 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicyGPT: Automated Analysis of Privacy Policies with Large Language Models
Paper and Code
Sep 19, 2023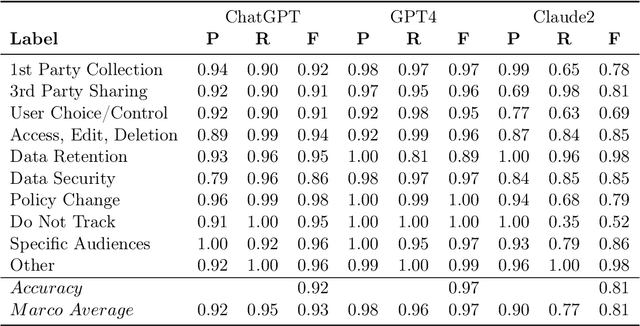
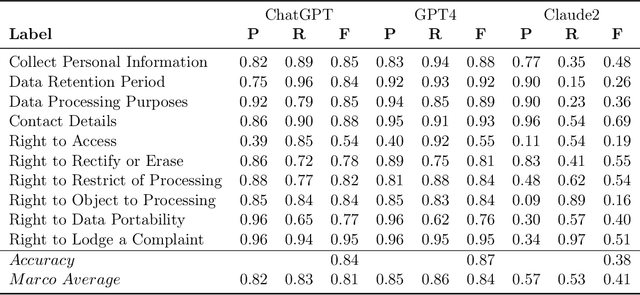
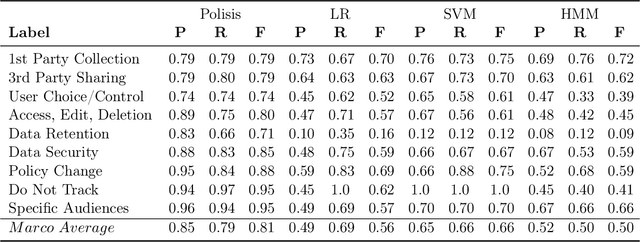
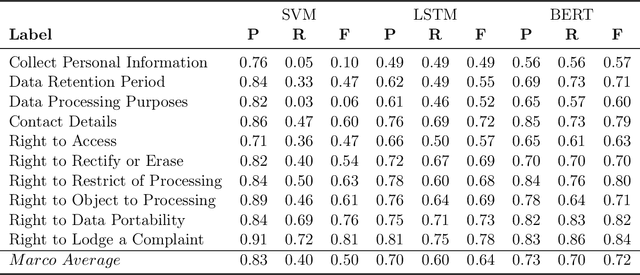
Privacy policies serve as the primary conduit through which online service providers inform users about their data collection and usage procedures. However, in a bid to be comprehensive and mitigate legal risks, these policy documents are often quite verbose. In practical use, users tend to click the Agree button directly rather than reading them carefully. This practice exposes users to risks of privacy leakage and legal issues. Recently, the advent of Large Language Models (LLM) such as ChatGPT and GPT-4 has opened new possibilities for text analysis, especially for lengthy documents like privacy policies. In this study, we investigate a privacy policy text analysis framework PolicyGPT based on the LLM. This framework was tested using two datasets. The first dataset comprises of privacy policies from 115 websites, which were meticulously annotated by legal experts, categorizing each segment into one of 10 classes. The second dataset consists of privacy policies from 304 popular mobile applications, with each sentence manually annotated and classified into one of another 10 categories. Under zero-shot learning conditions, PolicyGPT demonstrated robust performance. For the first dataset, it achieved an accuracy rate of 97%, while for the second dataset, it attained an 87% accuracy rate, surpassing that of the baseline machine learning and neural network models.