 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Low-resource Second Language Acquisition Modeling
Paper and Code
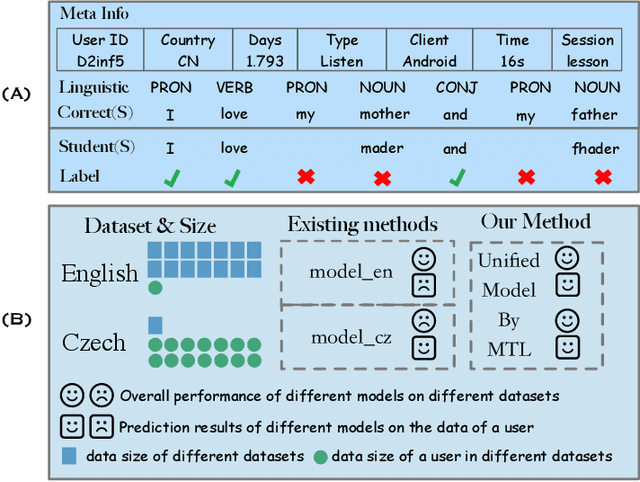

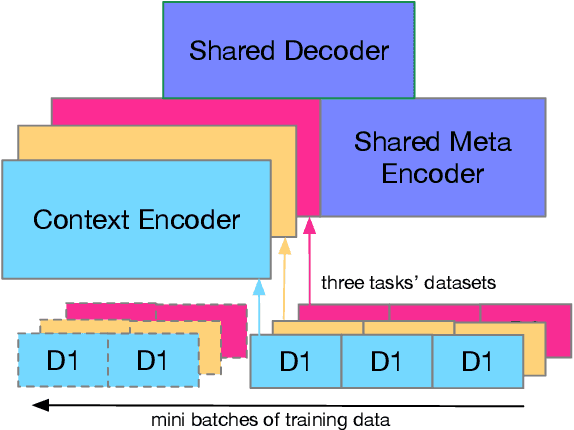
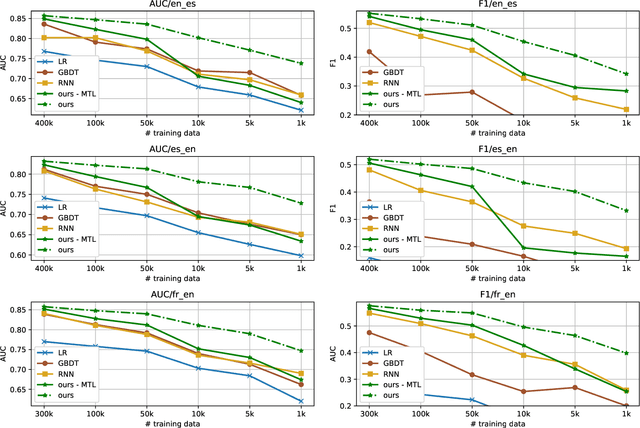
Second language acquisition (SLA) modeling is to predict whether second language learners could correctly answer the questions according to what they have learned. It is a fundamental building block of the personalized learning system and has attracted more and more attention recently. However, as far as we know, almost all existing methods cannot work well in low-resource scenarios because lacking of training data. Fortunately, there are some latent common patterns among different language-learning tasks, which gives us an opportunity to solve the low-resource SLA modeling problem. Inspired by this idea, in this paper, we propose a novel SLA modeling method, which learns the latent common patterns among different language-learning datasets by multi-task learning and are further applied to improving the prediction performance in low-resource scenarios. Extensive experiments show that the proposed method performs much better than the state-of-the-art baselines in the low-resource scenario. Meanwhile, it also obtains improvement slightly in the non-low-resource scenario.