 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Symmetry Breaking Constraints for Abstract Structures
Nov 14, 2025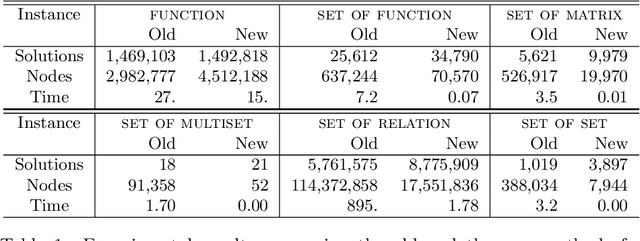
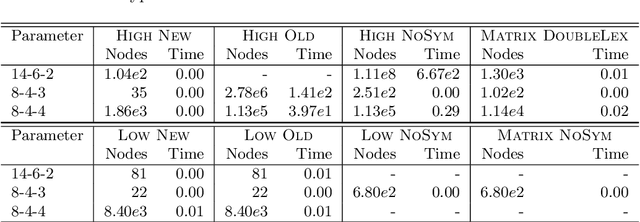
In constraint programming and related paradigms, a modeller specifies their problem in a modelling language for a solver to search and return its solution(s). Using high-level modelling languages such as Essence, a modeller may express their problems in terms of abstract structures. These are structures not natively supported by the solvers, and so they have to be transformed into or represented as other structures before solving. For example, nested sets are abstract structures, and they can be represented as matrices in constraint solvers. Many problems contain symmetries and one very common and highly successful technique used in constraint programming is to "break" symmetries, to avoid searching for symmetric solutions. This can speed up the solving process by many orders of magnitude. Most of these symmetry-breaking techniques involve placing some kind of ordering for the variables of the problem, and picking a particular member under the symmetries, usually the smallest. Unfortunately, applying this technique to abstract variables produces a very large number of complex constraints that perform poorly in practice. In this paper, we demonstrate a new incomplete method of breaking the symmetries of abstract structures by better exploiting their representations. We apply the method in breaking the symmetries arising from indistinguishable objects, a commonly occurring type of symmetry, and show that our method is faster than the previous methods proposed in (Akgün et al. 2025).
Solver-Aided Expansion of Loops to Avoid Generate-and-Test
Aug 11, 2025


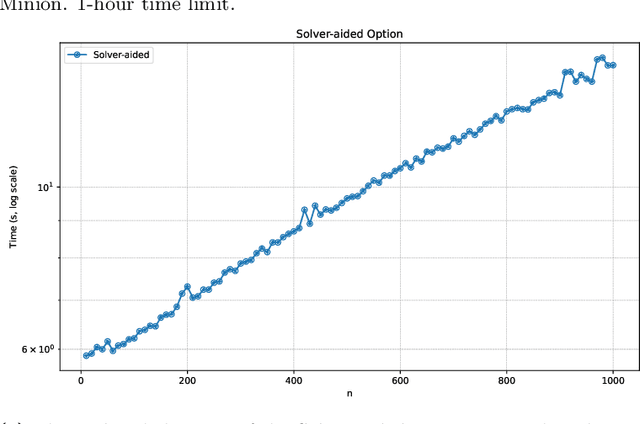
Constraint modelling languages like MiniZinc and Essence rely on unrolling loops (in the form of quantified expressions and comprehensions) during compilation. Standard approaches generate all combinations of induction variables and use partial evaluation to discard those that simplify to identity elements of associative-commutative operators (e.g. true for conjunction, 0 for summation). This can be inefficient for problems where most combinations are ultimately irrelevant. We present a method that avoids full enumeration by using a solver to compute only the combinations required to generate the final set of constraints. The resulting model is identical to that produced by conventional flattening, but compilation can be significantly faster. This improves the efficiency of translating high-level user models into solver-ready form, particularly when induction variables range over large domains with selective preconditions.
Frugal Algorithm Selection
May 17, 2024



When solving decision and optimisation problems, many competing algorithms (model and solver choices) have complementary strengths. Typically, there is no single algorithm that works well for all instances of a problem. Automated algorithm selection has been shown to work very well for choosing a suitable algorithm for a given instance. However, the cost of training can be prohibitively large due to running candidate algorithms on a representative set of training instances. In this work, we explore reducing this cost by choosing a subset of the training instances on which to train. We approach this problem in three ways: using active learning to decide based on prediction uncertainty, augmenting the algorithm predictors with a timeout predictor, and collecting training data using a progressively increasing timeout. We evaluate combinations of these approaches on six datasets from ASLib and present the reduction in labelling cost achieved by each option.
A Framework for Generating Informative Benchmark Instances
May 29, 2022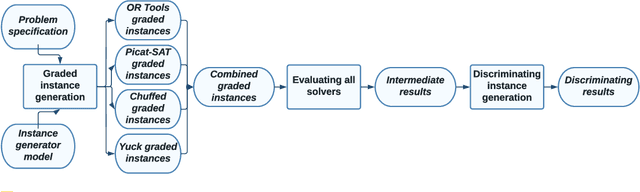
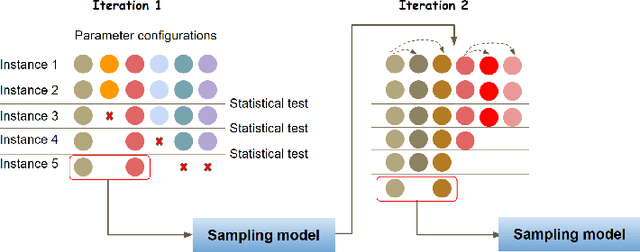
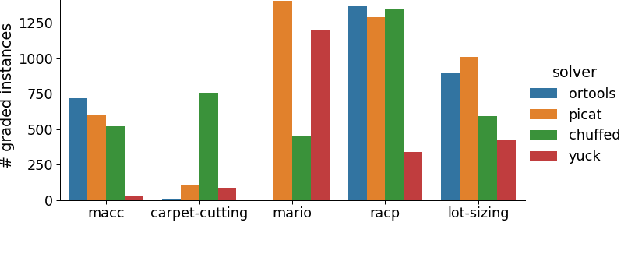
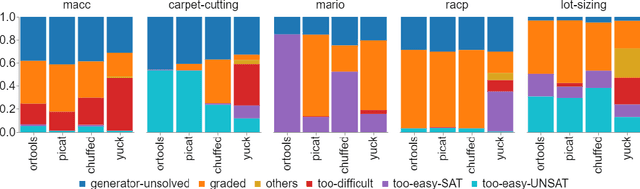
Benchmarking is an important tool for assessing the relative performance of alternative solving approaches. However, the utility of benchmarking is limited by the quantity and quality of the available problem instances. Modern constraint programming languages typically allow the specification of a class-level model that is parameterised over instance data. This separation presents an opportunity for automated approaches to generate instance data that define instances that are graded (solvable at a certain difficulty level for a solver) or can discriminate between two solving approaches. In this paper, we introduce a framework that combines these two properties to generate a large number of benchmark instances, purposely generated for effective and informative benchmarking. We use five problems that were used in the MiniZinc competition to demonstrate the usage of our framework. In addition to producing a ranking among solvers, our framework gives a broader understanding of the behaviour of each solver for the whole instance space; for example by finding subsets of instances where the solver performance significantly varies from its average performance.
Automatic Tabulation in Constraint Models
Feb 26, 2022


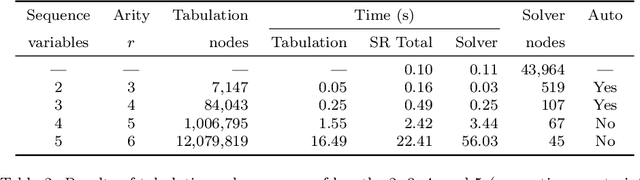
The performance of a constraint model can often be improved by converting a subproblem into a single table constraint. In this paper we study heuristics for identifying promising candidate subproblems, where converting the candidate into a table constraint is likely to improve solver performance. We propose a small set of heuristics to identify common cases, such as expressions that will propagate weakly. The process of discovering promising subproblems and tabulating them is entirely automated in the constraint modelling tool Savile Row. Caches are implemented to avoid tabulating equivalent subproblems many times. We give a simple algorithm to generate table constraints directly from a constraint expression in \savilerow. We demonstrate good performance on the benchmark problems used in earlier work on tabulation, and also for several new problem classes. In some cases, the entirely automated process leads to orders of magnitude improvements in solver performance.
Towards Reformulating Essence Specifications for Robustness
Nov 01, 2021



The Essence language allows a user to specify a constraint problem at a level of abstraction above that at which constraint modelling decisions are made. Essence specifications are refined into constraint models using the Conjure automated modelling tool, which employs a suite of refinement rules. However, Essence is a rich language in which there are many equivalent ways to specify a given problem. A user may therefore omit the use of domain attributes or abstract types, resulting in fewer refinement rules being applicable and therefore a reduced set of output models from which to select. This paper addresses the problem of recovering this information automatically to increase the robustness of the quality of the output constraint models in the face of variation in the input Essence specification. We present reformulation rules that can change the type of a decision variable or add attributes that shrink its domain. We demonstrate the efficacy of this approach in terms of the quantity and quality of models Conjure can produce from the transformed specification compared with the original.
Efficient Incremental Modelling and Solving
Sep 23, 2020

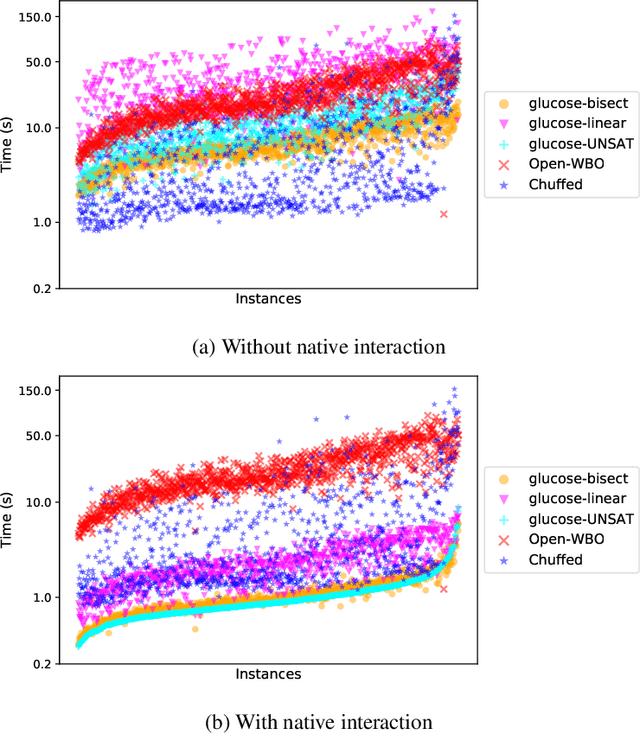
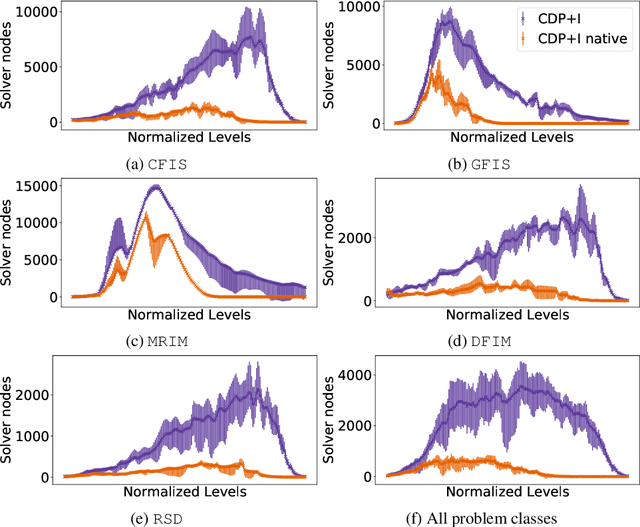
In various scenarios, a single phase of modelling and solving is either not sufficient or not feasible to solve the problem at hand. A standard approach to solving AI planning problems, for example, is to incrementally extend the planning horizon and solve the problem of trying to find a plan of a particular length. Indeed, any optimization problem can be solved as a sequence of decision problems in which the objective value is incrementally updated. Another example is constraint dominance programming (CDP), in which search is organized into a sequence of levels. The contribution of this work is to enable a native interaction between SAT solvers and the automated modelling system Savile Row to support efficient incremental modelling and solving. This allows adding new decision variables, posting new constraints and removing existing constraints (via assumptions) between incremental steps. Two additional benefits of the native coupling of modelling and solving are the ability to retain learned information between SAT solver calls and to enable SAT assumptions, further improving flexibility and efficiency. Experiments on one optimisation problem and five pattern mining tasks demonstrate that the native interaction between the modelling system and SAT solver consistently improves performance significantly.
Exploring Instance Generation for Automated Planning
Sep 21, 2020


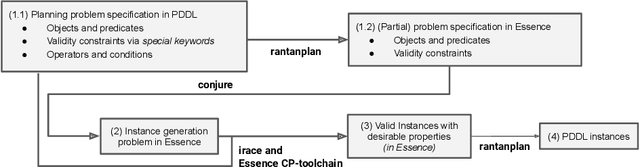
Many of the core disciplines of artificial intelligence have sets of standard benchmark problems well known and widely used by the community when developing new algorithms. Constraint programming and automated planning are examples of these areas, where the behaviour of a new algorithm is measured by how it performs on these instances. Typically the efficiency of each solving method varies not only between problems, but also between instances of the same problem. Therefore, having a diverse set of instances is crucial to be able to effectively evaluate a new solving method. Current methods for automatic generation of instances for Constraint Programming problems start with a declarative model and search for instances with some desired attributes, such as hardness or size. We first explore the difficulties of adapting this approach to generate instances starting from problem specifications written in PDDL, the de-facto standard language of the automated planning community. We then propose a new approach where the whole planning problem description is modelled using Essence, an abstract modelling language that allows expressing high-level structures without committing to a particular low level representation in PDDL.
Towards Portfolios of Streamlined Constraint Models: A Case Study with the Balanced Academic Curriculum Problem
Sep 21, 2020

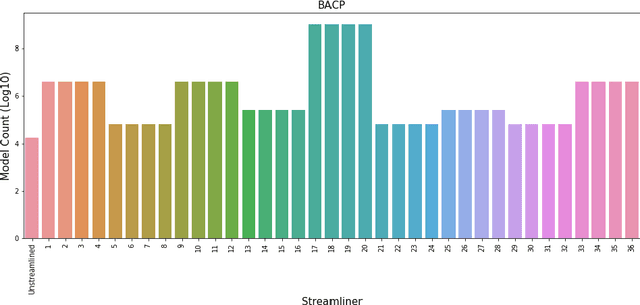
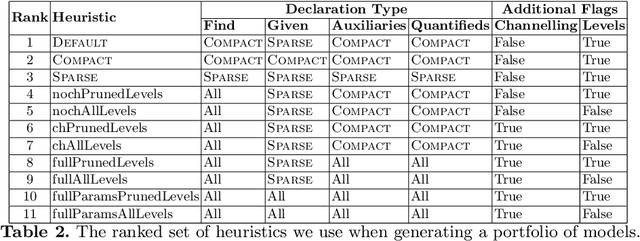
Augmenting a base constraint model with additional constraints can strengthen the inferences made by a solver and therefore reduce search effort. We focus on the automatic addition of streamliner constraints, derived from the types present in an abstract Essence specification of a problem class of interest, which trade completeness for potentially very significant reduction in search. The refinement of streamlined Essence specifications into constraint models suitable for input to constraint solvers gives rise to a large number of modelling choices in addition to those required for the base Essence specification. Previous automated streamlining approaches have been limited in evaluating only a single default model for each streamlined specification. In this paper we explore the effect of model selection in the context of streamlined specifications. We propose a new best-first search method that generates a portfolio of Pareto Optimal streamliner-model combinations by evaluating for each streamliner a portfolio of models to search and explore the variability in performance and find the optimal model. Various forms of racing are utilised to constrain the computational cost of training.
Towards Improving Solution Dominance with Incomparability Conditions: A case-study using Generator Itemset Mining
Oct 01, 2019

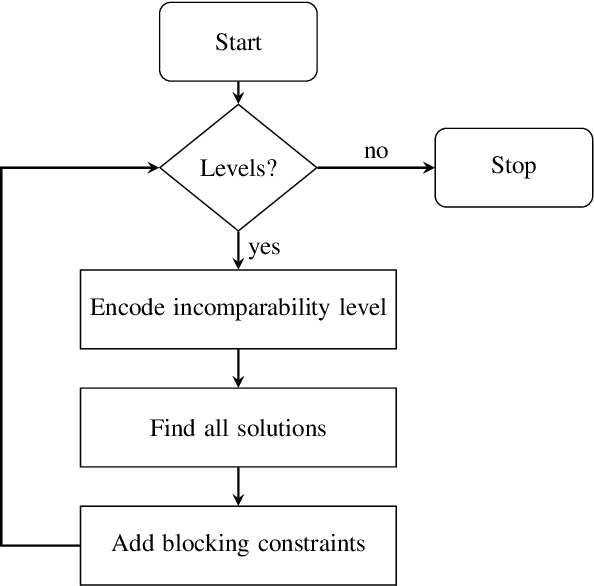
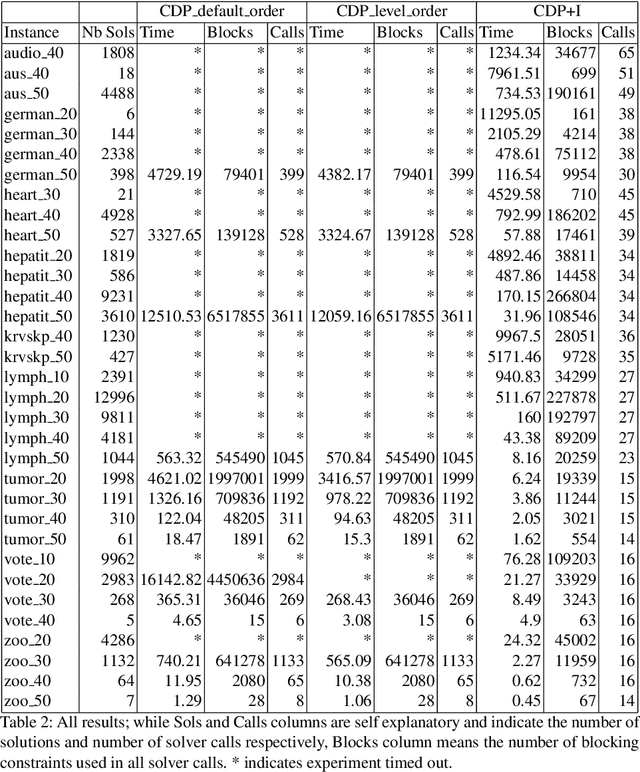
Finding interesting patterns is a challenging task in data mining. Constraint based mining is a well-known approach to this, and one for which constraint programming has been shown to be a well-suited and generic framework. Dominance programming has been proposed as an extension that can capture an even wider class of constraint-based mining problems, by allowing to compare relations between patterns. In this paper, in addition to specifying a dominance relation, we introduce the ability to specify an incomparability condition. Using these two concepts we devise a generic framework that can do a batch-wise search that avoids checking incomparable solutions. We extend the ESSENCE language and underlying modelling pipeline to support this. We use generator itemset mining problem as a test case and give a declarative specification for that. We also present preliminary experimental results on this specific problem class with a CP solver backend to show that using the incomparability condition during search can improve the efficiency of dominance programming and reduces the need for post-processing to filter dominated solutions.