 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMC-CLIP: Contrastive Language-Image Pre-training using Biomedical Documents
Paper and Code
Mar 13, 2023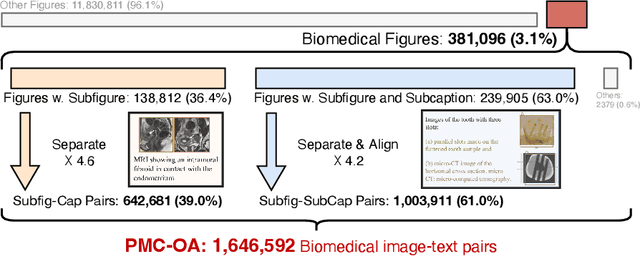
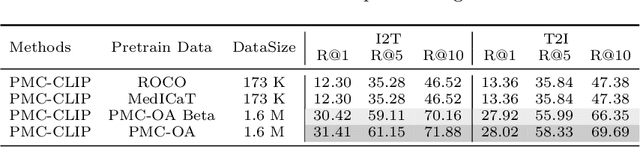
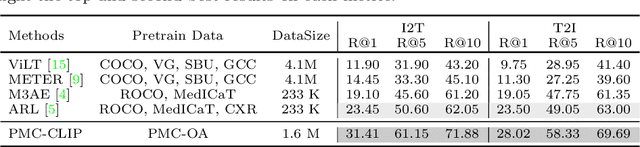
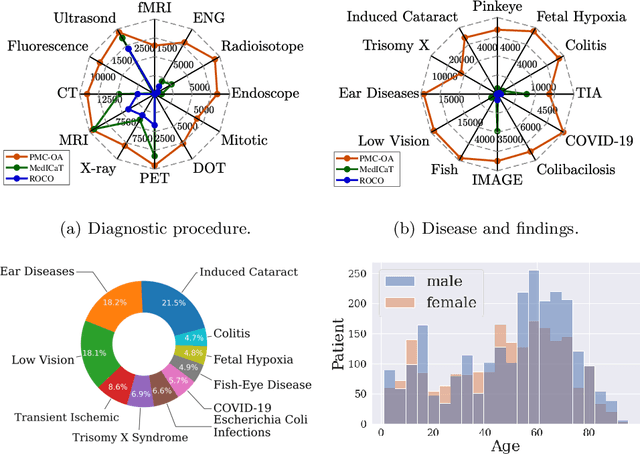
Foundation models trained on large-scale dataset gain a recent surge in CV and NLP. In contrast, development in biomedical domain lags far behind due to data scarcity. To address this issue, we build and release PMC-OA, a biomedical dataset with 1.6M image-caption pairs collected from PubMedCentral's OpenAccess subset, which is 8 times larger than before. PMC-OA covers diverse modalities or diseases, with majority of the image-caption samples aligned at finer-grained level, i.e., subfigure and subcaption. While pretraining a CLIP-style model on PMC-OA, our model named PMC-CLIP achieves state-of-the-art results on various downstream tasks, including image-text retrieval on ROCO, MedMNIST image classification, Medical VQA, i.e. +8.1% R@10 on image-text retrieval, +3.9% accuracy on image classification.