 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinity Vision Transformer
Paper and Code
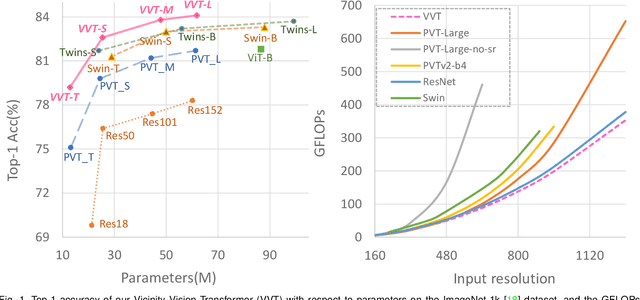


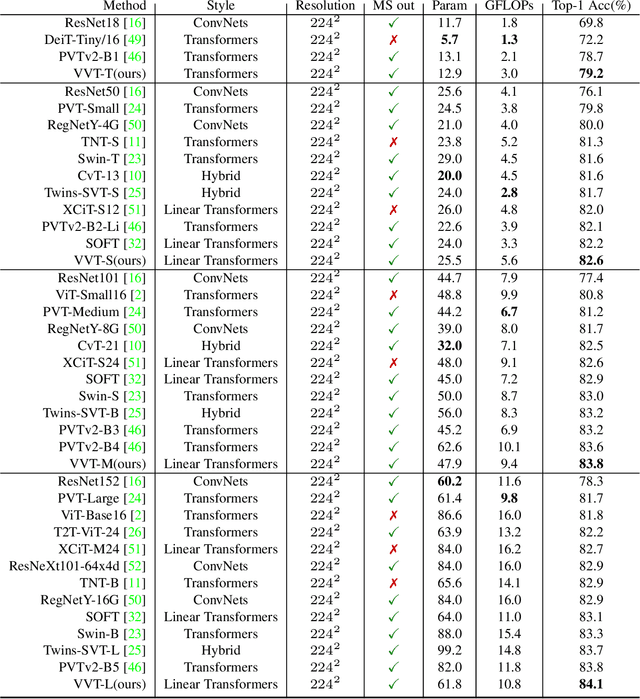
Vision transformers have shown great success on numerous computer vision tasks. However, its central component, softmax attention, prohibits vision transformers from scaling up to high-resolution images, due to both the computational complexity and memory footprint being quadratic. Although linear attention was introduced in natural language processing (NLP) tasks to mitigate a similar issue, directly applying existing linear attention to vision transformers may not lead to satisfactory results. We investigate this problem and find that computer vision tasks focus more on local information compared with NLP tasks. Based on this observation, we present a Vicinity Attention that introduces a locality bias to vision transformers with linear complexity. Specifically, for each image patch, we adjust its attention weight based on its 2D Manhattan distance measured by its neighbouring patches. In this case, the neighbouring patches will receive stronger attention than far-away patches. Moreover, since our Vicinity Attention requires the token length to be much larger than the feature dimension to show its efficiency advantages, we further propose a new Vicinity Vision Transformer (VVT) structure to reduce the feature dimension without degenerating the accuracy. We perform extensive experiments on the CIFAR100, ImageNet1K, and ADE20K datasets to validate the effectiveness of our method. Our method has a slower growth rate of GFlops than previous transformer-based and convolution-based networks when the input resolution increases. In particular, our approach achieves state-of-the-art image classification accuracy with 50% fewer parameters than previous methods.