 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Symmetry: Meta-Reinforcement Learning with Symmetric Data and Language Instructions
Paper and Code
Sep 21, 2022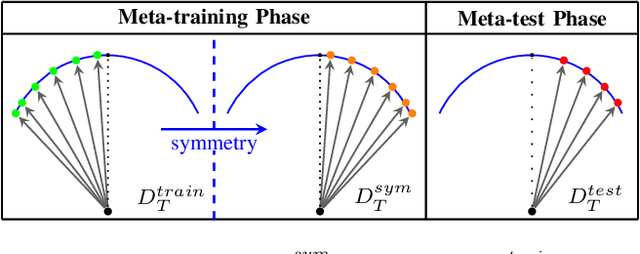
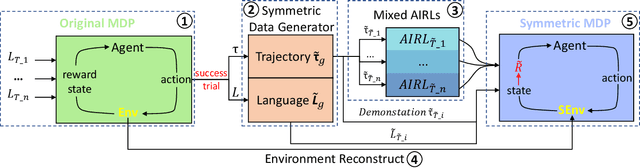
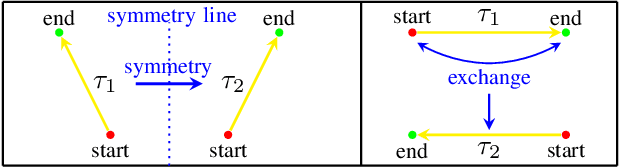
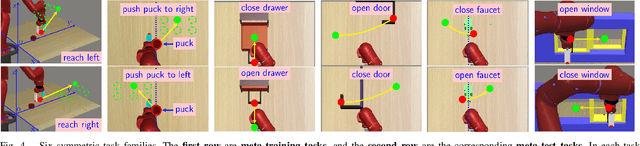
Meta-reinforcement learning (meta-RL) is a promising approach that enables the agent to learn new tasks quickly. However, most meta-RL algorithms show poor generalization in multiple-task scenarios due to the insufficient task information provided only by rewards. Language-conditioned meta-RL improves the generalization by matching language instructions and the agent's behaviors. Learning from symmetry is an important form of human learning, therefore, combining symmetry and language instructions into meta-RL can help improve the algorithm's generalization and learning efficiency. We thus propose a dual-MDP meta-reinforcement learning method that enables learning new tasks efficiently with symmetric data and language instructions. We evaluate our method in multiple challenging manipulation tasks, and experimental results show our method can greatly improve the generalization and efficiency of meta-reinforcement learning.