 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRT-Attack: Jailbreaking Text-to-Image Models via Random Token
Paper and Code
Aug 27, 2024
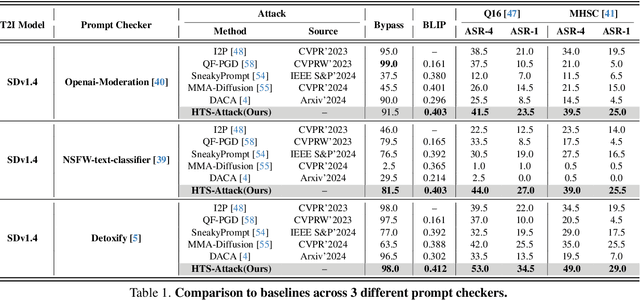


Recently, Text-to-Image(T2I) models have achieved remarkable success in image generation and editing, yet these models still have many potential issues, particularly in generating inappropriate or Not-Safe-For-Work(NSFW) content. Strengthening attacks and uncovering such vulnerabilities can advance the development of reliable and practical T2I models. Most of the previous works treat T2I models as white-box systems, using gradient optimization to generate adversarial prompts. However, accessing the model's gradient is often impossible in real-world scenarios. Moreover, existing defense methods, those using gradient masking, are designed to prevent attackers from obtaining accurate gradient information. While some black-box jailbreak attacks have been explored, these typically rely on simply replacing sensitive words, leading to suboptimal attack performance. To address this issue, we introduce a two-stage query-based black-box attack method utilizing random search. In the first stage, we establish a preliminary prompt by maximizing the semantic similarity between the adversarial and target harmful prompts. In the second stage, we use this initial prompt to refine our approach, creating a detailed adversarial prompt aimed at jailbreaking and maximizing the similarity in image features between the images generated from this prompt and those produced by the target harmful prompt. Extensive experiments validate the effectiveness of our method in attacking the latest prompt checkers, post-hoc image checkers, securely trained T2I models, and online commercial models.