 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Causal Models with Hidden Variables in Polynomial Delay via Conditional Independencies
Sep 22, 2024



Testing a hypothesized causal model against observational data is a key prerequisite for many causal inference tasks. A natural approach is to test whether the conditional independence relations (CIs) assumed in the model hold in the data. While a model can assume exponentially many CIs (with respect to the number of variables), testing all of them is both impractical and unnecessary. Causal graphs, which encode these CIs in polynomial space, give rise to local Markov properties that enable model testing with a significantly smaller subset of CIs. Model testing based on local properties requires an algorithm to list the relevant CIs. However, existing algorithms for realistic settings with hidden variables and non-parametric distributions can take exponential time to produce even a single CI constraint. In this paper, we introduce the c-component local Markov property (C-LMP) for causal graphs with hidden variables. Since C-LMP can still invoke an exponential number of CIs, we develop a polynomial delay algorithm to list these CIs in poly-time intervals. To our knowledge, this is the first algorithm that enables poly-delay testing of CIs in causal graphs with hidden variables against arbitrary data distributions. Experiments on real-world and synthetic data demonstrate the practicality of our algorithm.
Center-Embedding and Constituency in the Brain and a New Characterization of Context-Free Languages
Jun 27, 2022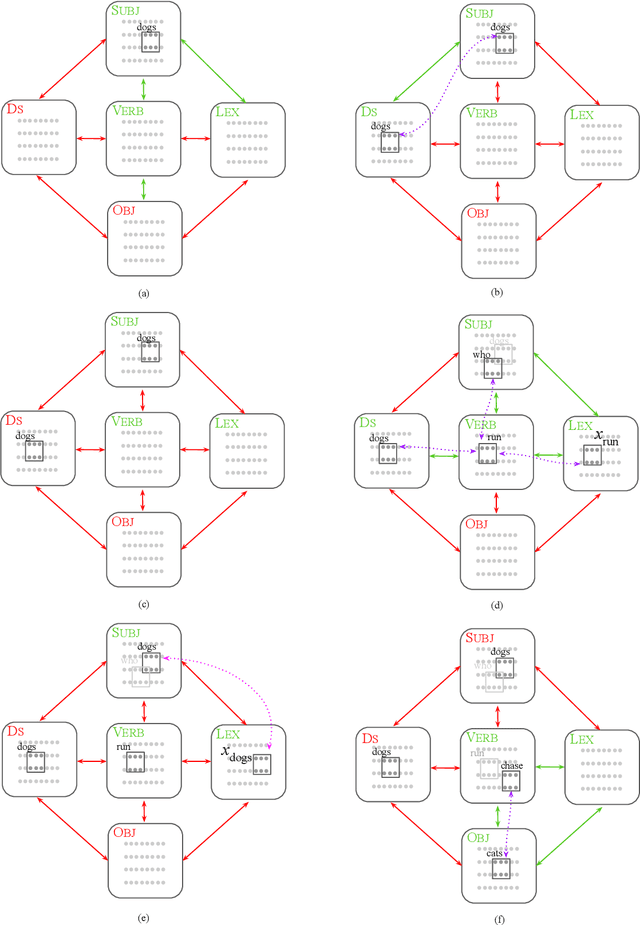
A computational system implemented exclusively through the spiking of neurons was recently shown capable of syntax, that is, of carrying out the dependency parsing of simple English sentences. We address two of the most important questions left open by that work: constituency (the identification of key parts of the sentence such as the verb phrase) and the processing of dependent sentences, especially center-embedded ones. We show that these two aspects of language can also be implemented by neurons and synapses in a way that is compatible with what is known, or widely believed, about the structure and function of the language organ. Surprisingly, the way we implement center embedding points to a new characterization of context-free languages.