 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Sliding Window Attention
Papers and Code
Training Transformers for Mesh-Based Simulations
Aug 25, 2025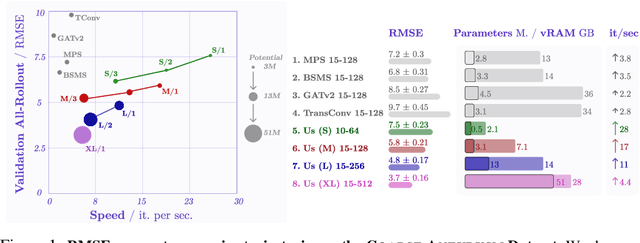
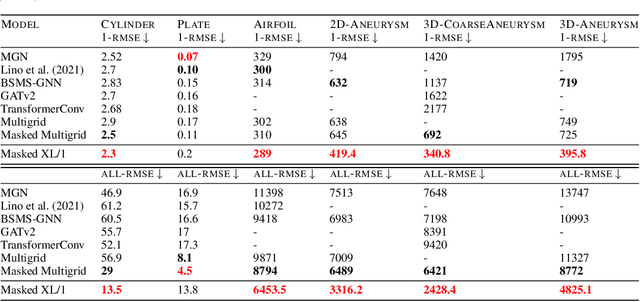
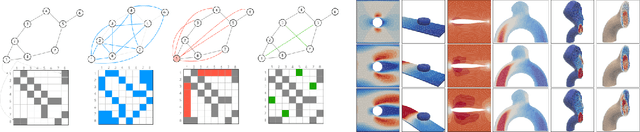
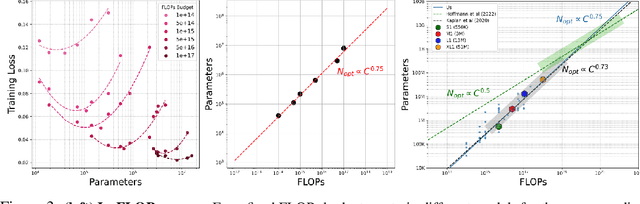
Simulating physics using Graph Neural Networks (GNNs) is predominantly driven by message-passing architectures, which face challenges in scaling and efficiency, particularly in handling large, complex meshes. These architectures have inspired numerous enhancements, including multigrid approaches and $K$-hop aggregation (using neighbours of distance $K$), yet they often introduce significant complexity and suffer from limited in-depth investigations. In response to these challenges, we propose a novel Graph Transformer architecture that leverages the adjacency matrix as an attention mask. The proposed approach incorporates innovative augmentations, including Dilated Sliding Windows and Global Attention, to extend receptive fields without sacrificing computational efficiency. Through extensive experimentation, we evaluate model size, adjacency matrix augmentations, positional encoding and $K$-hop configurations using challenging 3D computational fluid dynamics (CFD) datasets. We also train over 60 models to find a scaling law between training FLOPs and parameters. The introduced models demonstrate remarkable scalability, performing on meshes with up to 300k nodes and 3 million edges. Notably, the smallest model achieves parity with MeshGraphNet while being $7\times$ faster and $6\times$ smaller. The largest model surpasses the previous state-of-the-art by $38.8$\% on average and outperforms MeshGraphNet by $52$\% on the all-rollout RMSE, while having a similar training speed. Code and datasets are available at https://github.com/DonsetPG/graph-physics.
DiNAT-IR: Exploring Dilated Neighborhood Attention for High-Quality Image Restoration
Jul 23, 2025Transformers, with their self-attention mechanisms for modeling long-range dependencies, have become a dominant paradigm in image restoration tasks. However, the high computational cost of self-attention limits scalability to high-resolution images, making efficiency-quality trade-offs a key research focus. To address this, Restormer employs channel-wise self-attention, which computes attention across channels instead of spatial dimensions. While effective, this approach may overlook localized artifacts that are crucial for high-quality image restoration. To bridge this gap, we explore Dilated Neighborhood Attention (DiNA) as a promising alternative, inspired by its success in high-level vision tasks. DiNA balances global context and local precision by integrating sliding-window attention with mixed dilation factors, effectively expanding the receptive field without excessive overhead. However, our preliminary experiments indicate that directly applying this global-local design to the classic deblurring task hinders accurate visual restoration, primarily due to the constrained global context understanding within local attention. To address this, we introduce a channel-aware module that complements local attention, effectively integrating global context without sacrificing pixel-level precision. The proposed DiNAT-IR, a Transformer-based architecture specifically designed for image restoration, achieves competitive results across multiple benchmarks, offering a high-quality solution for diverse low-level computer vision problems.
Faster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level
Mar 07, 2024



Neighborhood attention reduces the cost of self attention by restricting each token's attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision latency compared to existing naive kernels for 1-D and 2-D neighborhood attention respectively. We find certain inherent inefficiencies in all unfused neighborhood attention kernels that bound their performance and lower-precision scalability. We also developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision latency. We observe that our fused kernels successfully circumvent some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 496% and 113% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1607% and 581% in 1-D and 2-D problems respectively.
Transformer Working Memory Enables Regular Language Reasoning and Natural Language Length Extrapolation
May 05, 2023



Unlike recurrent models, conventional wisdom has it that Transformers cannot perfectly model regular languages. Inspired by the notion of working memory, we propose a new Transformer variant named RegularGPT. With its novel combination of Weight-Sharing, Adaptive-Depth, and Sliding-Dilated-Attention, RegularGPT constructs working memory along the depth dimension, thereby enabling efficient and successful modeling of regular languages such as PARITY. We further test RegularGPT on the task of natural language length extrapolation and surprisingly find that it rediscovers the local windowed attention effect deemed necessary in prior work for length extrapolation.
DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition
Feb 03, 2023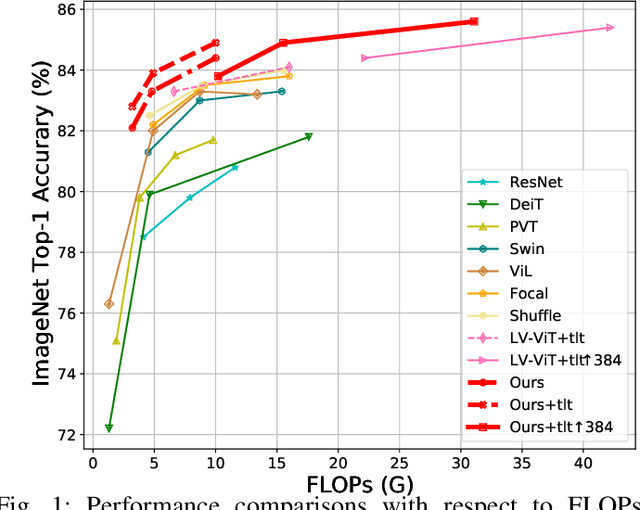

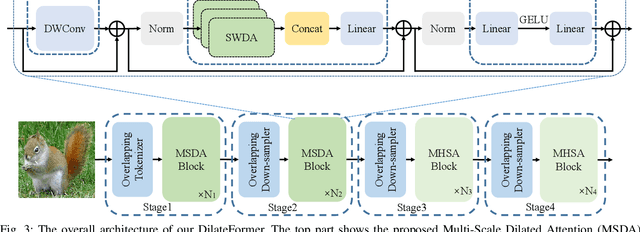
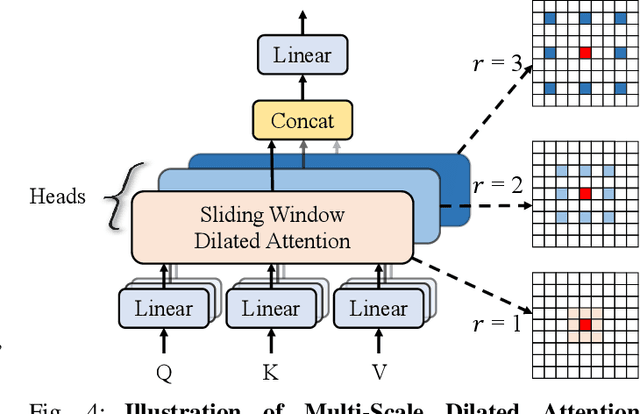
As a de facto solution, the vanilla Vision Transformers (ViTs) are encouraged to model long-range dependencies between arbitrary image patches while the global attended receptive field leads to quadratic computational cost. Another branch of Vision Transformers exploits local attention inspired by CNNs, which only models the interactions between patches in small neighborhoods. Although such a solution reduces the computational cost, it naturally suffers from small attended receptive fields, which may limit the performance. In this work, we explore effective Vision Transformers to pursue a preferable trade-off between the computational complexity and size of the attended receptive field. By analyzing the patch interaction of global attention in ViTs, we observe two key properties in the shallow layers, namely locality and sparsity, indicating the redundancy of global dependency modeling in shallow layers of ViTs. Accordingly, we propose Multi-Scale Dilated Attention (MSDA) to model local and sparse patch interaction within the sliding window. With a pyramid architecture, we construct a Multi-Scale Dilated Transformer (DilateFormer) by stacking MSDA blocks at low-level stages and global multi-head self-attention blocks at high-level stages. Our experiment results show that our DilateFormer achieves state-of-the-art performance on various vision tasks. On ImageNet-1K classification task, DilateFormer achieves comparable performance with 70% fewer FLOPs compared with existing state-of-the-art models. Our DilateFormer-Base achieves 85.6% top-1 accuracy on ImageNet-1K classification task, 53.5% box mAP/46.1% mask mAP on COCO object detection/instance segmentation task and 51.1% MS mIoU on ADE20K semantic segmentation task.
Dilated Neighborhood Attention Transformer
Sep 29, 2022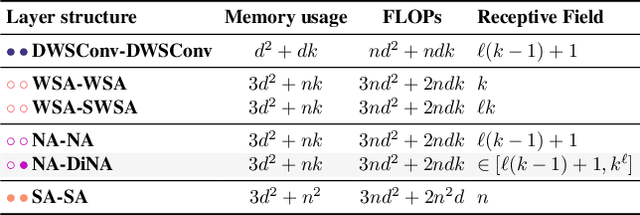
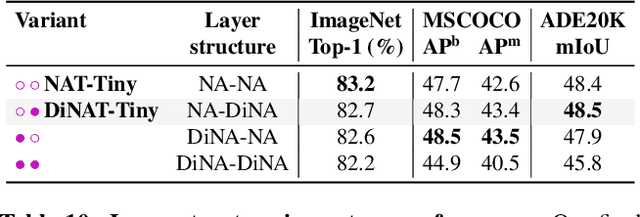
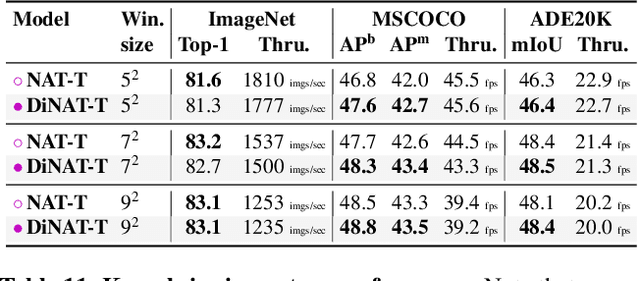
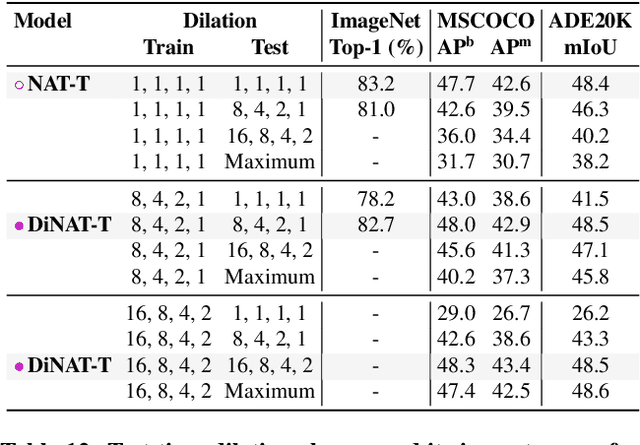
Transformers are quickly becoming one of the most heavily applied deep learning architectures across modalities, domains, and tasks. In vision, on top of ongoing efforts into plain transformers, hierarchical transformers have also gained significant attention, thanks to their performance and easy integration into existing frameworks. These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA) or Swin Transformer's Shifted Window Self Attention. While effective at reducing self attention's quadratic complexity, local attention weakens two of the most desirable properties of self attention: long range inter-dependency modeling, and global receptive field. In this paper, we introduce Dilated Neighborhood Attention (DiNA), a natural, flexible and efficient extension to NA that can capture more global context and expand receptive fields exponentially at no additional cost. NA's local attention and DiNA's sparse global attention complement each other, and therefore we introduce Dilated Neighborhood Attention Transformer (DiNAT), a new hierarchical vision transformer built upon both. DiNAT variants enjoy significant improvements over attention-based baselines such as NAT and Swin, as well as modern convolutional baseline ConvNeXt. Our Large model is ahead of its Swin counterpart by 1.5% box AP in COCO object detection, 1.3% mask AP in COCO instance segmentation, and 1.1% mIoU in ADE20K semantic segmentation, and faster in throughput. We believe combinations of NA and DiNA have the potential to empower various tasks beyond those presented in this paper. To support and encourage research in this direction, in vision and beyond, we open-source our project at: https://github.com/SHI-Labs/Neighborhood-Attention-Transformer.
BumbleBee: A Transformer for Music
Jul 07, 2021
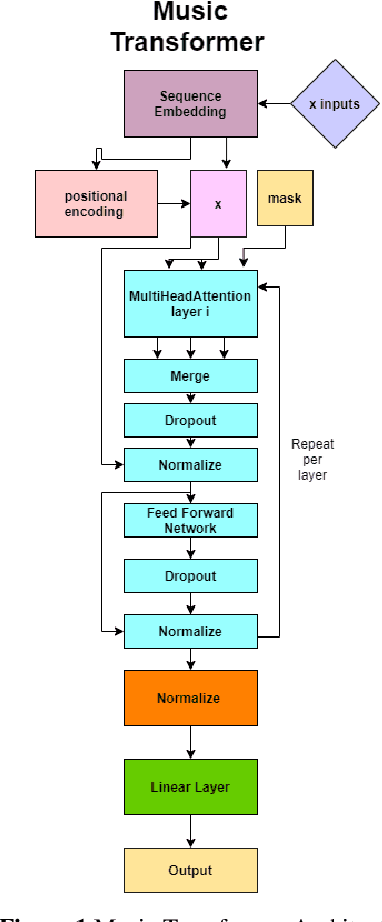

We will introduce BumbleBee, a transformer model that will generate MIDI music data . We will tackle the issue of transformers applied to long sequences by implementing a longformer generative model that uses dilating sliding windows to compute the attention layers. We will compare our results to that of the music transformer and Long-Short term memory (LSTM) to benchmark our results. This analysis will be performed using piano MIDI files, in particular , the JSB Chorales dataset that has already been used for other research works (Huang et al., 2018)