 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification
Paper and Code


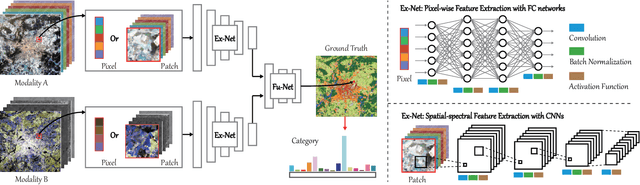

Classification and identification of the materials lying over or beneath the Earth's surface have long been a fundamental but challenging research topic in geoscience and remote sensing (RS) and have garnered a growing concern owing to the recent advancements of deep learning techniques. Although deep networks have been successfully applied in single-modality-dominated classification tasks, yet their performance inevitably meets the bottleneck in complex scenes that need to be finely classified, due to the limitation of information diversity. In this work, we provide a baseline solution to the aforementioned difficulty by developing a general multimodal deep learning (MDL) framework. In particular, we also investigate a special case of multi-modality learning (MML) -- cross-modality learning (CML) that exists widely in RS image classification applications. By focusing on "what", "where", and "how" to fuse, we show different fusion strategies as well as how to train deep networks and build the network architecture. Specifically, five fusion architectures are introduced and developed, further being unified in our MDL framework. More significantly, our framework is not only limited to pixel-wise classification tasks but also applicable to spatial information modeling with convolutional neural networks (CNNs). To validate the effectiveness and superiority of the MDL framework, extensive experiments related to the settings of MML and CML are conducted on two different multimodal RS datasets. Furthermore, the codes and datasets will be available at https://github.com/danfenghong/IEEE_TGRS_MDL-RS, contributing to the RS community.