 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Semantics and Neighborhood Information with Graph-Driven Generative Models for Document Retrieval
Paper and Code
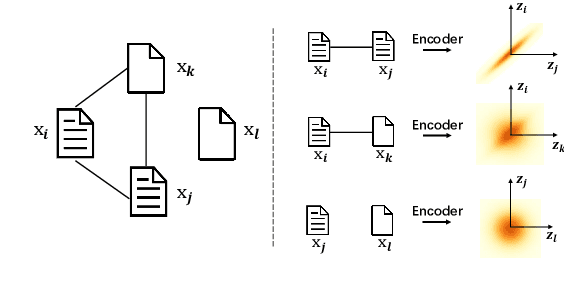
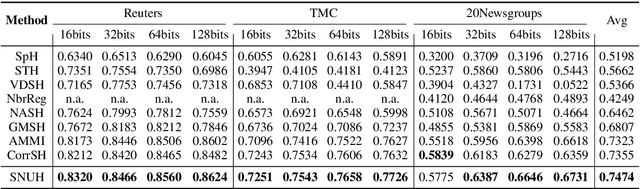
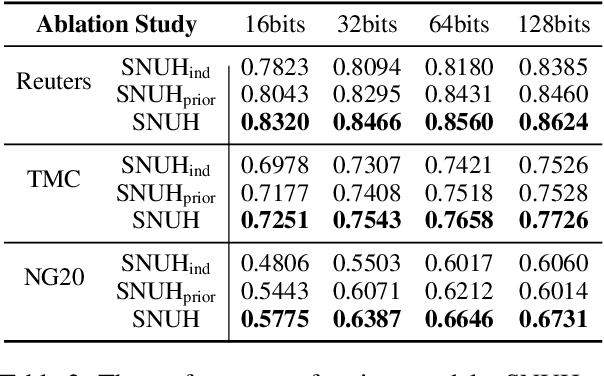
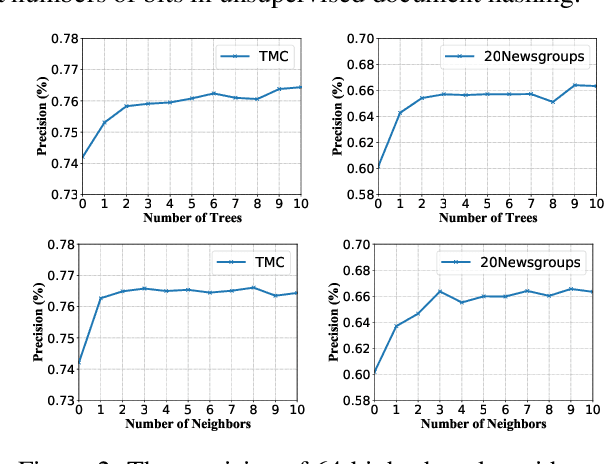
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.\