 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems
Paper and Code
Jul 24, 2019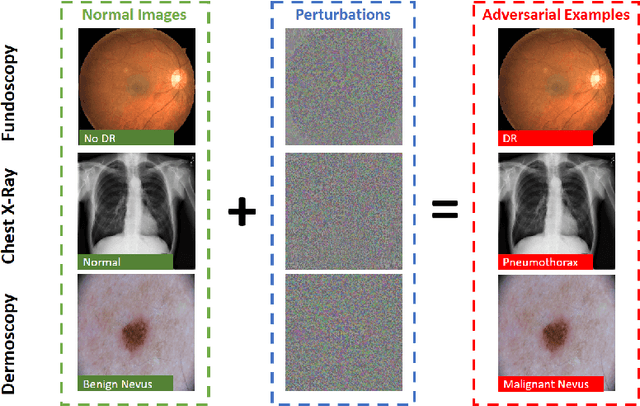
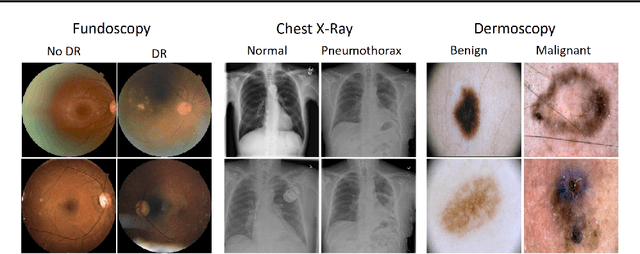
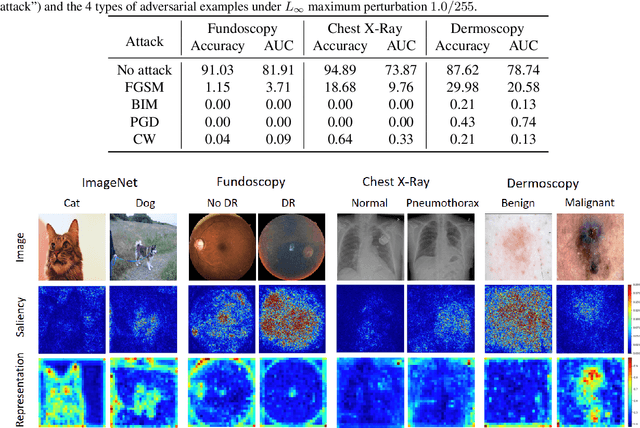
Deep neural networks (DNNs) have become popular for medical image analysis tasks like cancer diagnosis and lesion detection. However, a recent study demonstrates that medical deep learning systems can be compromised by carefully-engineered adversarial examples/attacks, i.e., small imperceptible perturbations can fool DNNs to predict incorrectly. This raises safety concerns about the deployment of deep learning systems in clinical settings. In this paper, we provide a deeper understanding of adversarial examples in the context of medical images. We find that medical DNN models can be more vulnerable to adversarial attacks compared to natural ones from three different viewpoints: 1) medical image DNNs that have only a few classes are generally easier to be attacked; 2) the complex biological textures of medical images may lead to more vulnerable regions; and most importantly, 3) state-of-the-art deep networks designed for large-scale natural image processing can be overparameterized for medical imaging tasks and result in high vulnerability to adversarial attacks. Surprisingly, we also find that medical adversarial attacks can be easily detected, i.e., simple detectors can achieve over 98% detection AUCs against state-of-the-art attacks, due to their fundamental feature difference from normal examples. We show this is because adversarial attacks tend to attack a wide spread area outside the pathological regions, which results in deep features that are fundamentally different and easily separable from normal features. We believe these findings may be a useful basis to approach the design of secure medical deep learning systems.