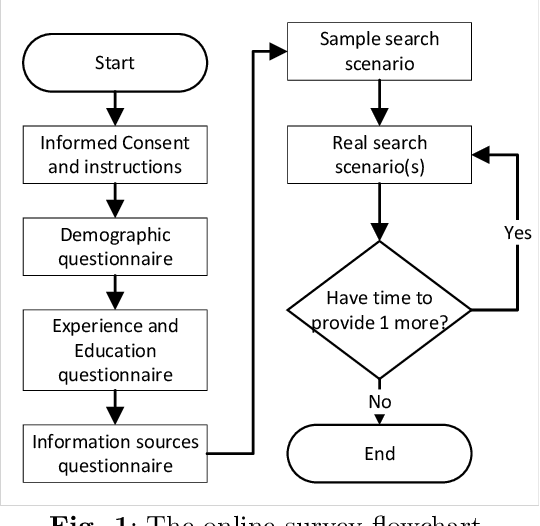

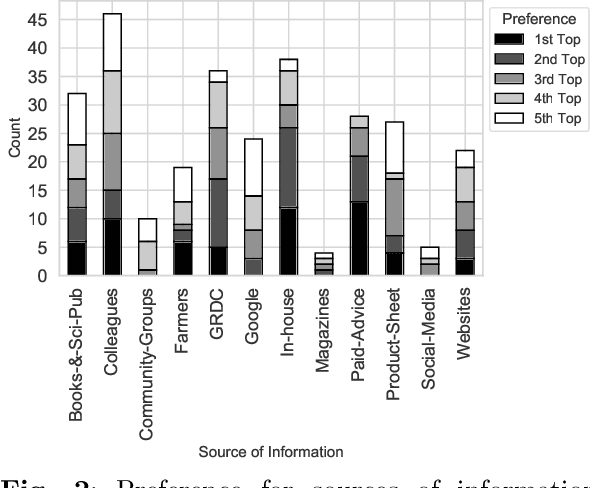
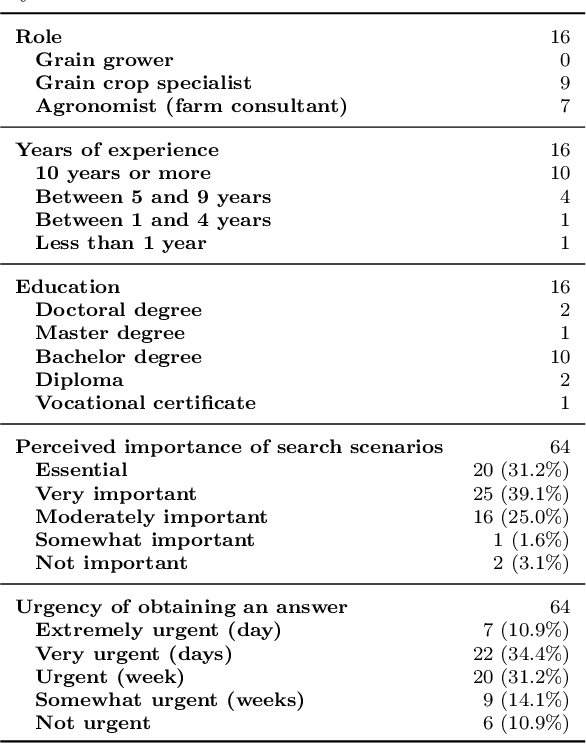
Decisions in agriculture are increasingly data-driven; however, valuable agricultural knowledge is often locked away in free-text reports, manuals and journal articles. Specialised search systems are needed that can mine agricultural information to provide relevant answers to users' questions. This paper presents AgAsk -- an agent able to answer natural language agriculture questions by mining scientific documents. We carefully survey and analyse farmers' information needs. On the basis of these needs we release an information retrieval test collection comprising real questions, a large collection of scientific documents split in passages, and ground truth relevance assessments indicating which passages are relevant to each question. We implement and evaluate a number of information retrieval models to answer farmers questions, including two state-of-the-art neural ranking models. We show that neural rankers are highly effective at matching passages to questions in this context. Finally, we propose a deployment architecture for AgAsk that includes a client based on the Telegram messaging platform and retrieval model deployed on commodity hardware. The test collection we provide is intended to stimulate more research in methods to match natural language to answers in scientific documents. While the retrieval models were evaluated in the agriculture domain, they are generalisable and of interest to others working on similar problems. The test collection is available at: \url{https://github.com/ielab/agvaluate}.
How does Feedback Signal Quality Impact Effectiveness of Pseudo Relevance Feedback for Passage Retrieval?
May 12, 2022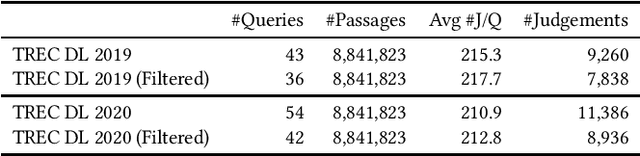
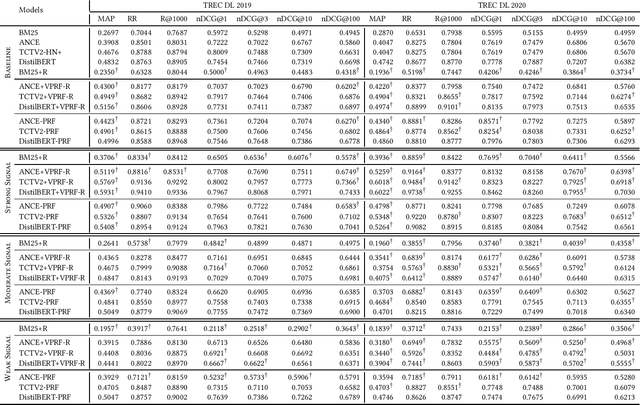
Pseudo-Relevance Feedback (PRF) assumes that the top results retrieved by a first-stage ranker are relevant to the original query and uses them to improve the query representation for a second round of retrieval. This assumption however is often not correct: some or even all of the feedback documents may be irrelevant. Indeed, the effectiveness of PRF methods may well depend on the quality of the feedback signal and thus on the effectiveness of the first-stage ranker. This aspect however has received little attention before. In this paper we control the quality of the feedback signal and measure its impact on a range of PRF methods, including traditional bag-of-words methods (Rocchio), and dense vector-based methods (learnt and not learnt). Our results show the important role the quality of the feedback signal plays on the effectiveness of PRF methods. Importantly, and surprisingly, our analysis reveals that not all PRF methods are the same when dealing with feedback signals of varying quality. These findings are critical to gain a better understanding of the PRF methods and of which and when they should be used, depending on the feedback signal quality, and set the basis for future research in this area.
To Interpolate or not to Interpolate: PRF, Dense and Sparse Retrievers
Apr 30, 2022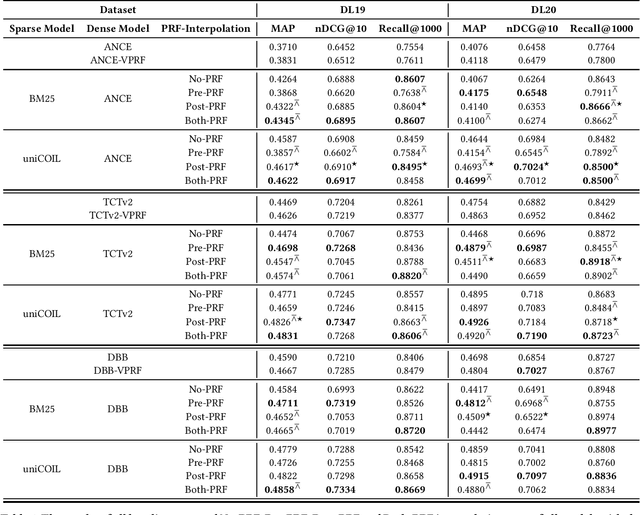
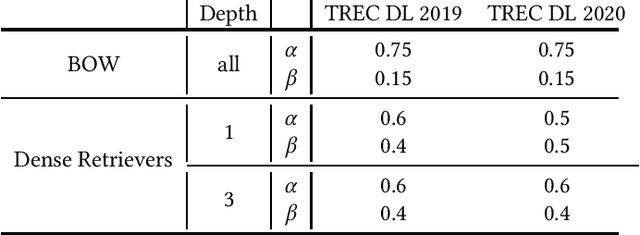
Current pre-trained language model approaches to information retrieval can be broadly divided into two categories: sparse retrievers (to which belong also non-neural approaches such as bag-of-words methods, e.g., BM25) and dense retrievers. Each of these categories appears to capture different characteristics of relevance. Previous work has investigated how relevance signals from sparse retrievers could be combined with those from dense retrievers via interpolation. Such interpolation would generally lead to higher retrieval effectiveness. In this paper we consider the problem of combining the relevance signals from sparse and dense retrievers in the context of Pseudo Relevance Feedback (PRF). This context poses two key challenges: (1) When should interpolation occur: before, after, or both before and after the PRF process? (2) Which sparse representation should be considered: a zero-shot bag-of-words model (BM25), or a learnt sparse representation? To answer these questions we perform a thorough empirical evaluation considering an effective and scalable neural PRF approach (Vector-PRF), three effective dense retrievers (ANCE, TCTv2, DistillBERT), and one state-of-the-art learnt sparse retriever (uniCOIL). The empirical findings from our experiments suggest that, regardless of sparse representation and dense retriever, interpolation both before and after PRF achieves the highest effectiveness across most datasets and metrics.
Improving Query Representations for Dense Retrieval with Pseudo Relevance Feedback: A Reproducibility Study
Dec 13, 2021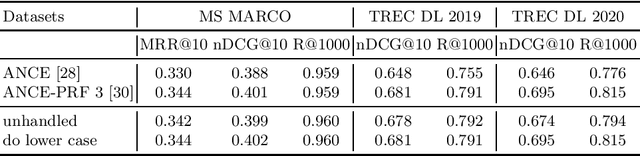
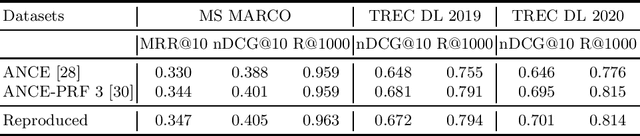
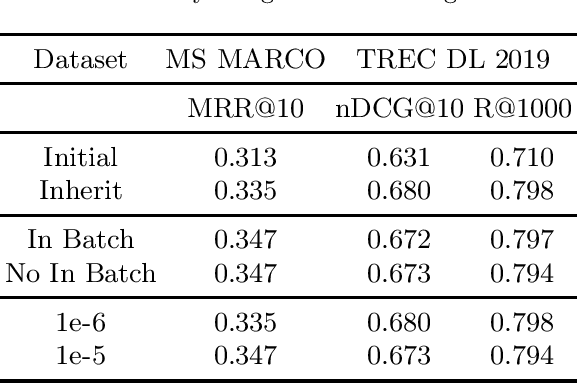
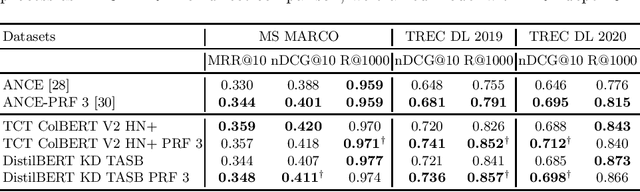
Pseudo-Relevance Feedback (PRF) utilises the relevance signals from the top-k passages from the first round of retrieval to perform a second round of retrieval aiming to improve search effectiveness. A recent research direction has been the study and development of PRF methods for deep language models based rankers, and in particular in the context of dense retrievers. Dense retrievers, compared to more complex neural rankers, provide a trade-off between effectiveness, which is often reduced compared to more complex neural rankers, and query latency, which also is reduced making the retrieval pipeline more efficient. The introduction of PRF methods for dense retrievers has been motivated as an attempt to further improve their effectiveness. In this paper, we reproduce and study a recent method for PRF with dense retrievers, called ANCE-PRF. This method concatenates the query text and that of the top-k feedback passages to form a new query input, which is then encoded into a dense representation using a newly trained query encoder based on the original dense retriever used for the first round of retrieval. While the method can potentially be applied to any of the existing dense retrievers, prior work has studied it only in the context of the ANCE dense retriever. We study the reproducibility of ANCE-PRF in terms of both its training (encoding of the PRF signal) and inference (ranking) steps. We further extend the empirical analysis provided in the original work to investigate the effect of the hyper-parameters that govern the training process and the robustness of the method across these different settings. Finally, we contribute a study of the generalisability of the ANCE-PRF method when dense retrievers other than ANCE are used for the first round of retrieval and for encoding the PRF signal.
Seed-driven Document Ranking for Systematic Reviews: A Reproducibility Study
Dec 08, 2021
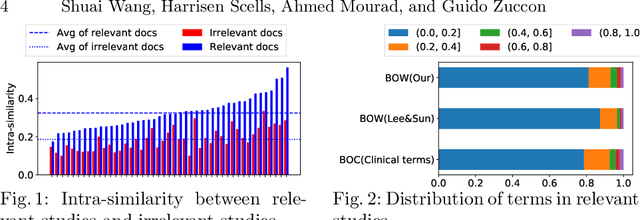
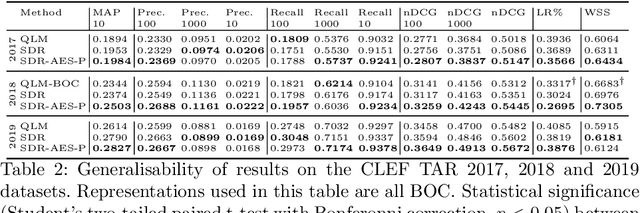
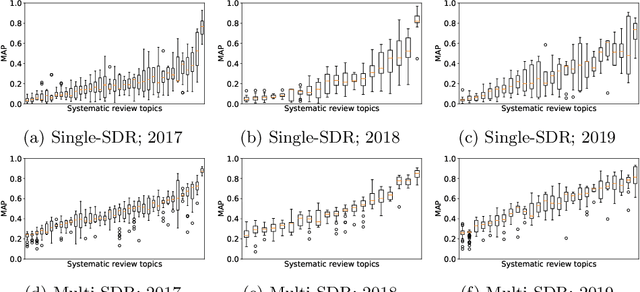
Screening or assessing studies is critical to the quality and outcomes of a systematic review. Typically, a Boolean query retrieves the set of studies to screen. As the set of studies retrieved is unordered, screening all retrieved studies is usually required for high-quality systematic reviews. Screening prioritisation, or in other words, ranking the set of studies, enables downstream activities of a systematic review to begin in parallel. We investigate a method that exploits seed studies -- potentially relevant studies used to seed the query formulation process -- for screening prioritisation. Our investigation aims to reproduce this method to determine if it is generalisable on recently published datasets and determine the impact of using multiple seed studies on effectiveness.We show that while we could reproduce the original methods, we could not replicate their results exactly. However, we believe this is due to minor differences in document pre-processing, not deficiencies with the original methodology. Our results also indicate that our reproduced screening prioritisation method, (1) is generalisable across datasets of similar and different topicality compared to the original implementation, (2) that when using multiple seed studies, the effectiveness of the method increases using our techniques to enable this, (3) and that the use of multiple seed studies produces more stable rankings compared to single seed studies. Finally, we make our implementation and results publicly available at the following URL: https://github.com/ielab/sdr
Pseudo Relevance Feedback with Deep Language Models and Dense Retrievers: Successes and Pitfalls
Aug 25, 2021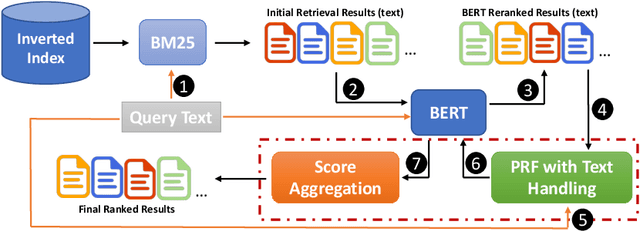
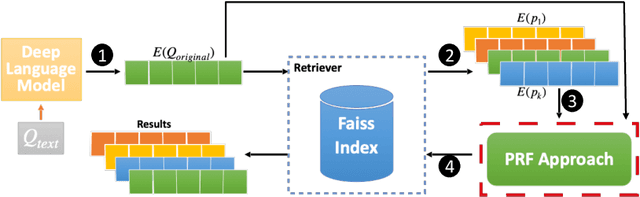
Pseudo Relevance Feedback (PRF) is known to improve the effectiveness of bag-of-words retrievers. At the same time, deep language models have been shown to outperform traditional bag-of-words rerankers. However, it is unclear how to integrate PRF directly with emergent deep language models. In this article, we address this gap by investigating methods for integrating PRF signals into rerankers and dense retrievers based on deep language models. We consider text-based and vector-based PRF approaches, and investigate different ways of combining and scoring relevance signals. An extensive empirical evaluation was conducted across four different datasets and two task settings (retrieval and ranking). Text-based PRF results show that the use of PRF had a mixed effect on deep rerankers across different datasets. We found that the best effectiveness was achieved when (i) directly concatenating each PRF passage with the query, searching with the new set of queries, and then aggregating the scores; (ii) using Borda to aggregate scores from PRF runs. Vector-based PRF results show that the use of PRF enhanced the effectiveness of deep rerankers and dense retrievers over several evaluation metrics. We found that higher effectiveness was achieved when (i) the query retains either the majority or the same weight within the PRF mechanism, and (ii) a shallower PRF signal (i.e., a smaller number of top-ranked passages) was employed, rather than a deeper signal. Our vector-based PRF method is computationally efficient; thus this represents a general PRF method others can use with deep rerankers and dense retrievers.