 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage Optimization for Camera View Selection
Apr 06, 2026What makes a good viewpoint? The quality of the data used to learn 3D reconstructions is crucial for enabling efficient and accurate scene modeling. We study the active view selection problem and develop a principled analysis that yields a simple and interpretable criterion for selecting informative camera poses. Our key insight is that informative views can be obtained by minimizing a tractable approximation of the Fisher Information Gain, which reduces to favoring viewpoints that cover geometry that has been insufficiently observed by past cameras. This leads to a lightweight coverage-based view selection metric that avoids expensive transmittance estimation and is robust to noise and training dynamics. We call this metric COVER (Camera Optimization for View Exploration and Reconstruction). We integrate our method into the Nerfstudio framework and evaluate it on real datasets within fixed and embodied data acquisition scenarios. Across multiple datasets and radiance-field baselines, our method consistently improves reconstruction quality compared to state-of-the-art active view selection methods. Additional visualizations and our Nerfstudio package can be found at https://chengine.github.io/nbv_gym/.
Neural Radiance Maps for Extraterrestrial Navigation and Path Planning
Mar 18, 2026Autonomous vehicles such as the Mars rovers currently lead the vanguard of surface exploration on extraterrestrial planets and moons. In order to accelerate the pace of exploration and science objectives, it is critical to plan safe and efficient paths for these vehicles. However, current rover autonomy is limited by a lack of global maps which can be easily constructed and stored for onboard re-planning. Recently, Neural Radiance Fields (NeRFs) have been introduced as a detailed 3D scene representation which can be trained from sparse 2D images and efficiently stored. We propose to use NeRFs to construct maps for online use in autonomous navigation, and present a planning framework which leverages the NeRF map to integrate local and global information. Our approach interpolates local cost observations across global regions using kernel ridge regression over terrain features extracted from the NeRF map, allowing the rover to re-route itself around untraversable areas discovered during online operation. We validate our approach in high-fidelity simulation and demonstrate lower cost and higher percentage success rate path planning compared to various baselines.
Visual SLAM with DEM Anchoring for Lunar Surface Navigation
Mar 18, 2026Future lunar missions will require autonomous rovers capable of traversing tens of kilometers across challenging terrain while maintaining accurate localization and producing globally consistent maps. However, the absence of global positioning systems, extreme illumination, and low-texture regolith make long-range navigation on the Moon particularly difficult, as visual-inertial odometry pipelines accumulate drift over extended traverses. To address this challenge, we present a stereo visual simultaneous localization and mapping (SLAM) system that integrates learned feature detection and matching with global constraints from digital elevation models (DEMs). Our front-end employs learning-based feature extraction and matching to achieve robustness to illumination extremes and repetitive terrain, while the back-end incorporates DEM-derived height and surface-normal factors into a pose graph, providing absolute surface constraints that mitigate long-term drift. We validate our approach using both simulated lunar traverse data generated in Unreal Engine and real Moon/Mars analog data collected from Mt. Etna. Results demonstrate that DEM anchoring consistently reduces absolute trajectory error compared to baseline SLAM methods, lowering drift in long-range navigation even in repetitive or visually aliased terrain.
Semantic Segmentation and Depth Estimation for Real-Time Lunar Surface Mapping Using 3D Gaussian Splatting
Mar 18, 2026Navigation and mapping on the lunar surface require robust perception under challenging conditions, including poorly textured environments, high-contrast lighting, and limited computational resources. This paper presents a real-time mapping framework that integrates dense perception models with a 3D Gaussian Splatting (3DGS) representation. We first benchmark several models on synthetic datasets generated with the LuPNT simulator, selecting a stereo dense depth estimation model based on Gated Recurrent Units for its balance of speed and accuracy in depth estimation, and a convolutional neural network for its superior performance in detecting semantic segments. Using ground truth poses to decouple the local scene understanding from the global state estimation, our pipeline reconstructs a 120-meter traverse with a geometric height accuracy of approximately 3 cm, outperforming a traditional point cloud baseline without LiDAR. The resulting 3DGS map enables novel view synthesis and serves as a foundation for a full SLAM system, where its capacity for joint map and pose optimization would offer significant advantages. Our results demonstrate that combining semantic segmentation and dense depth estimation with learned map representations is an effective approach for creating detailed, large-scale maps to support future lunar surface missions.
Full Stack Navigation, Mapping, and Planning for the Lunar Autonomy Challenge
Mar 18, 2026We present a modular, full-stack autonomy system for lunar surface navigation and mapping developed for the Lunar Autonomy Challenge. Operating in a GNSS-denied, visually challenging environment, our pipeline integrates semantic segmentation, stereo visual odometry, pose graph SLAM with loop closures, and layered planning and control. We leverage lightweight learning-based perception models for real-time segmentation and feature tracking and use a factor-graph backend to maintain globally consistent localization. High-level waypoint planning is designed to promote mapping coverage while encouraging frequent loop closures, and local motion planning uses arc sampling with geometric obstacle checks for efficient, reactive control. We evaluate our approach in the competition's high-fidelity lunar simulator, demonstrating centimeter-level localization accuracy, high-fidelity map generation, and strong repeatability across random seeds and rock distributions. Our solution achieved first place in the final competition evaluation.
Multi-Robot Collaborative Localization and Planning with Inter-Ranging
Jun 24, 2024
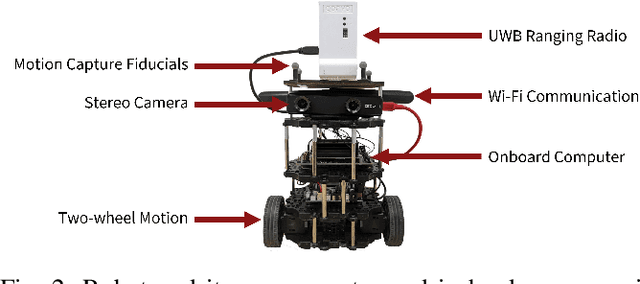
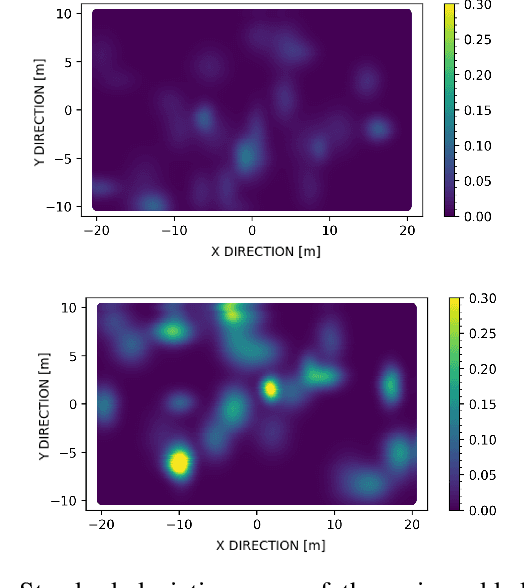
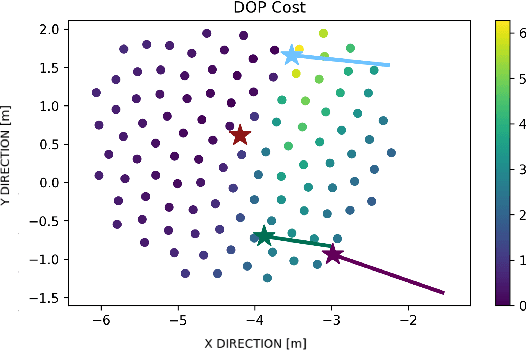
Robots often use feature-based image tracking to identify their position in their surrounding environment; however, feature-based image tracking is prone to errors in low-textured and poorly lit environments. Specifically, we investigate a scenario where robots are tasked with exploring the surface of the Moon and are required to have an accurate estimate of their position to be able to correctly geotag scientific measurements. To reduce localization error, we complement traditional feature-based image tracking with ultra-wideband (UWB) distance measurements between the robots. The robots use an advanced mesh-ranging protocol that allows them to continuously share distance measurements amongst each other rather than relying on the common "anchor" and "tag" UWB architecture. We develop a decentralized multi-robot coordination algorithm that actively plans paths based on measurement line-of-sight vectors amongst all robots to minimize collective localization error. We then demonstrate the emergent behavior of the proposed multi-robot coordination algorithm both in simulation and hardware to lower a geometry-based uncertainty metric and reduce localization error.
Neural Elevation Models for Terrain Mapping and Path Planning
May 24, 2024



This work introduces Neural Elevations Models (NEMos), which adapt Neural Radiance Fields to a 2.5D continuous and differentiable terrain model. In contrast to traditional terrain representations such as digital elevation models, NEMos can be readily generated from imagery, a low-cost data source, and provide a lightweight representation of terrain through an implicit continuous and differentiable height field. We propose a novel method for jointly training a height field and radiance field within a NeRF framework, leveraging quantile regression. Additionally, we introduce a path planning algorithm that performs gradient-based optimization of a continuous cost function for minimizing distance, slope changes, and control effort, enabled by differentiability of the height field. We perform experiments on simulated and real-world terrain imagery, demonstrating NEMos ability to generate high-quality reconstructions and produce smoother paths compared to discrete path planning methods. Future work will explore the incorporation of features and semantics into the height field, creating a generalized terrain model.
Spoofing-Resilient LiDAR-GPS Factor Graph Localization with Chimera Authentication
Jul 10, 2023



Many vehicle platforms typically use sensors such as LiDAR or camera for locally-referenced navigation with GPS for globally-referenced navigation. However, due to the unencrypted nature of GPS signals, all civilian users are vulner-able to spoofing attacks, where a malicious spoofer broadcasts fabricated signals and causes the user to track a false position fix. To protect against such GPS spoofing attacks, Chips-Message Robust Authentication (Chimera) has been developed and will be tested on the Navigation Technology Satellite 3 (NTS-3) satellite being launched later this year. However, Chimera authentication is not continuously available and may not provide sufficient protection for vehicles which rely on more frequent GPS measurements. In this paper, we propose a factor graph-based state estimation framework which integrates LiDAR and GPS while simultaneously detecting and mitigating spoofing attacks experienced between consecutive Chimera authentications. Our proposed framework combines GPS pseudorange measurements with LiDAR odometry to provide a robust navigation solution. A chi-squared detector, based on pseudorange residuals, is used to detect and mitigate any potential GPS spoofing attacks. We evaluate our method using real-world LiDAR data from the KITTI dataset and simulated GPS measurements, both nominal and with spoofing. Across multiple trajectories and Monte Carlo runs, our method consistently achieves position errors under 5 m during nominal conditions, and successfully bounds positioning error to within odometry drift levels during spoofed conditions.
PlaneSLAM: Plane-based LiDAR SLAM for Motion Planning in Structured 3D Environments
Sep 29, 2022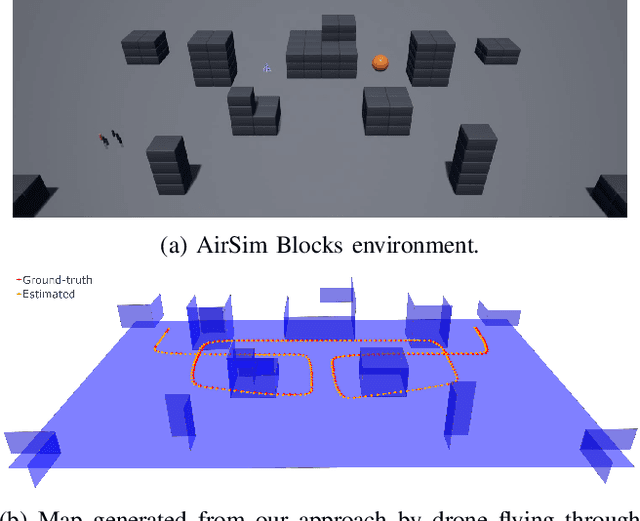
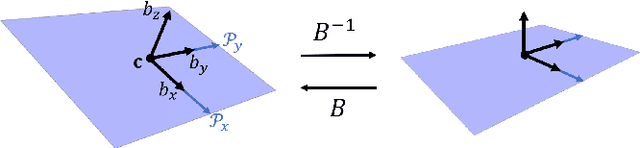
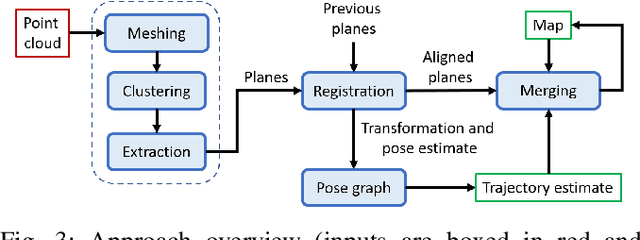
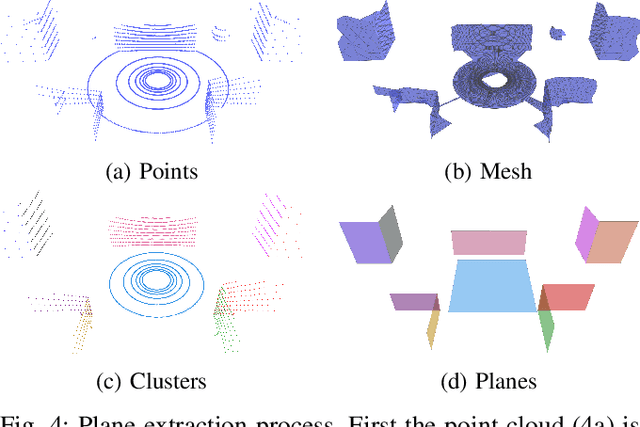
LiDAR sensors are a powerful tool for robot simultaneous localization and mapping (SLAM) in unknown environments, but the raw point clouds they produce are dense, computationally expensive to store, and unsuited for direct use by downstream autonomy tasks, such as motion planning. For integration with motion planning, it is desirable for SLAM pipelines to generate lightweight geometric map representations. Such representations are also particularly well-suited for man-made environments, which can often be viewed as a so-called "Manhattan world" built on a Cartesian grid. In this work we present a 3D LiDAR SLAM algorithm for Manhattan world environments which extracts planar features from point clouds to achieve lightweight, real-time localization and mapping. Our approach generates plane-based maps which occupy significantly less memory than their point cloud equivalents, and are suited towards fast collision checking for motion planning. By leveraging the Manhattan world assumption, we target extraction of orthogonal planes to generate maps which are more structured and organized than those of existing plane-based LiDAR SLAM approaches. We demonstrate our approach in the high-fidelity AirSim simulator and in real-world experiments with a ground rover equipped with a Velodyne LiDAR. For both cases, we are able to generate high quality maps and trajectory estimates at a rate matching the sensor rate of 10 Hz.
Constrained Feedforward Neural Network Training via Reachability Analysis
Jul 16, 2021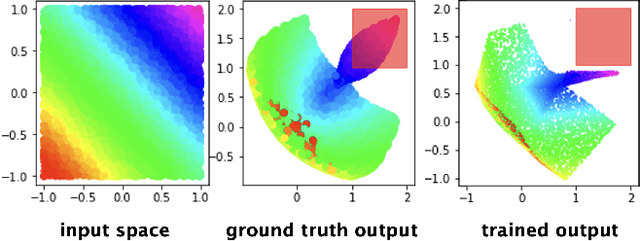
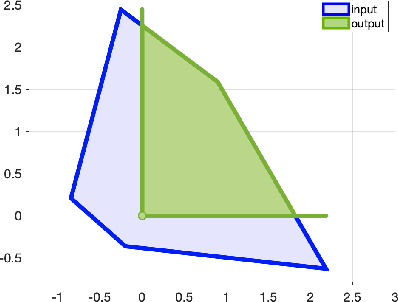
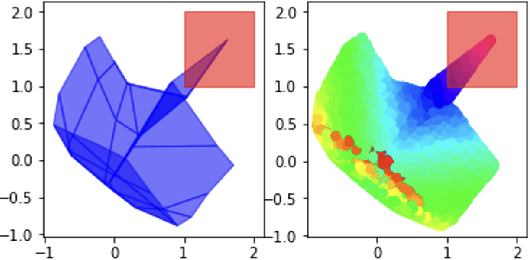
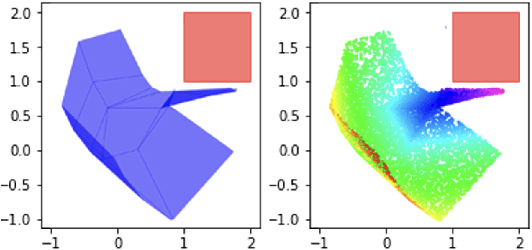
Neural networks have recently become popular for a wide variety of uses, but have seen limited application in safety-critical domains such as robotics near and around humans. This is because it remains an open challenge to train a neural network to obey safety constraints. Most existing safety-related methods only seek to verify that already-trained networks obey constraints, requiring alternating training and verification. Instead, this work proposes a constrained method to simultaneously train and verify a feedforward neural network with rectified linear unit (ReLU) nonlinearities. Constraints are enforced by computing the network's output-space reachable set and ensuring that it does not intersect with unsafe sets; training is achieved by formulating a novel collision-check loss function between the reachable set and unsafe portions of the output space. The reachable and unsafe sets are represented by constrained zonotopes, a convex polytope representation that enables differentiable collision checking. The proposed method is demonstrated successfully on a network with one nonlinearity layer and approximately 50 parameters.