 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Mobile-Former: Video Recognition with Efficient Global Spatial-temporal Modeling
Paper and Code
Aug 25, 2022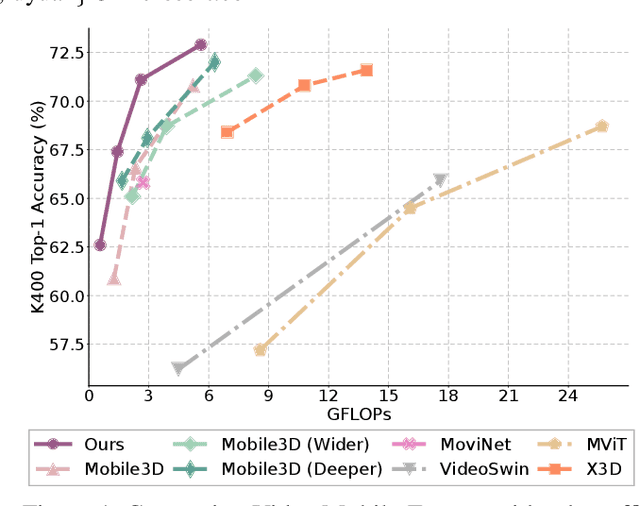
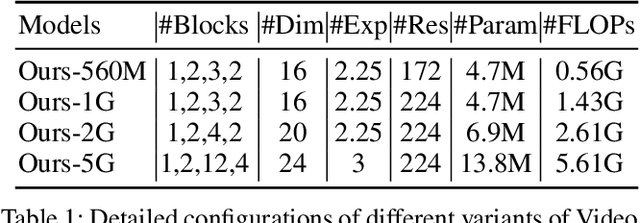
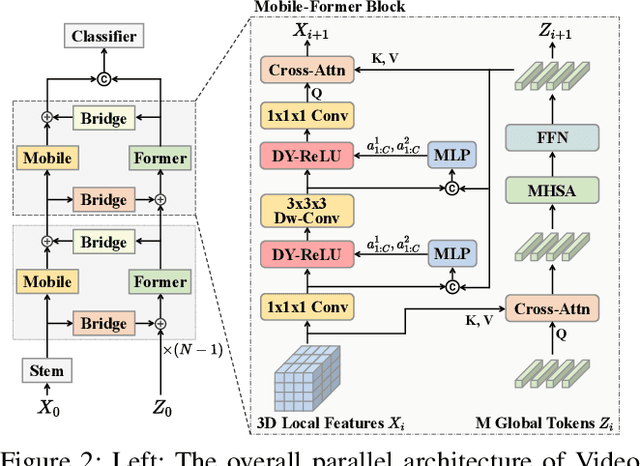
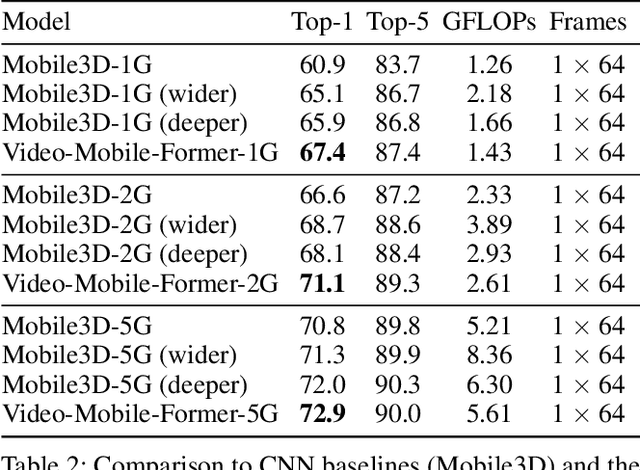
Transformer-based models have achieved top performance on major video recognition benchmarks. Benefiting from the self-attention mechanism, these models show stronger ability of modeling long-range dependencies compared to CNN-based models. However, significant computation overheads, resulted from the quadratic complexity of self-attention on top of a tremendous number of tokens, limit the use of existing video transformers in applications with limited resources like mobile devices. In this paper, we extend Mobile-Former to Video Mobile-Former, which decouples the video architecture into a lightweight 3D-CNNs for local context modeling and a Transformer modules for global interaction modeling in a parallel fashion. To avoid significant computational cost incurred by computing self-attention between the large number of local patches in videos, we propose to use very few global tokens (e.g., 6) for a whole video in Transformers to exchange information with 3D-CNNs with a cross-attention mechanism. Through efficient global spatial-temporal modeling, Video Mobile-Former significantly improves the video recognition performance of alternative lightweight baselines, and outperforms other efficient CNN-based models at the low FLOP regime from 500M to 6G total FLOPs on various video recognition tasks. It is worth noting that Video Mobile-Former is the first Transformer-based video model which constrains the computational budget within 1G FLOPs.