 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ultra-High Performance and Energy Efficiency of Deep Learning Systems: An Algorithm-Hardware Co-Optimization Framework
Paper and Code
Feb 18, 2018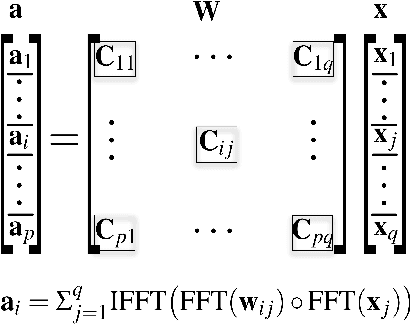
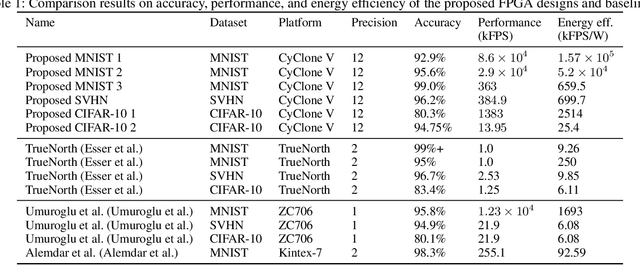
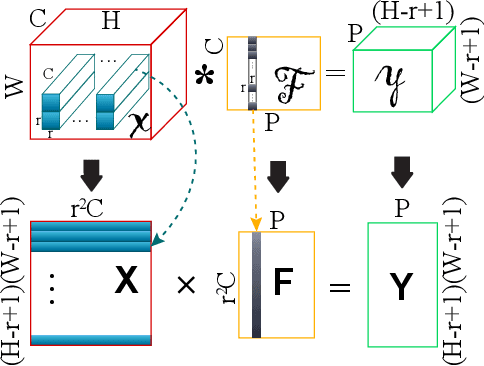

Hardware accelerations of deep learning systems have been extensively investigated in industry and academia. The aim of this paper is to achieve ultra-high energy efficiency and performance for hardware implementations of deep neural networks (DNNs). An algorithm-hardware co-optimization framework is developed, which is applicable to different DNN types, sizes, and application scenarios. The algorithm part adopts the general block-circulant matrices to achieve a fine-grained tradeoff between accuracy and compression ratio. It applies to both fully-connected and convolutional layers and contains a mathematically rigorous proof of the effectiveness of the method. The proposed algorithm reduces computational complexity per layer from O($n^2$) to O($n\log n$) and storage complexity from O($n^2$) to O($n$), both for training and inference. The hardware part consists of highly efficient Field Programmable Gate Array (FPGA)-based implementations using effective reconfiguration, batch processing, deep pipelining, resource re-using, and hierarchical control. Experimental results demonstrate that the proposed framework achieves at least 152X speedup and 71X energy efficiency gain compared with IBM TrueNorth processor under the same test accuracy. It achieves at least 31X energy efficiency gain compared with the reference FPGA-based work.