 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Center Federated Learning
Paper and Code
Aug 21, 2021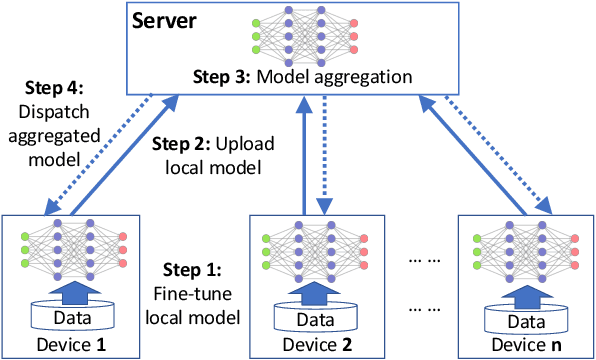

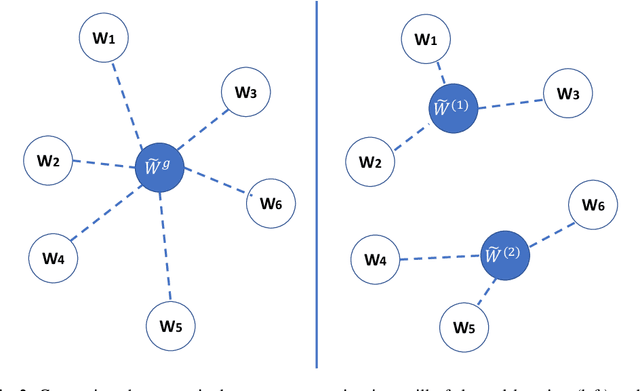
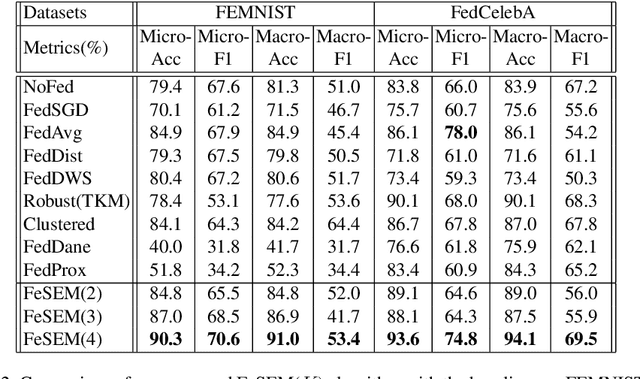
Federated learning (FL) can protect data privacy in distributed learning since it merely collects local gradients from users without access to their data. However, FL is fragile in the presence of heterogeneity that is commonly encountered in practical settings, e.g., non-IID data over different users. Existing FL approaches usually update a single global model to capture the shared knowledge of all users by aggregating their gradients, regardless of the discrepancy between their data distributions. By comparison, a mixture of multiple global models could capture the heterogeneity across various users if assigning the users to different global models (i.e., centers) in FL. To this end, we propose a novel multi-center aggregation mechanism . It learns multiple global models from data, and simultaneously derives the optimal matching between users and centers. We then formulate it as a bi-level optimization problem that can be efficiently solved by a stochastic expectation maximization (EM) algorithm. Experiments on multiple benchmark datasets of FL show that our method outperforms several popular FL competitors. The source code are open source on Github.