 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream Graph Convolutional Network for Intra-oral Scanner Image Segmentation
Paper and Code
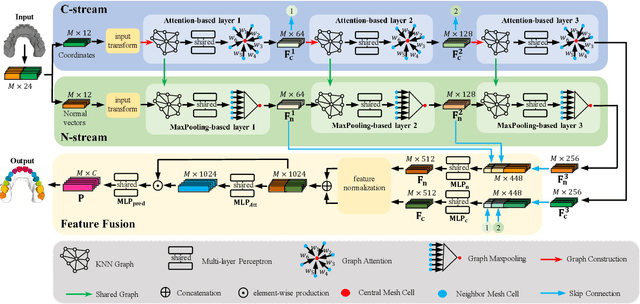
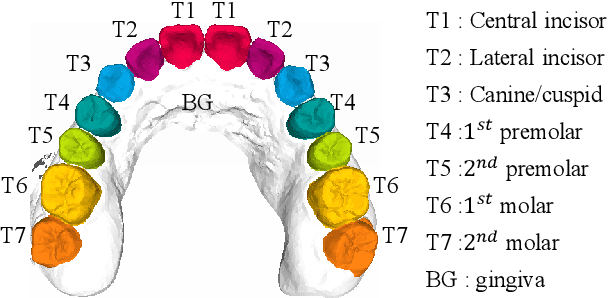
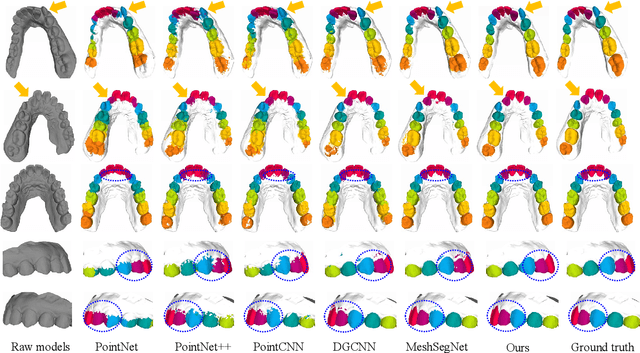
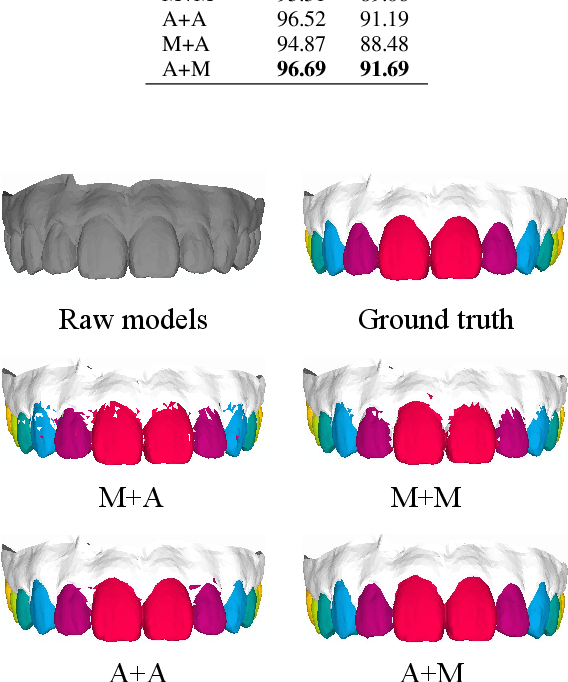
Precise segmentation of teeth from intra-oral scanner images is an essential task in computer-aided orthodontic surgical planning. The state-of-the-art deep learning-based methods often simply concatenate the raw geometric attributes (i.e., coordinates and normal vectors) of mesh cells to train a single-stream network for automatic intra-oral scanner image segmentation. However, since different raw attributes reveal completely different geometric information, the naive concatenation of different raw attributes at the (low-level) input stage may bring unnecessary confusion in describing and differentiating between mesh cells, thus hampering the learning of high-level geometric representations for the segmentation task. To address this issue, we design a two-stream graph convolutional network (i.e., TSGCN), which can effectively handle inter-view confusion between different raw attributes to more effectively fuse their complementary information and learn discriminative multi-view geometric representations. Specifically, our TSGCN adopts two input-specific graph-learning streams to extract complementary high-level geometric representations from coordinates and normal vectors, respectively. Then, these single-view representations are further fused by a self-attention module to adaptively balance the contributions of different views in learning more discriminative multi-view representations for accurate and fully automatic tooth segmentation. We have evaluated our TSGCN on a real-patient dataset of dental (mesh) models acquired by 3D intraoral scanners. Experimental results show that our TSGCN significantly outperforms state-of-the-art methods in 3D tooth (surface) segmentation. Github: https://github.com/ZhangLingMing1/TSGCNet.