 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation
Paper and Code
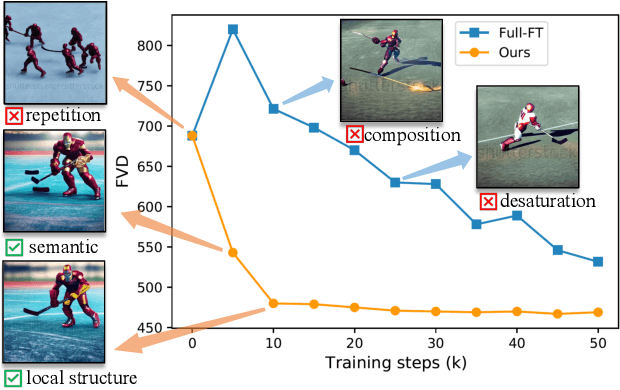
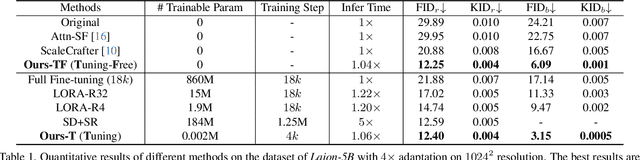
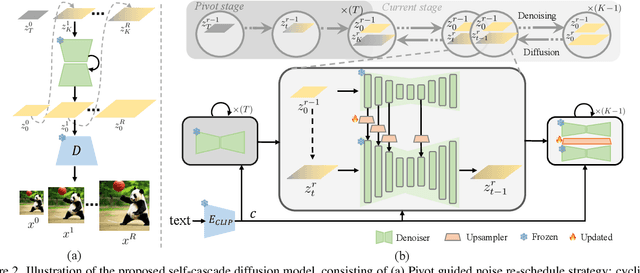
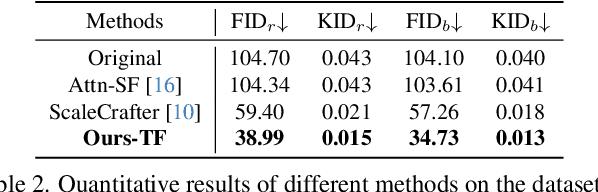
Diffusion models have proven to be highly effective in image and video generation; however, they still face composition challenges when generating images of varying sizes due to single-scale training data. Adapting large pre-trained diffusion models for higher resolution demands substantial computational and optimization resources, yet achieving a generation capability comparable to low-resolution models remains elusive. This paper proposes a novel self-cascade diffusion model that leverages the rich knowledge gained from a well-trained low-resolution model for rapid adaptation to higher-resolution image and video generation, employing either tuning-free or cheap upsampler tuning paradigms. Integrating a sequence of multi-scale upsampler modules, the self-cascade diffusion model can efficiently adapt to a higher resolution, preserving the original composition and generation capabilities. We further propose a pivot-guided noise re-schedule strategy to speed up the inference process and improve local structural details. Compared to full fine-tuning, our approach achieves a 5X training speed-up and requires only an additional 0.002M tuning parameters. Extensive experiments demonstrate that our approach can quickly adapt to higher resolution image and video synthesis by fine-tuning for just 10k steps, with virtually no additional inference time.